 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Geometric Problem Solving: A Comprehensive Benchmark for Multimodal Model Evaluation
Paper and Code
Apr 07, 2024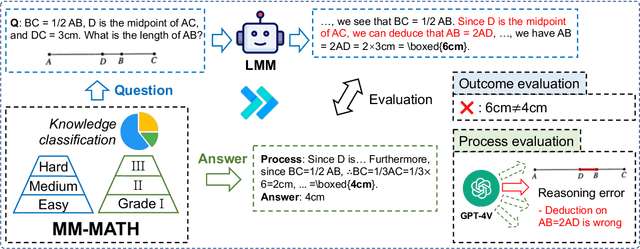

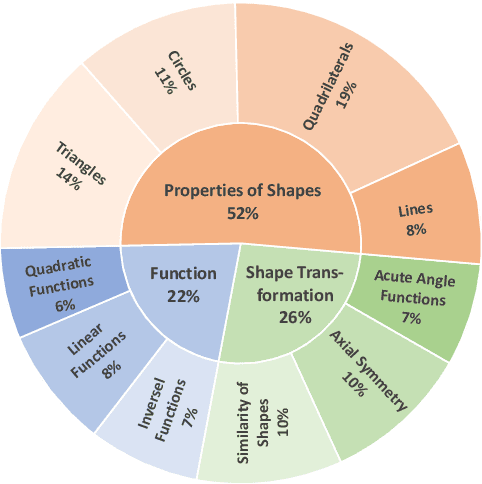
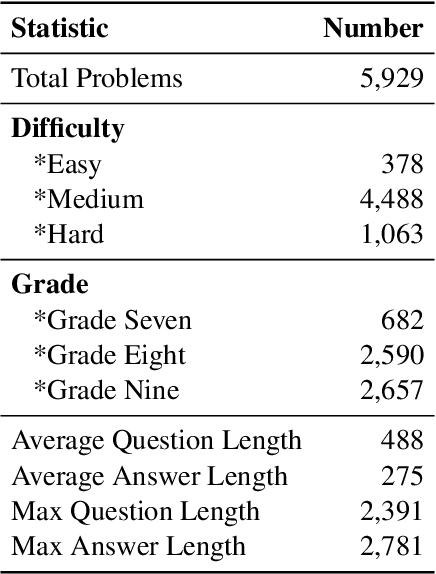
In this work, we present the MM-MATH dataset, a novel benchmark developed to rigorously evaluate the performance of advanced large language and multimodal models - including but not limited to GPT-4, GPT-4V, and Claude - within the domain of geometric computation. This dataset comprises 5,929 meticulously crafted geometric problems, each paired with a corresponding image, aimed at mirroring the complexity and requirements typical of ninth-grade mathematics. The motivation behind MM-MATH stems from the burgeoning interest and significant strides in multimodal technology, which necessitates a paradigm shift in assessment methodologies from mere outcome analysis to a more holistic evaluation encompassing reasoning and procedural correctness. Despite impressive gains in various benchmark performances, our analysis uncovers a persistent and notable deficiency in these models' ability to parse and interpret geometric information accurately from images, accounting for over 60% of observed errors. By deploying a dual-focused evaluation approach, examining both the end results and the underlying problem-solving processes, we unearthed a marked discrepancy between the capabilities of current multimodal models and human-level proficiency. The introduction of MM-MATH represents a tripartite contribution to the field: it not only serves as a comprehensive and challenging benchmark for assessing geometric problem-solving prowess but also illuminates critical gaps in textual and visual comprehension that current models exhibit. Through this endeavor, we aspire to catalyze further research and development aimed at bridging these gaps, thereby advancing the state of multimodal model capabilities to new heights.