 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentar-Fin-R1: Enhancing Financial Intelligence through Domain Expertise, Training Efficiency, and Advanced Reasoning
Jul 24, 2025Large Language Models (LLMs) exhibit considerable promise in financial applications; however, prevailing models frequently demonstrate limitations when confronted with scenarios that necessitate sophisticated reasoning capabilities, stringent trustworthiness criteria, and efficient adaptation to domain-specific requirements. We introduce the Agentar-Fin-R1 series of financial large language models (8B and 32B parameters), specifically engineered based on the Qwen3 foundation model to enhance reasoning capabilities, reliability, and domain specialization for financial applications. Our optimization approach integrates a high-quality, systematic financial task label system with a comprehensive multi-layered trustworthiness assurance framework. This framework encompasses high-quality trustworthy knowledge engineering, multi-agent trustworthy data synthesis, and rigorous data validation governance. Through label-guided automated difficulty-aware optimization, tow-stage training pipeline, and dynamic attribution systems, we achieve substantial improvements in training efficiency. Our models undergo comprehensive evaluation on mainstream financial benchmarks including Fineva, FinEval, and FinanceIQ, as well as general reasoning datasets such as MATH-500 and GPQA-diamond. To thoroughly assess real-world deployment capabilities, we innovatively propose the Finova evaluation benchmark, which focuses on agent-level financial reasoning and compliance verification. Experimental results demonstrate that Agentar-Fin-R1 not only achieves state-of-the-art performance on financial tasks but also exhibits exceptional general reasoning capabilities, validating its effectiveness as a trustworthy solution for high-stakes financial applications. The Finova bench is available at https://github.com/antgroup/Finova.
Multijugate Dual Learning for Low-Resource Task-Oriented Dialogue System
May 25, 2023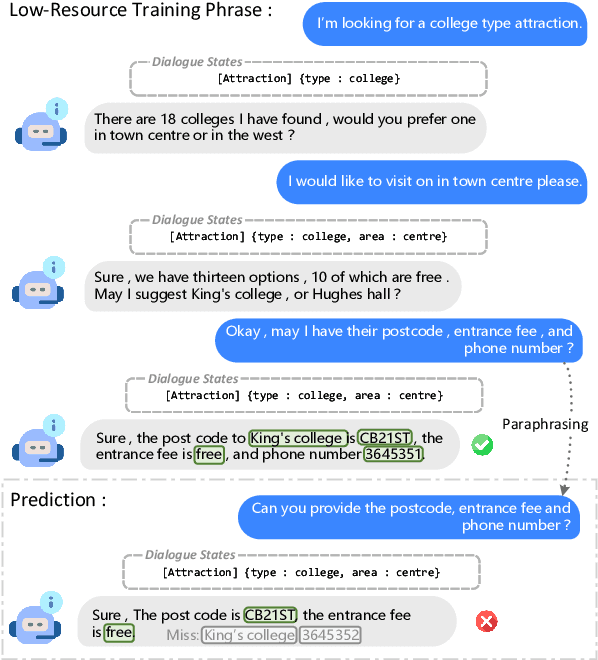
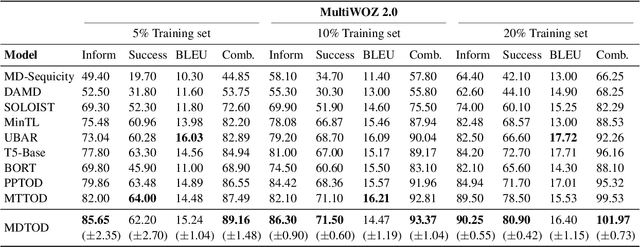
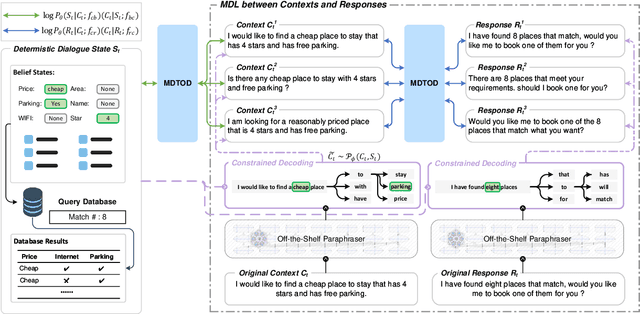
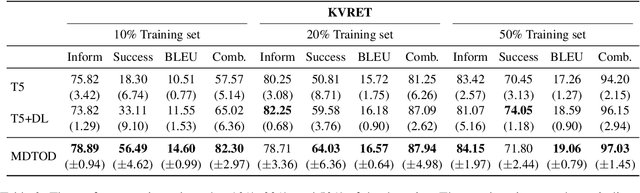
Dialogue data in real scenarios tend to be sparsely available, rendering data-starved end-to-end dialogue systems trained inadequately. We discover that data utilization efficiency in low-resource scenarios can be enhanced by mining alignment information uncertain utterance and deterministic dialogue state. Therefore, we innovatively implement dual learning in task-oriented dialogues to exploit the correlation of heterogeneous data. In addition, the one-to-one duality is converted into a multijugate duality to reduce the influence of spurious correlations in dual training for generalization. Without introducing additional parameters, our method could be implemented in arbitrary networks. Extensive empirical analyses demonstrate that our proposed method improves the effectiveness of end-to-end task-oriented dialogue systems under multiple benchmarks and obtains state-of-the-art results in low-resource scenarios.
Cascading Hierarchical Networks with Multi-task Balanced Loss for Fine-grained hashing
Mar 20, 2023With the explosive growth in the number of fine-grained images in the Internet era, it has become a challenging problem to perform fast and efficient retrieval from large-scale fine-grained images. Among the many retrieval methods, hashing methods are widely used due to their high efficiency and small storage space occupation. Fine-grained hashing is more challenging than traditional hashing problems due to the difficulties such as low inter-class variances and high intra-class variances caused by the characteristics of fine-grained images. To improve the retrieval accuracy of fine-grained hashing, we propose a cascaded network to learn compact and highly semantic hash codes, and introduce an attention-guided data augmentation method. We refer to this network as a cascaded hierarchical data augmentation network. We also propose a novel approach to coordinately balance the loss of multi-task learning. We do extensive experiments on some common fine-grained visual classification datasets. The experimental results demonstrate that our proposed method outperforms several state-of-art hashing methods and can effectively improve the accuracy of fine-grained retrieval. The source code is publicly available: https://github.com/kaiba007/FG-CNET.
Investigating Glyph Phonetic Information for Chinese Spell Checking: What Works and What's Next
Dec 18, 2022While pre-trained Chinese language models have demonstrated impressive performance on a wide range of NLP tasks, the Chinese Spell Checking (CSC) task remains a challenge. Previous research has explored using information such as glyphs and phonetics to improve the ability to distinguish misspelled characters, with good results. However, the generalization ability of these models is not well understood: it is unclear whether they incorporate glyph-phonetic information and, if so, whether this information is fully utilized. In this paper, we aim to better understand the role of glyph-phonetic information in the CSC task and suggest directions for improvement. Additionally, we propose a new, more challenging, and practical setting for testing the generalizability of CSC models. All code is made publicly available.