 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Collapse in Test-Time Adaptation
Dec 11, 2025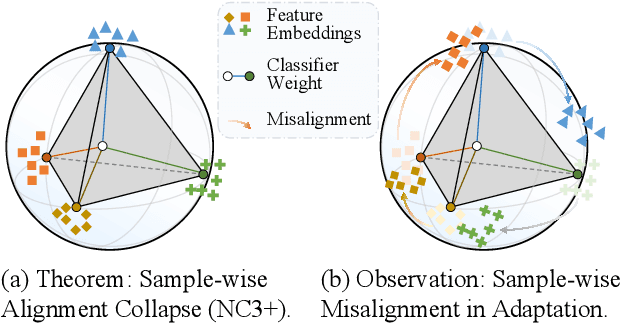
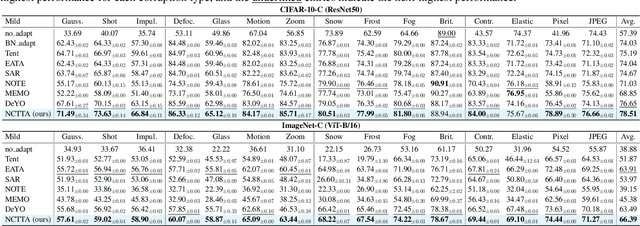
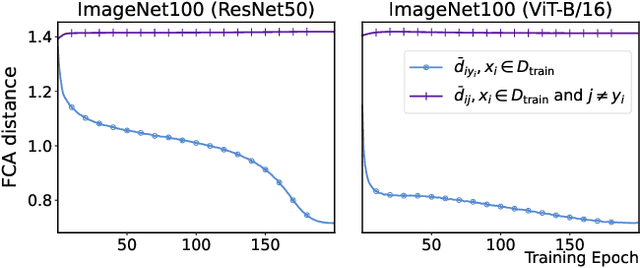
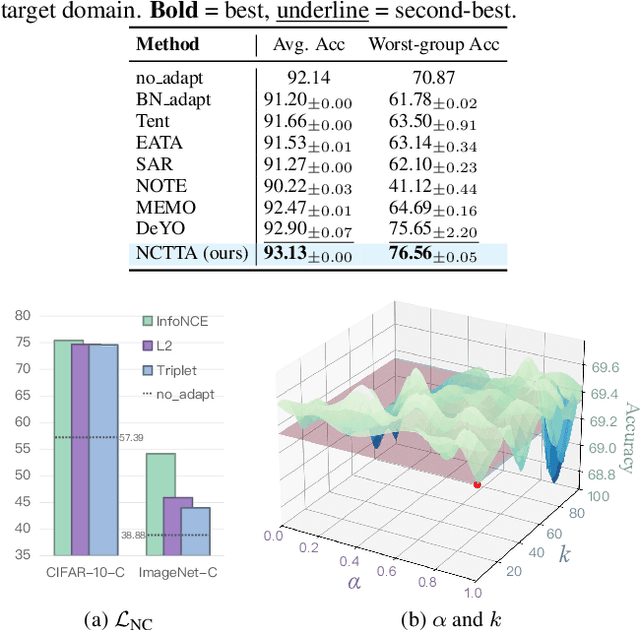
Test-Time Adaptation (TTA) enhances model robustness to out-of-distribution (OOD) data by updating the model online during inference, yet existing methods lack theoretical insights into the fundamental causes of performance degradation under domain shifts. Recently, Neural Collapse (NC) has been proposed as an emergent geometric property of deep neural networks (DNNs), providing valuable insights for TTA. In this work, we extend NC to the sample-wise level and discover a novel phenomenon termed Sample-wise Alignment Collapse (NC3+), demonstrating that a sample's feature embedding, obtained by a trained model, aligns closely with the corresponding classifier weight. Building on NC3+, we identify that the performance degradation stems from sample-wise misalignment in adaptation which exacerbates under larger distribution shifts. This indicates the necessity of realigning the feature embeddings with their corresponding classifier weights. However, the misalignment makes pseudo-labels unreliable under domain shifts. To address this challenge, we propose NCTTA, a novel feature-classifier alignment method with hybrid targets to mitigate the impact of unreliable pseudo-labels, which blends geometric proximity with predictive confidence. Extensive experiments demonstrate the effectiveness of NCTTA in enhancing robustness to domain shifts. For example, NCTTA outperforms Tent by 14.52% on ImageNet-C.
Exploring Test-time Scaling via Prediction Merging on Large-Scale Recommendation
Dec 08, 2025Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.
MoETTA: Test-Time Adaptation Under Mixed Distribution Shifts with MoE-LayerNorm
Nov 14, 2025Test-Time adaptation (TTA) has proven effective in mitigating performance drops under single-domain distribution shifts by updating model parameters during inference. However, real-world deployments often involve mixed distribution shifts, where test samples are affected by diverse and potentially conflicting domain factors, posing significant challenges even for SOTA TTA methods. A key limitation in existing approaches is their reliance on a unified adaptation path, which fails to account for the fact that optimal gradient directions can vary significantly across different domains. Moreover, current benchmarks focus only on synthetic or homogeneous shifts, failing to capture the complexity of real-world heterogeneous mixed distribution shifts. To address this, we propose MoETTA, a novel entropy-based TTA framework that integrates the Mixture-of-Experts (MoE) architecture. Rather than enforcing a single parameter update rule for all test samples, MoETTA introduces a set of structurally decoupled experts, enabling adaptation along diverse gradient directions. This design allows the model to better accommodate heterogeneous shifts through flexible and disentangled parameter updates. To simulate realistic deployment conditions, we introduce two new benchmarks: potpourri and potpourri+. While classical settings focus solely on synthetic corruptions, potpourri encompasses a broader range of domain shifts--including natural, artistic, and adversarial distortions--capturing more realistic deployment challenges. Additionally, potpourri+ further includes source-domain samples to evaluate robustness against catastrophic forgetting. Extensive experiments across three mixed distribution shifts settings show that MoETTA consistently outperforms strong baselines, establishing SOTA performance and highlighting the benefit of modeling multiple adaptation directions via expert-level diversity.
DeCo-SGD: Joint Optimization of Delay Staleness and Gradient Compression Ratio for Distributed SGD
Jul 23, 2025Distributed machine learning in high end-to-end latency and low, varying bandwidth network environments undergoes severe throughput degradation. Due to its low communication requirements, distributed SGD (D-SGD) remains the mainstream optimizer in such challenging networks, but it still suffers from significant throughput reduction. To mitigate these limitations, existing approaches typically employ gradient compression and delayed aggregation to alleviate low bandwidth and high latency, respectively. To address both challenges simultaneously, these strategies are often combined, introducing a complex three-way trade-off among compression ratio, staleness (delayed synchronization steps), and model convergence rate. To achieve the balance under varying bandwidth conditions, an adaptive policy is required to dynamically adjust these parameters. Unfortunately, existing works rely on static heuristic strategies due to the lack of theoretical guidance, which prevents them from achieving this goal. This study fills in this theoretical gap by introducing a new theoretical tool, decomposing the joint optimization problem into a traditional convergence rate analysis with multiple analyzable noise terms. We are the first to reveal that staleness exponentially amplifies the negative impact of gradient compression on training performance, filling a critical gap in understanding how compressed and delayed gradients affect training. Furthermore, by integrating the convergence rate with a network-aware time minimization condition, we propose DeCo-SGD, which dynamically adjusts the compression ratio and staleness based on the real-time network condition and training task. DeCo-SGD achieves up to 5.07 and 1.37 speed-ups over D-SGD and static strategy in high-latency and low, varying bandwidth networks, respectively.
Accelerating Parallel Diffusion Model Serving with Residual Compression
Jul 23, 2025Diffusion models produce realistic images and videos but require substantial computational resources, necessitating multi-accelerator parallelism for real-time deployment. However, parallel inference introduces significant communication overhead from exchanging large activations between devices, limiting efficiency and scalability. We present CompactFusion, a compression framework that significantly reduces communication while preserving generation quality. Our key observation is that diffusion activations exhibit strong temporal redundancy-adjacent steps produce highly similar activations, saturating bandwidth with near-duplicate data carrying little new information. To address this inefficiency, we seek a more compact representation that encodes only the essential information. CompactFusion achieves this via Residual Compression that transmits only compressed residuals (step-wise activation differences). Based on empirical analysis and theoretical justification, we show that it effectively removes redundant data, enabling substantial data reduction while maintaining high fidelity. We also integrate lightweight error feedback to prevent error accumulation. CompactFusion establishes a new paradigm for parallel diffusion inference, delivering lower latency and significantly higher generation quality than prior methods. On 4xL20, it achieves 3.0x speedup while greatly improving fidelity. It also uniquely supports communication-heavy strategies like sequence parallelism on slow networks, achieving 6.7x speedup over prior overlap-based method. CompactFusion applies broadly across diffusion models and parallel settings, and integrates easily without requiring pipeline rework. Portable implementation demonstrated on xDiT is publicly available at https://github.com/Cobalt-27/CompactFusion
Feature-Based Instance Neighbor Discovery: Advanced Stable Test-Time Adaptation in Dynamic World
Jun 07, 2025Despite progress, deep neural networks still suffer performance declines under distribution shifts between training and test domains, leading to a substantial decrease in Quality of Experience (QoE) for applications. Existing test-time adaptation (TTA) methods are challenged by dynamic, multiple test distributions within batches. We observe that feature distributions across different domains inherently cluster into distinct groups with varying means and variances. This divergence reveals a critical limitation of previous global normalization strategies in TTA, which inevitably distort the original data characteristics. Based on this insight, we propose Feature-based Instance Neighbor Discovery (FIND), which comprises three key components: Layer-wise Feature Disentanglement (LFD), Feature Aware Batch Normalization (FABN) and Selective FABN (S-FABN). LFD stably captures features with similar distributions at each layer by constructing graph structures. While FABN optimally combines source statistics with test-time distribution specific statistics for robust feature representation. Finally, S-FABN determines which layers require feature partitioning and which can remain unified, thereby enhancing inference efficiency. Extensive experiments demonstrate that FIND significantly outperforms existing methods, achieving a 30\% accuracy improvement in dynamic scenarios while maintaining computational efficiency.
COSMIC: Clique-Oriented Semantic Multi-space Integration for Robust CLIP Test-Time Adaptation
Mar 30, 2025Recent vision-language models (VLMs) face significant challenges in test-time adaptation to novel domains. While cache-based methods show promise by leveraging historical information, they struggle with both caching unreliable feature-label pairs and indiscriminately using single-class information during querying, significantly compromising adaptation accuracy. To address these limitations, we propose COSMIC (Clique-Oriented Semantic Multi-space Integration for CLIP), a robust test-time adaptation framework that enhances adaptability through multi-granular, cross-modal semantic caching and graph-based querying mechanisms. Our framework introduces two key innovations: Dual Semantics Graph (DSG) and Clique Guided Hyper-class (CGH). The Dual Semantics Graph constructs complementary semantic spaces by incorporating textual features, coarse-grained CLIP features, and fine-grained DINOv2 features to capture rich semantic relationships. Building upon these dual graphs, the Clique Guided Hyper-class component leverages structured class relationships to enhance prediction robustness through correlated class selection. Extensive experiments demonstrate COSMIC's superior performance across multiple benchmarks, achieving significant improvements over state-of-the-art methods: 15.81% gain on out-of-distribution tasks and 5.33% on cross-domain generation with CLIP RN-50. Code is available at github.com/hf618/COSMIC.
DATTA: Towards Diversity Adaptive Test-Time Adaptation in Dynamic Wild World
Aug 15, 2024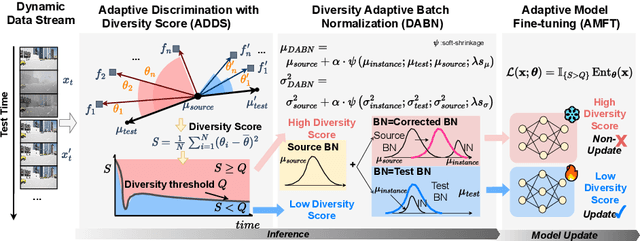
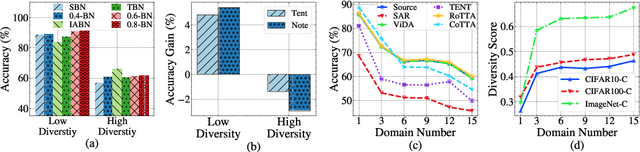
Test-time adaptation (TTA) effectively addresses distribution shifts between training and testing data by adjusting models on test samples, which is crucial for improving model inference in real-world applications. However, traditional TTA methods typically follow a fixed pattern to address the dynamic data patterns (low-diversity or high-diversity patterns) often leading to performance degradation and consequently a decline in Quality of Experience (QoE). The primary issues we observed are:Different scenarios require different normalization methods (e.g., Instance Normalization is optimal in mixed domains but not in static domains). Model fine-tuning can potentially harm the model and waste time.Hence, it is crucial to design strategies for effectively measuring and managing distribution diversity to minimize its negative impact on model performance. Based on these observations, this paper proposes a new general method, named Diversity Adaptive Test-Time Adaptation (DATTA), aimed at improving QoE. DATTA dynamically selects the best batch normalization methods and fine-tuning strategies by leveraging the Diversity Score to differentiate between high and low diversity score batches. It features three key components: Diversity Discrimination (DD) to assess batch diversity, Diversity Adaptive Batch Normalization (DABN) to tailor normalization methods based on DD insights, and Diversity Adaptive Fine-Tuning (DAFT) to selectively fine-tune the model. Experimental results show that our method achieves up to a 21% increase in accuracy compared to state-of-the-art methodologies, indicating that our method maintains good model performance while demonstrating its robustness. Our code will be released soon.
Domain-invariant Representation Learning via Segment Anything Model for Blood Cell Classification
Aug 14, 2024Accurate classification of blood cells is of vital significance in the diagnosis of hematological disorders. However, in real-world scenarios, domain shifts caused by the variability in laboratory procedures and settings, result in a rapid deterioration of the model's generalization performance. To address this issue, we propose a novel framework of domain-invariant representation learning (DoRL) via segment anything model (SAM) for blood cell classification. The DoRL comprises two main components: a LoRA-based SAM (LoRA-SAM) and a cross-domain autoencoder (CAE). The advantage of DoRL is that it can extract domain-invariant representations from various blood cell datasets in an unsupervised manner. Specifically, we first leverage the large-scale foundation model of SAM, fine-tuned with LoRA, to learn general image embeddings and segment blood cells. Additionally, we introduce CAE to learn domain-invariant representations across different-domain datasets while mitigating images' artifacts. To validate the effectiveness of domain-invariant representations, we employ five widely used machine learning classifiers to construct blood cell classification models. Experimental results on two public blood cell datasets and a private real dataset demonstrate that our proposed DoRL achieves a new state-of-the-art cross-domain performance, surpassing existing methods by a significant margin. The source code can be available at the URL (https://github.com/AnoK3111/DoRL).
Towards Cross-Domain Single Blood Cell Image Classification via Large-Scale LoRA-based Segment Anything Model
Aug 13, 2024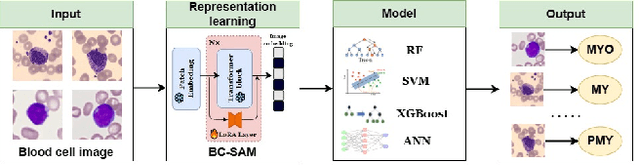
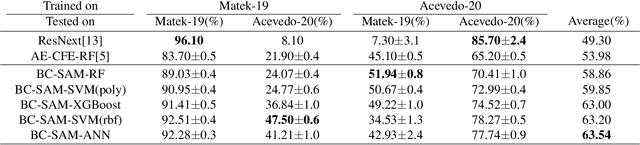
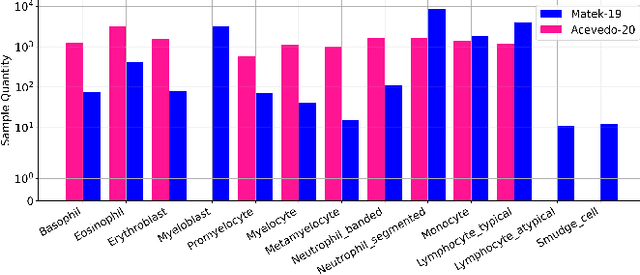
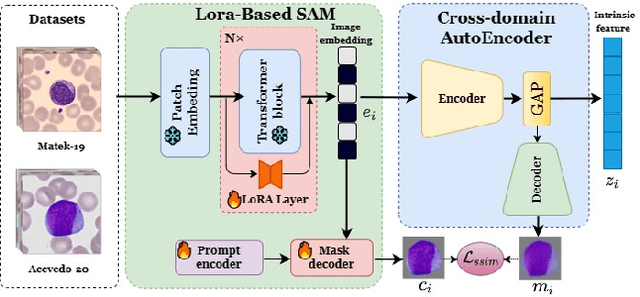
Accurate classification of blood cells plays a vital role in hematological analysis as it aids physicians in diagnosing various medical conditions. In this study, we present a novel approach for classifying blood cell images known as BC-SAM. BC-SAM leverages the large-scale foundation model of Segment Anything Model (SAM) and incorporates a fine-tuning technique using LoRA, allowing it to extract general image embeddings from blood cell images. To enhance the applicability of BC-SAM across different blood cell image datasets, we introduce an unsupervised cross-domain autoencoder that focuses on learning intrinsic features while suppressing artifacts in the images. To assess the performance of BC-SAM, we employ four widely used machine learning classifiers (Random Forest, Support Vector Machine, Artificial Neural Network, and XGBoost) to construct blood cell classification models and compare them against existing state-of-the-art methods. Experimental results conducted on two publicly available blood cell datasets (Matek-19 and Acevedo-20) demonstrate that our proposed BC-SAM achieves a new state-of-the-art result, surpassing the baseline methods with a significant improvement. The source code of this paper is available at https://github.com/AnoK3111/BC-SAM.