 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVVS: Accelerating Speculative Decoding for Visual Autoregressive Generation via Partial Verification Skipping
Nov 17, 2025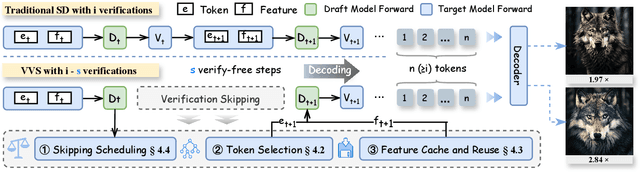
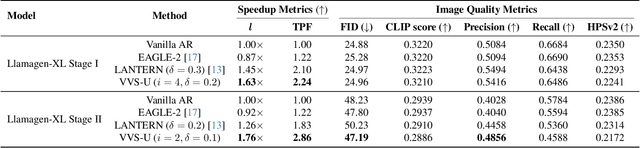
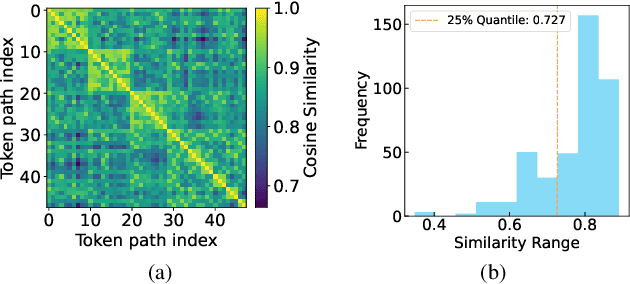
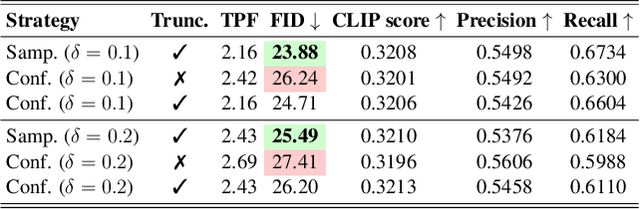
Visual autoregressive (AR) generation models have demonstrated strong potential for image generation, yet their next-token-prediction paradigm introduces considerable inference latency. Although speculative decoding (SD) has been proven effective for accelerating visual AR models, its "draft one step, then verify one step" paradigm prevents a direct reduction of the forward passes, thus restricting acceleration potential. Motivated by the visual token interchangeability, we for the first time to explore verification skipping in the SD process of visual AR model generation to explicitly cut the number of target model forward passes, thereby reducing inference latency. Based on an analysis of the drafting stage's characteristics, we observe that verification redundancy and stale feature reusability are key factors to retain generation quality and speedup for verification-free steps. Inspired by these two observations, we propose a novel SD framework VVS to accelerate visual AR generation via partial verification skipping, which integrates three complementary modules: (1) a verification-free token selector with dynamical truncation, (2) token-level feature caching and reuse, and (3) fine-grained skipped step scheduling. Consequently, VVS reduces the number of target model forward passes by a factor of $2.8\times$ relative to vanilla AR decoding while maintaining competitive generation quality, offering a superior speed-quality trade-off over conventional SD frameworks and revealing strong potential to reshape the SD paradigm.
Accelerating Parallel Diffusion Model Serving with Residual Compression
Jul 23, 2025Diffusion models produce realistic images and videos but require substantial computational resources, necessitating multi-accelerator parallelism for real-time deployment. However, parallel inference introduces significant communication overhead from exchanging large activations between devices, limiting efficiency and scalability. We present CompactFusion, a compression framework that significantly reduces communication while preserving generation quality. Our key observation is that diffusion activations exhibit strong temporal redundancy-adjacent steps produce highly similar activations, saturating bandwidth with near-duplicate data carrying little new information. To address this inefficiency, we seek a more compact representation that encodes only the essential information. CompactFusion achieves this via Residual Compression that transmits only compressed residuals (step-wise activation differences). Based on empirical analysis and theoretical justification, we show that it effectively removes redundant data, enabling substantial data reduction while maintaining high fidelity. We also integrate lightweight error feedback to prevent error accumulation. CompactFusion establishes a new paradigm for parallel diffusion inference, delivering lower latency and significantly higher generation quality than prior methods. On 4xL20, it achieves 3.0x speedup while greatly improving fidelity. It also uniquely supports communication-heavy strategies like sequence parallelism on slow networks, achieving 6.7x speedup over prior overlap-based method. CompactFusion applies broadly across diffusion models and parallel settings, and integrates easily without requiring pipeline rework. Portable implementation demonstrated on xDiT is publicly available at https://github.com/Cobalt-27/CompactFusion
DeCo-SGD: Joint Optimization of Delay Staleness and Gradient Compression Ratio for Distributed SGD
Jul 23, 2025Distributed machine learning in high end-to-end latency and low, varying bandwidth network environments undergoes severe throughput degradation. Due to its low communication requirements, distributed SGD (D-SGD) remains the mainstream optimizer in such challenging networks, but it still suffers from significant throughput reduction. To mitigate these limitations, existing approaches typically employ gradient compression and delayed aggregation to alleviate low bandwidth and high latency, respectively. To address both challenges simultaneously, these strategies are often combined, introducing a complex three-way trade-off among compression ratio, staleness (delayed synchronization steps), and model convergence rate. To achieve the balance under varying bandwidth conditions, an adaptive policy is required to dynamically adjust these parameters. Unfortunately, existing works rely on static heuristic strategies due to the lack of theoretical guidance, which prevents them from achieving this goal. This study fills in this theoretical gap by introducing a new theoretical tool, decomposing the joint optimization problem into a traditional convergence rate analysis with multiple analyzable noise terms. We are the first to reveal that staleness exponentially amplifies the negative impact of gradient compression on training performance, filling a critical gap in understanding how compressed and delayed gradients affect training. Furthermore, by integrating the convergence rate with a network-aware time minimization condition, we propose DeCo-SGD, which dynamically adjusts the compression ratio and staleness based on the real-time network condition and training task. DeCo-SGD achieves up to 5.07 and 1.37 speed-ups over D-SGD and static strategy in high-latency and low, varying bandwidth networks, respectively.
$γ$-FedHT: Stepsize-Aware Hard-Threshold Gradient Compression in Federated Learning
May 18, 2025Gradient compression can effectively alleviate communication bottlenecks in Federated Learning (FL). Contemporary state-of-the-art sparse compressors, such as Top-$k$, exhibit high computational complexity, up to $\mathcal{O}(d\log_2{k})$, where $d$ is the number of model parameters. The hard-threshold compressor, which simply transmits elements with absolute values higher than a fixed threshold, is thus proposed to reduce the complexity to $\mathcal{O}(d)$. However, the hard-threshold compression causes accuracy degradation in FL, where the datasets are non-IID and the stepsize $\gamma$ is decreasing for model convergence. The decaying stepsize reduces the updates and causes the compression ratio of the hard-threshold compression to drop rapidly to an aggressive ratio. At or below this ratio, the model accuracy has been observed to degrade severely. To address this, we propose $\gamma$-FedHT, a stepsize-aware low-cost compressor with Error-Feedback to guarantee convergence. Given that the traditional theoretical framework of FL does not consider Error-Feedback, we introduce the fundamental conversation of Error-Feedback. We prove that $\gamma$-FedHT has the convergence rate of $\mathcal{O}(\frac{1}{T})$ ($T$ representing total training iterations) under $\mu$-strongly convex cases and $\mathcal{O}(\frac{1}{\sqrt{T}})$ under non-convex cases, \textit{same as FedAVG}. Extensive experiments demonstrate that $\gamma$-FedHT improves accuracy by up to $7.42\%$ over Top-$k$ under equal communication traffic on various non-IID image datasets.
MesonGS: Post-training Compression of 3D Gaussians via Efficient Attribute Transformation
Sep 15, 2024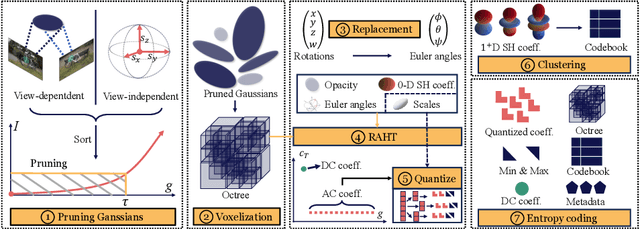
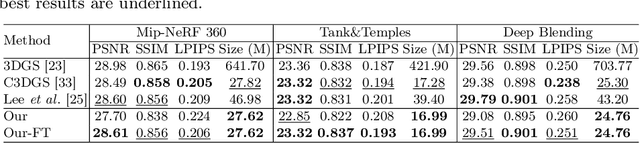
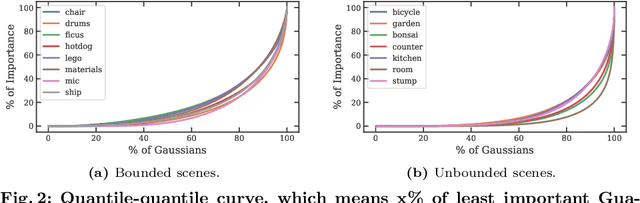
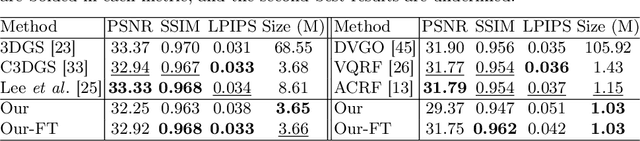
3D Gaussian Splatting demonstrates excellent quality and speed in novel view synthesis. Nevertheless, the huge file size of the 3D Gaussians presents challenges for transmission and storage. Current works design compact models to replace the substantial volume and attributes of 3D Gaussians, along with intensive training to distill information. These endeavors demand considerable training time, presenting formidable hurdles for practical deployment. To this end, we propose MesonGS, a codec for post-training compression of 3D Gaussians. Initially, we introduce a measurement criterion that considers both view-dependent and view-independent factors to assess the impact of each Gaussian point on the rendering output, enabling the removal of insignificant points. Subsequently, we decrease the entropy of attributes through two transformations that complement subsequent entropy coding techniques to enhance the file compression rate. More specifically, we first replace rotation quaternions with Euler angles; then, we apply region adaptive hierarchical transform to key attributes to reduce entropy. Lastly, we adopt finer-grained quantization to avoid excessive information loss. Moreover, a well-crafted finetune scheme is devised to restore quality. Extensive experiments demonstrate that MesonGS significantly reduces the size of 3D Gaussians while preserving competitive quality.
A Joint Approach to Local Updating and Gradient Compression for Efficient Asynchronous Federated Learning
Jul 06, 2024



Asynchronous Federated Learning (AFL) confronts inherent challenges arising from the heterogeneity of devices (e.g., their computation capacities) and low-bandwidth environments, both potentially causing stale model updates (e.g., local gradients) for global aggregation. Traditional approaches mitigating the staleness of updates typically focus on either adjusting the local updating or gradient compression, but not both. Recognizing this gap, we introduce a novel approach that synergizes local updating with gradient compression. Our research begins by examining the interplay between local updating frequency and gradient compression rate, and their collective impact on convergence speed. The theoretical upper bound shows that the local updating frequency and gradient compression rate of each device are jointly determined by its computing power, communication capabilities and other factors. Building on this foundation, we propose an AFL framework called FedLuck that adaptively optimizes both local update frequency and gradient compression rates. Experiments on image classification and speech recognization show that FedLuck reduces communication consumption by 56% and training time by 55% on average, achieving competitive performance in heterogeneous and low-bandwidth scenarios compared to the baselines.
Retraining-free Model Quantization via One-Shot Weight-Coupling Learning
Jan 03, 2024



Quantization is of significance for compressing the over-parameterized deep neural models and deploying them on resource-limited devices. Fixed-precision quantization suffers from performance drop due to the limited numerical representation ability. Conversely, mixed-precision quantization (MPQ) is advocated to compress the model effectively by allocating heterogeneous bit-width for layers. MPQ is typically organized into a searching-retraining two-stage process. Previous works only focus on determining the optimal bit-width configuration in the first stage efficiently, while ignoring the considerable time costs in the second stage. However, retraining always consumes hundreds of GPU-hours on the cutting-edge GPUs, thus hindering deployment efficiency significantly. In this paper, we devise a one-shot training-searching paradigm for mixed-precision model compression. Specifically, in the first stage, all potential bit-width configurations are coupled and thus optimized simultaneously within a set of shared weights. However, our observations reveal a previously unseen and severe bit-width interference phenomenon among highly coupled weights during optimization, leading to considerable performance degradation under a high compression ratio. To tackle this problem, we first design a bit-width scheduler to dynamically freeze the most turbulent bit-width of layers during training, to ensure the rest bit-widths converged properly. Then, taking inspiration from information theory, we present an information distortion mitigation technique to align the behaviour of the bad-performing bit-widths to the well-performing ones.
DAGC: Data-Volume-Aware Adaptive Sparsification Gradient Compression for Distributed Machine Learning in Mobile Computing
Nov 13, 2023



Distributed machine learning (DML) in mobile environments faces significant communication bottlenecks. Gradient compression has emerged as an effective solution to this issue, offering substantial benefits in environments with limited bandwidth and metered data. Yet, they encounter severe performance drop in non-IID environments due to a one-size-fits-all compression approach, which does not account for the varying data volumes across workers. Assigning varying compression ratios to workers with distinct data distributions and volumes is thus a promising solution. This study introduces an analysis of distributed SGD with non-uniform compression, which reveals that the convergence rate (indicative of the iterations needed to achieve a certain accuracy) is influenced by compression ratios applied to workers with differing volumes. Accordingly, we frame relative compression ratio assignment as an $n$-variables chi-square nonlinear optimization problem, constrained by a fixed and limited communication budget. We propose DAGC-R, which assigns the worker handling larger data volumes the conservative compression. Recognizing the computational limitations of mobile devices, we DAGC-A, which are computationally less demanding and enhances the robustness of the absolute gradient compressor in non-IID scenarios. Our experiments confirm that both the DAGC-A and DAGC-R can achieve better performance when dealing with highly imbalanced data volume distribution and restricted communication.