 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Context and Multi-modal Alignment for Freehand 3D Ultrasound Reconstruction
Jul 05, 2024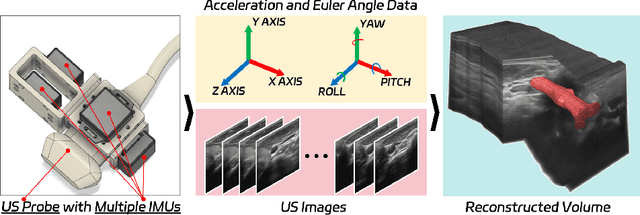


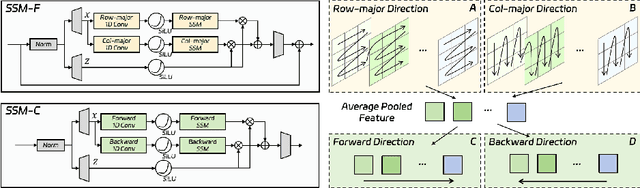
Fine-grained spatio-temporal learning is crucial for freehand 3D ultrasound reconstruction. Previous works mainly resorted to the coarse-grained spatial features and the separated temporal dependency learning and struggles for fine-grained spatio-temporal learning. Mining spatio-temporal information in fine-grained scales is extremely challenging due to learning difficulties in long-range dependencies. In this context, we propose a novel method to exploit the long-range dependency management capabilities of the state space model (SSM) to address the above challenge. Our contribution is three-fold. First, we propose ReMamba, which mines multi-scale spatio-temporal information by devising a multi-directional SSM. Second, we propose an adaptive fusion strategy that introduces multiple inertial measurement units as auxiliary temporal information to enhance spatio-temporal perception. Last, we design an online alignment strategy that encodes the temporal information as pseudo labels for multi-modal alignment to further improve reconstruction performance. Extensive experimental validations on two large-scale datasets show remarkable improvement from our method over competitors.
A Foundation Model for General Moving Object Segmentation in Medical Images
Oct 04, 2023



Medical image segmentation aims to delineate the anatomical or pathological structures of interest, playing a crucial role in clinical diagnosis. A substantial amount of high-quality annotated data is crucial for constructing high-precision deep segmentation models. However, medical annotation is highly cumbersome and time-consuming, especially for medical videos or 3D volumes, due to the huge labeling space and poor inter-frame consistency. Recently, a fundamental task named Moving Object Segmentation (MOS) has made significant advancements in natural images. Its objective is to delineate moving objects from the background within image sequences, requiring only minimal annotations. In this paper, we propose the first foundation model, named iMOS, for MOS in medical images. Extensive experiments on a large multi-modal medical dataset validate the effectiveness of the proposed iMOS. Specifically, with the annotation of only a small number of images in the sequence, iMOS can achieve satisfactory tracking and segmentation performance of moving objects throughout the entire sequence in bi-directions. We hope that the proposed iMOS can help accelerate the annotation speed of experts, and boost the development of medical foundation models.
Multi-IMU with Online Self-Consistency for Freehand 3D Ultrasound Reconstruction
Jul 19, 2023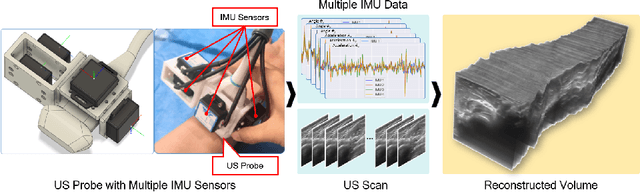
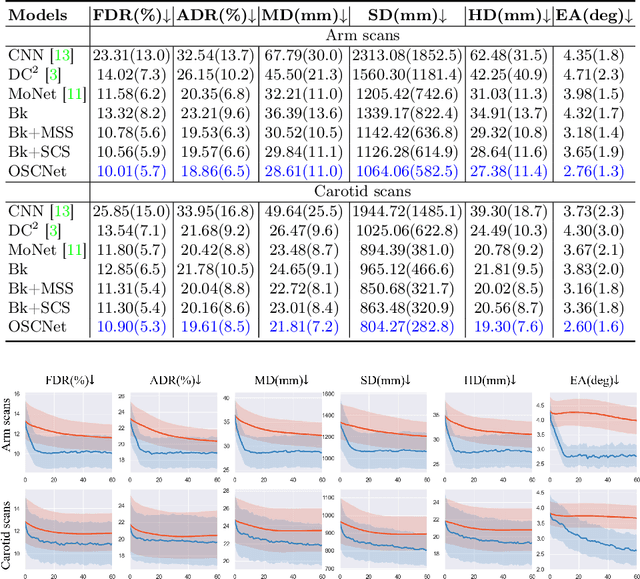
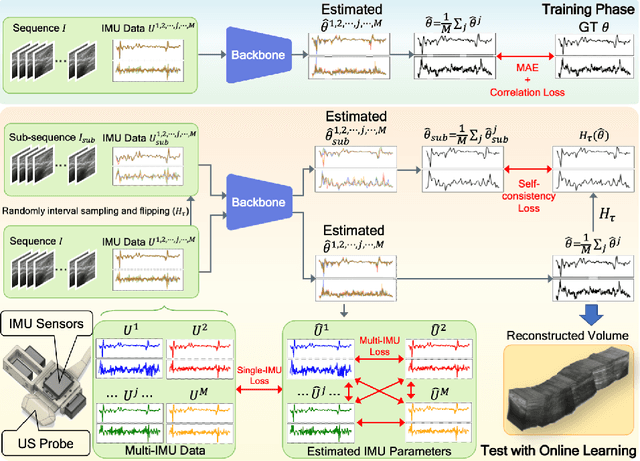
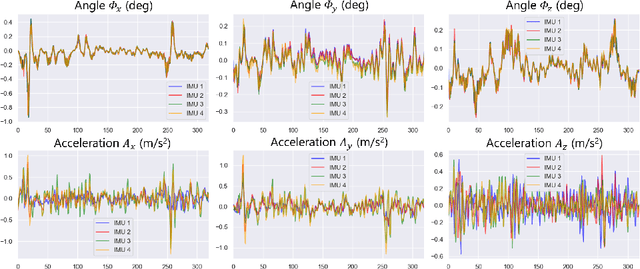
Ultrasound (US) imaging is a popular tool in clinical diagnosis, offering safety, repeatability, and real-time capabilities. Freehand 3D US is a technique that provides a deeper understanding of scanned regions without increasing complexity. However, estimating elevation displacement and accumulation error remains challenging, making it difficult to infer the relative position using images alone. The addition of external lightweight sensors has been proposed to enhance reconstruction performance without adding complexity, which has been shown to be beneficial. We propose a novel online self-consistency network (OSCNet) using multiple inertial measurement units (IMUs) to improve reconstruction performance. OSCNet utilizes a modal-level self-supervised strategy to fuse multiple IMU information and reduce differences between reconstruction results obtained from each IMU data. Additionally, a sequence-level self-consistency strategy is proposed to improve the hierarchical consistency of prediction results among the scanning sequence and its sub-sequences. Experiments on large-scale arm and carotid datasets with multiple scanning tactics demonstrate that our OSCNet outperforms previous methods, achieving state-of-the-art reconstruction performance.