 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArXiv-to-Model: A Practical Study of Scientific LM Training
Feb 19, 2026While frontier large language models demonstrate strong reasoning and mathematical capabilities, the practical process of training domain-specialized scientific language models from raw sources remains under-documented. In this work, we present a detailed case study of training a 1.36B-parameter scientific language model directly from raw arXiv LaTeX sources spanning mathematics, computer science, and theoretical physics. We describe an end-to-end pipeline covering metadata filtering, archive validation, LaTeX extraction, text normalization, domain-aware tokenization, and dense transformer training under constrained compute (2xA100 GPUs). Through 24 experimental runs, we analyze training stability, scaling behavior, data yield losses, and infrastructure bottlenecks. Our findings highlight how preprocessing decisions significantly affect usable token volume, how tokenization impacts symbolic stability, and how storage and I/O constraints can rival compute as limiting factors. We further analyze convergence dynamics and show stable training behavior in a data-rich regime (52B pretraining tokens). Rather than proposing a novel architecture, this work provides an engineering-grounded, transparent account of training a small scientific language model from scratch. We hope these insights support researchers operating under moderate compute budgets who seek to build domain-specialized models.
Mitigating Instance-Dependent Label Noise: Integrating Self-Supervised Pretraining with Pseudo-Label Refinement
Dec 06, 2024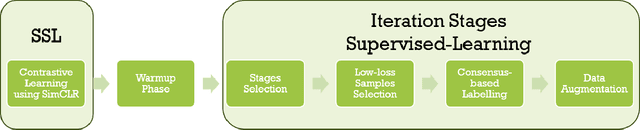


Deep learning models rely heavily on large volumes of labeled data to achieve high performance. However, real-world datasets often contain noisy labels due to human error, ambiguity, or resource constraints during the annotation process. Instance-dependent label noise (IDN), where the probability of a label being corrupted depends on the input features, poses a significant challenge because it is more prevalent and harder to address than instance-independent noise. In this paper, we propose a novel hybrid framework that combines self-supervised learning using SimCLR with iterative pseudo-label refinement to mitigate the effects of IDN. The self-supervised pre-training phase enables the model to learn robust feature representations without relying on potentially noisy labels, establishing a noise-agnostic foundation. Subsequently, we employ an iterative training process with pseudo-label refinement, where confidently predicted samples are identified through a multistage approach and their labels are updated to improve label quality progressively. We evaluate our method on the CIFAR-10 and CIFAR-100 datasets augmented with synthetic instance-dependent noise at varying noise levels. Experimental results demonstrate that our approach significantly outperforms several state-of-the-art methods, particularly under high noise conditions, achieving notable improvements in classification accuracy and robustness. Our findings suggest that integrating self-supervised learning with iterative pseudo-label refinement offers an effective strategy for training deep neural networks on noisy datasets afflicted by instance-dependent label noise.
Root Causing Prediction Anomalies Using Explainable AI
Mar 04, 2024


This paper presents a novel application of explainable AI (XAI) for root-causing performance degradation in machine learning models that learn continuously from user engagement data. In such systems a single feature corruption can cause cascading feature, label and concept drifts. We have successfully applied this technique to improve the reliability of models used in personalized advertising. Performance degradation in such systems manifest as prediction anomalies in the models. These models are typically trained continuously using features that are produced by hundreds of real time data processing pipelines or derived from other upstream models. A failure in any of these pipelines or an instability in any of the upstream models can cause feature corruption, causing the model's predicted output to deviate from the actual output and the training data to become corrupted. The causal relationship between the features and the predicted output is complex, and root-causing is challenging due to the scale and dynamism of the system. We demonstrate how temporal shifts in the global feature importance distribution can effectively isolate the cause of a prediction anomaly, with better recall than model-to-feature correlation methods. The technique appears to be effective even when approximating the local feature importance using a simple perturbation-based method, and aggregating over a few thousand examples. We have found this technique to be a model-agnostic, cheap and effective way to monitor complex data pipelines in production and have deployed a system for continuously analyzing the global feature importance distribution of continuously trained models.
Assistant, Parrot, or Colonizing Loudspeaker? ChatGPT Metaphors for Developing Critical AI Literacies
Jan 15, 2024This study explores how discussing metaphors for AI can help build awareness of the frames that shape our understanding of AI systems, particularly large language models (LLMs) like ChatGPT. Given the pressing need to teach "critical AI literacy", discussion of metaphor provides an opportunity for inquiry and dialogue with space for nuance, playfulness, and critique. Using a collaborative autoethnographic methodology, we analyzed metaphors from a range of sources, and reflected on them individually according to seven questions, then met and discussed our interpretations. We then analyzed how our reflections contributed to the three kinds of literacies delineated in Selber's multiliteracies framework: functional, critical, and rhetorical. These allowed us to analyze questions of ethics, equity, and accessibility in relation to AI. We explored each metaphor along the dimension of whether or not it was promoting anthropomorphizing, and to what extent such metaphors imply that AI is sentient. Our findings highlight the role of metaphor reflection in fostering a nuanced understanding of AI, suggesting that our collaborative autoethnographic approach as well as the heuristic model of plotting AI metaphors on dimensions of anthropomorphism and multiliteracies, might be useful for educators and researchers in the pursuit of advancing critical AI literacy.
Noisy Text Data: Achilles' Heel of popular transformer based NLP models
Oct 07, 2021



In the last few years, the ML community has created a number of new NLP models based on transformer architecture. These models have shown great performance for various NLP tasks on benchmark datasets, often surpassing SOTA results. Buoyed with this success, one often finds industry practitioners actively experimenting with fine-tuning these models to build NLP applications for industry use cases. However, for most datasets that are used by practitioners to build industrial NLP applications, it is hard to guarantee the presence of any noise in the data. While most transformer based NLP models have performed exceedingly well in transferring the learnings from one dataset to another, it remains unclear how these models perform when fine-tuned on noisy text. We address the open question by Kumar et al. (2020) to explore the sensitivity of popular transformer based NLP models to noise in the text data. We continue working with the noise as defined by them -- spelling mistakes & typos (which are the most commonly occurring noise). We show (via experimental results) that these models perform badly on most common NLP tasks namely text classification, textual similarity, NER, question answering, text summarization on benchmark datasets. We further show that as the noise in data increases, the performance degrades. Our findings suggest that one must be vary of the presence of noise in their datasets while fine-tuning popular transformer based NLP models.
hinglishNorm -- A Corpus of Hindi-English Code Mixed Sentences for Text Normalization
Oct 18, 2020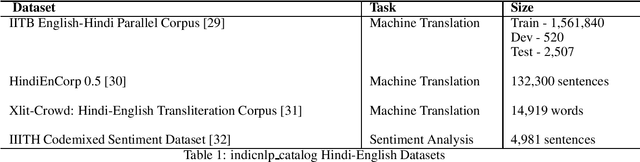
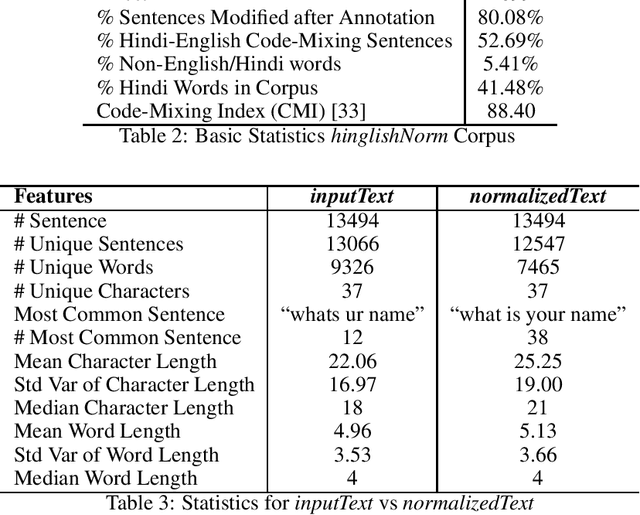
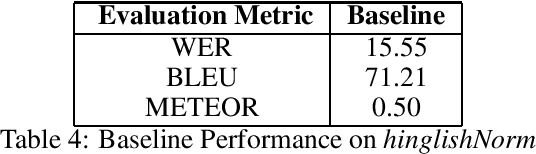
We present hinglishNorm -- a human annotated corpus of Hindi-English code-mixed sentences for text normalization task. Each sentence in the corpus is aligned to its corresponding human annotated normalized form. To the best of our knowledge, there is no corpus of Hindi-English code-mixed sentences for text normalization task that is publicly available. Our work is the first attempt in this direction. The corpus contains 13494 parallel segments. Further, we present baseline normalization results on this corpus. We obtain a Word Error Rate (WER) of 15.55, BiLingual Evaluation Understudy (BLEU) score of 71.2, and Metric for Evaluation of Translation with Explicit ORdering (METEOR) score of 0.50.
User Generated Data: Achilles' Heel of BERT
Apr 21, 2020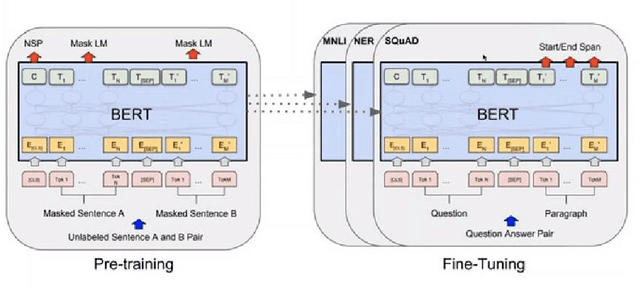

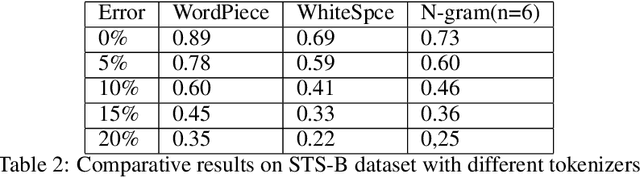
Owing to BERT's phenomenal success on various NLP tasks and benchmark datasets, industry practitioners have started to experiment with incorporating BERT to build applications to solve industry use cases. Industrial NLP applications are known to deal with much more noisy data as compared to benchmark datasets. In this work we systematically show that when the text data is noisy, there is a significant degradation in the performance of BERT. While this work is motivated from our business use case of building NLP applications for user generated text data which is known to be very noisy, our findings are applicable across various use cases in the industry. Specifically, we show that BERT's performance on fundamental tasks like sentiment analysis and textual similarity drops significantly as we introduce noise in data in the form of spelling mistakes and typos. For our experiments we use three well known datasets - IMDB movie reviews, SST-2 and STS-B to measure the performance. Further, we identify the shortcomings in the BERT pipeline that are responsible for this drop in performance.