 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime and Frequency Network for Human Action Detection in Videos
Mar 08, 2021
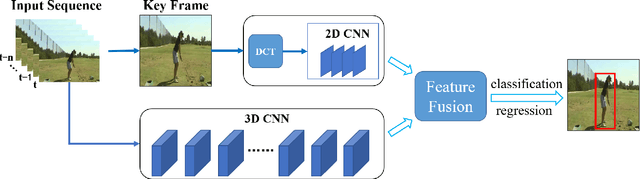
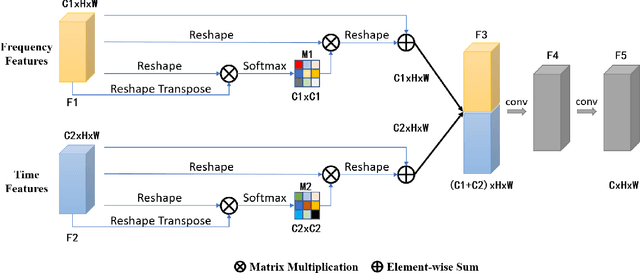

Currently, spatiotemporal features are embraced by most deep learning approaches for human action detection in videos, however, they neglect the important features in frequency domain. In this work, we propose an end-to-end network that considers the time and frequency features simultaneously, named TFNet. TFNet holds two branches, one is time branch formed of three-dimensional convolutional neural network(3D-CNN), which takes the image sequence as input to extract time features; and the other is frequency branch, extracting frequency features through two-dimensional convolutional neural network(2D-CNN) from DCT coefficients. Finally, to obtain the action patterns, these two features are deeply fused under the attention mechanism. Experimental results on the JHMDB51-21 and UCF101-24 datasets demonstrate that our approach achieves remarkable performance for frame-mAP.