 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoETTA: Test-Time Adaptation Under Mixed Distribution Shifts with MoE-LayerNorm
Nov 14, 2025Test-Time adaptation (TTA) has proven effective in mitigating performance drops under single-domain distribution shifts by updating model parameters during inference. However, real-world deployments often involve mixed distribution shifts, where test samples are affected by diverse and potentially conflicting domain factors, posing significant challenges even for SOTA TTA methods. A key limitation in existing approaches is their reliance on a unified adaptation path, which fails to account for the fact that optimal gradient directions can vary significantly across different domains. Moreover, current benchmarks focus only on synthetic or homogeneous shifts, failing to capture the complexity of real-world heterogeneous mixed distribution shifts. To address this, we propose MoETTA, a novel entropy-based TTA framework that integrates the Mixture-of-Experts (MoE) architecture. Rather than enforcing a single parameter update rule for all test samples, MoETTA introduces a set of structurally decoupled experts, enabling adaptation along diverse gradient directions. This design allows the model to better accommodate heterogeneous shifts through flexible and disentangled parameter updates. To simulate realistic deployment conditions, we introduce two new benchmarks: potpourri and potpourri+. While classical settings focus solely on synthetic corruptions, potpourri encompasses a broader range of domain shifts--including natural, artistic, and adversarial distortions--capturing more realistic deployment challenges. Additionally, potpourri+ further includes source-domain samples to evaluate robustness against catastrophic forgetting. Extensive experiments across three mixed distribution shifts settings show that MoETTA consistently outperforms strong baselines, establishing SOTA performance and highlighting the benefit of modeling multiple adaptation directions via expert-level diversity.
Feature-Based Instance Neighbor Discovery: Advanced Stable Test-Time Adaptation in Dynamic World
Jun 07, 2025Despite progress, deep neural networks still suffer performance declines under distribution shifts between training and test domains, leading to a substantial decrease in Quality of Experience (QoE) for applications. Existing test-time adaptation (TTA) methods are challenged by dynamic, multiple test distributions within batches. We observe that feature distributions across different domains inherently cluster into distinct groups with varying means and variances. This divergence reveals a critical limitation of previous global normalization strategies in TTA, which inevitably distort the original data characteristics. Based on this insight, we propose Feature-based Instance Neighbor Discovery (FIND), which comprises three key components: Layer-wise Feature Disentanglement (LFD), Feature Aware Batch Normalization (FABN) and Selective FABN (S-FABN). LFD stably captures features with similar distributions at each layer by constructing graph structures. While FABN optimally combines source statistics with test-time distribution specific statistics for robust feature representation. Finally, S-FABN determines which layers require feature partitioning and which can remain unified, thereby enhancing inference efficiency. Extensive experiments demonstrate that FIND significantly outperforms existing methods, achieving a 30\% accuracy improvement in dynamic scenarios while maintaining computational efficiency.
COSMIC: Clique-Oriented Semantic Multi-space Integration for Robust CLIP Test-Time Adaptation
Mar 30, 2025Recent vision-language models (VLMs) face significant challenges in test-time adaptation to novel domains. While cache-based methods show promise by leveraging historical information, they struggle with both caching unreliable feature-label pairs and indiscriminately using single-class information during querying, significantly compromising adaptation accuracy. To address these limitations, we propose COSMIC (Clique-Oriented Semantic Multi-space Integration for CLIP), a robust test-time adaptation framework that enhances adaptability through multi-granular, cross-modal semantic caching and graph-based querying mechanisms. Our framework introduces two key innovations: Dual Semantics Graph (DSG) and Clique Guided Hyper-class (CGH). The Dual Semantics Graph constructs complementary semantic spaces by incorporating textual features, coarse-grained CLIP features, and fine-grained DINOv2 features to capture rich semantic relationships. Building upon these dual graphs, the Clique Guided Hyper-class component leverages structured class relationships to enhance prediction robustness through correlated class selection. Extensive experiments demonstrate COSMIC's superior performance across multiple benchmarks, achieving significant improvements over state-of-the-art methods: 15.81% gain on out-of-distribution tasks and 5.33% on cross-domain generation with CLIP RN-50. Code is available at github.com/hf618/COSMIC.
DATTA: Towards Diversity Adaptive Test-Time Adaptation in Dynamic Wild World
Aug 15, 2024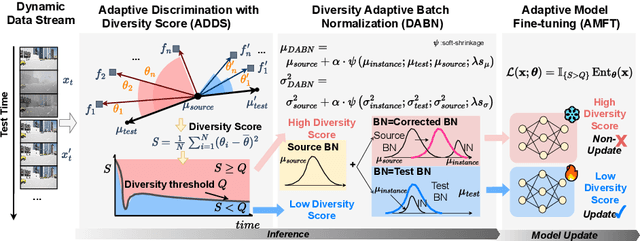
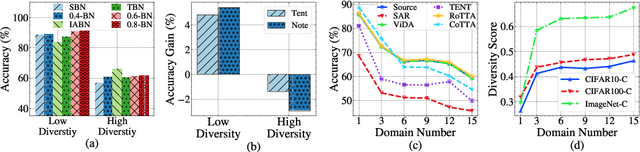
Test-time adaptation (TTA) effectively addresses distribution shifts between training and testing data by adjusting models on test samples, which is crucial for improving model inference in real-world applications. However, traditional TTA methods typically follow a fixed pattern to address the dynamic data patterns (low-diversity or high-diversity patterns) often leading to performance degradation and consequently a decline in Quality of Experience (QoE). The primary issues we observed are:Different scenarios require different normalization methods (e.g., Instance Normalization is optimal in mixed domains but not in static domains). Model fine-tuning can potentially harm the model and waste time.Hence, it is crucial to design strategies for effectively measuring and managing distribution diversity to minimize its negative impact on model performance. Based on these observations, this paper proposes a new general method, named Diversity Adaptive Test-Time Adaptation (DATTA), aimed at improving QoE. DATTA dynamically selects the best batch normalization methods and fine-tuning strategies by leveraging the Diversity Score to differentiate between high and low diversity score batches. It features three key components: Diversity Discrimination (DD) to assess batch diversity, Diversity Adaptive Batch Normalization (DABN) to tailor normalization methods based on DD insights, and Diversity Adaptive Fine-Tuning (DAFT) to selectively fine-tune the model. Experimental results show that our method achieves up to a 21% increase in accuracy compared to state-of-the-art methodologies, indicating that our method maintains good model performance while demonstrating its robustness. Our code will be released soon.
Discover Your Neighbors: Advanced Stable Test-Time Adaptation in Dynamic World
Jun 08, 2024Despite progress, deep neural networks still suffer performance declines under distribution shifts between training and test domains, leading to a substantial decrease in Quality of Experience (QoE) for multimedia applications. Existing test-time adaptation (TTA) methods are challenged by dynamic, multiple test distributions within batches. This work provides a new perspective on analyzing batch normalization techniques through class-related and class-irrelevant features, our observations reveal combining source and test batch normalization statistics robustly characterizes target distributions. However, test statistics must have high similarity. We thus propose Discover Your Neighbours (DYN), the first backward-free approach specialized for dynamic TTA. The core innovation is identifying similar samples via instance normalization statistics and clustering into groups which provides consistent class-irrelevant representations. Specifically, Our DYN consists of layer-wise instance statistics clustering (LISC) and cluster-aware batch normalization (CABN). In LISC, we perform layer-wise clustering of approximate feature samples at each BN layer by calculating the cosine similarity of instance normalization statistics across the batch. CABN then aggregates SBN and TCN statistics to collaboratively characterize the target distribution, enabling more robust representations. Experimental results validate DYN's robustness and effectiveness, demonstrating maintained performance under dynamic data stream patterns.