 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Scale Autoregressive Models are Zero-Shot Single-Image Object View Synthesizers
Mar 17, 2025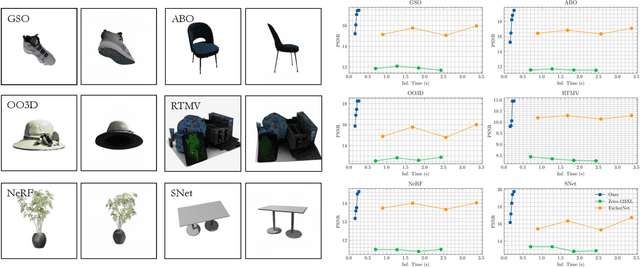
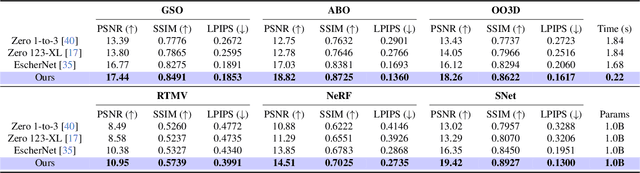
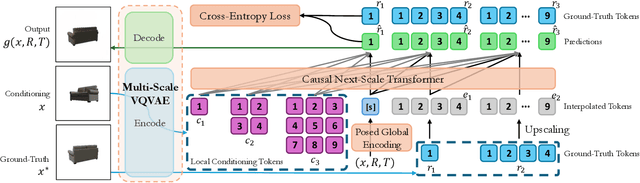
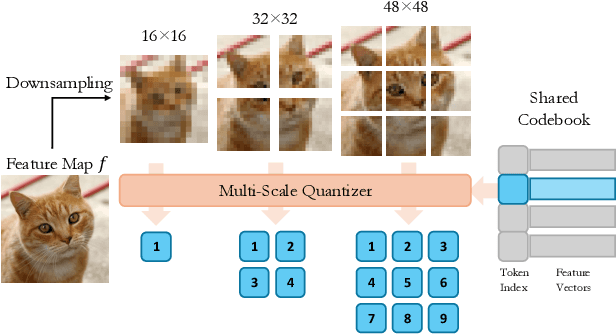
Methods based on diffusion backbones have recently revolutionized novel view synthesis (NVS). However, those models require pretrained 2D diffusion checkpoints (e.g., Stable Diffusion) as the basis for geometrical priors. Since such checkpoints require exorbitant amounts of data and compute to train, this greatly limits the scalability of diffusion-based NVS models. We present Next-Scale Autoregression Conditioned by View (ArchonView), a method that significantly exceeds state-of-the-art methods despite being trained from scratch with 3D rendering data only and no 2D pretraining. We achieve this by incorporating both global (pose-augmented semantics) and local (multi-scale hierarchical encodings) conditioning into a backbone based on the next-scale autoregression paradigm. Our model also exhibits robust performance even for difficult camera poses where previous methods fail, and is several times faster in inference speed compared to diffusion. We experimentally verify that performance scales with model and dataset size, and conduct extensive demonstration of our method's synthesis quality across several tasks. Our code is open-sourced at https://github.com/Shiran-Yuan/ArchonView.
Hybrid Spatial Representations for Species Distribution Modeling
Oct 14, 2024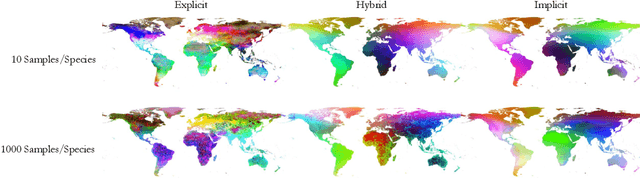
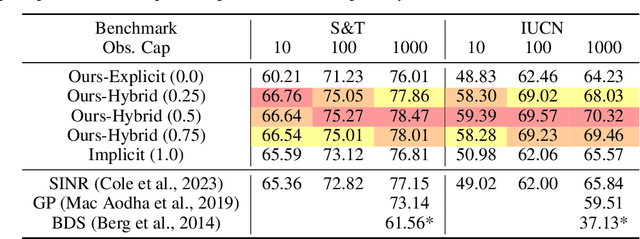
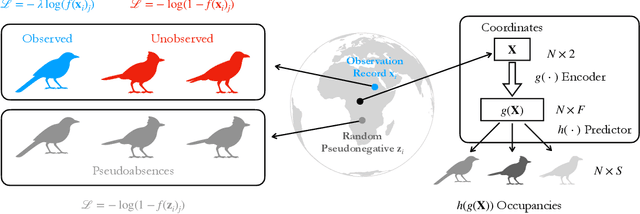
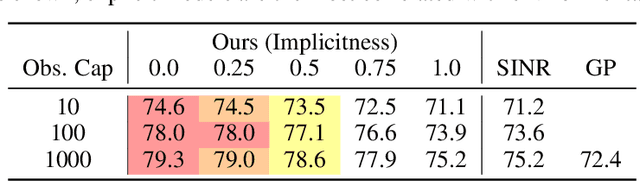
We address an important problem in ecology called Species Distribution Modeling (SDM), whose goal is to predict whether a species exists at a certain position on Earth. In particular, we tackle a challenging version of this task, where we learn from presence-only data in a community-sourced dataset, model a large number of species simultaneously, and do not use any additional environmental information. Previous work has used neural implicit representations to construct models that achieve promising results. However, implicit representations often generate predictions of limited spatial precision. We attribute this limitation to their inherently global formulation and inability to effectively capture local feature variations. This issue is especially pronounced with presence-only data and a large number of species. To address this, we propose a hybrid embedding scheme that combines both implicit and explicit embeddings. Specifically, the explicit embedding is implemented with a multiresolution hashgrid, enabling our models to better capture local information. Experiments demonstrate that our results exceed other works by a large margin on various standard benchmarks, and that the hybrid representation is better than both purely implicit and explicit ones. Qualitative visualizations and comprehensive ablation studies reveal that our hybrid representation successfully addresses the two main challenges. Our code is open-sourced at https://github.com/Shiran-Yuan/HSR-SDM.
SA-GS: Scale-Adaptive Gaussian Splatting for Training-Free Anti-Aliasing
Mar 28, 2024



In this paper, we present a Scale-adaptive method for Anti-aliasing Gaussian Splatting (SA-GS). While the state-of-the-art method Mip-Splatting needs modifying the training procedure of Gaussian splatting, our method functions at test-time and is training-free. Specifically, SA-GS can be applied to any pretrained Gaussian splatting field as a plugin to significantly improve the field's anti-alising performance. The core technique is to apply 2D scale-adaptive filters to each Gaussian during test time. As pointed out by Mip-Splatting, observing Gaussians at different frequencies leads to mismatches between the Gaussian scales during training and testing. Mip-Splatting resolves this issue using 3D smoothing and 2D Mip filters, which are unfortunately not aware of testing frequency. In this work, we show that a 2D scale-adaptive filter that is informed of testing frequency can effectively match the Gaussian scale, thus making the Gaussian primitive distribution remain consistent across different testing frequencies. When scale inconsistency is eliminated, sampling rates smaller than the scene frequency result in conventional jaggedness, and we propose to integrate the projected 2D Gaussian within each pixel during testing. This integration is actually a limiting case of super-sampling, which significantly improves anti-aliasing performance over vanilla Gaussian Splatting. Through extensive experiments using various settings and both bounded and unbounded scenes, we show SA-GS performs comparably with or better than Mip-Splatting. Note that super-sampling and integration are only effective when our scale-adaptive filtering is activated. Our codes, data and models are available at https://github.com/zsy1987/SA-GS.
SlimmeRF: Slimmable Radiance Fields
Dec 15, 2023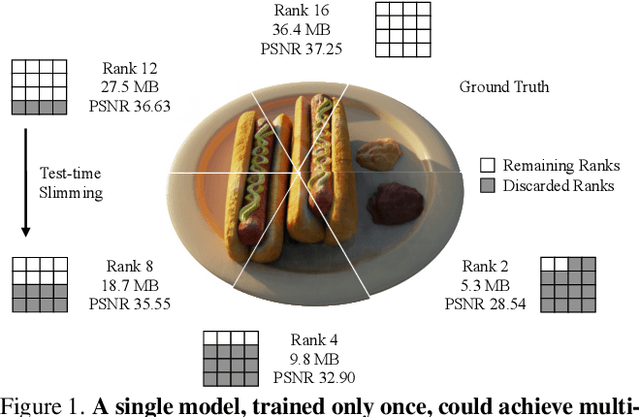

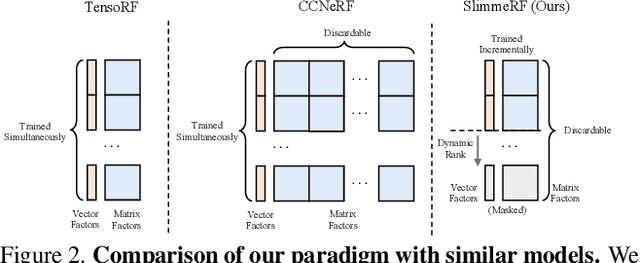
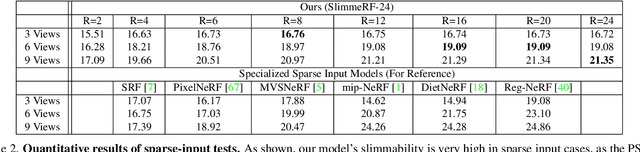
Neural Radiance Field (NeRF) and its variants have recently emerged as successful methods for novel view synthesis and 3D scene reconstruction. However, most current NeRF models either achieve high accuracy using large model sizes, or achieve high memory-efficiency by trading off accuracy. This limits the applicable scope of any single model, since high-accuracy models might not fit in low-memory devices, and memory-efficient models might not satisfy high-quality requirements. To this end, we present SlimmeRF, a model that allows for instant test-time trade-offs between model size and accuracy through slimming, thus making the model simultaneously suitable for scenarios with different computing budgets. We achieve this through a newly proposed algorithm named Tensorial Rank Incrementation (TRaIn) which increases the rank of the model's tensorial representation gradually during training. We also observe that our model allows for more effective trade-offs in sparse-view scenarios, at times even achieving higher accuracy after being slimmed. We credit this to the fact that erroneous information such as floaters tend to be stored in components corresponding to higher ranks. Our implementation is available at https://github.com/Shiran-Yuan/SlimmeRF.
Low-Rank Tensor Completion With Generalized CP Decomposition and Nonnegative Integer Tensor Completion
Feb 12, 2023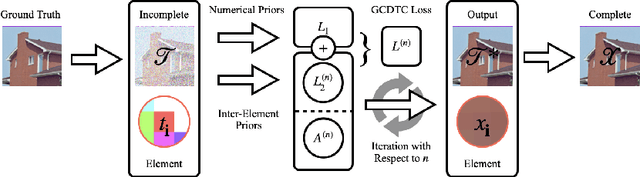
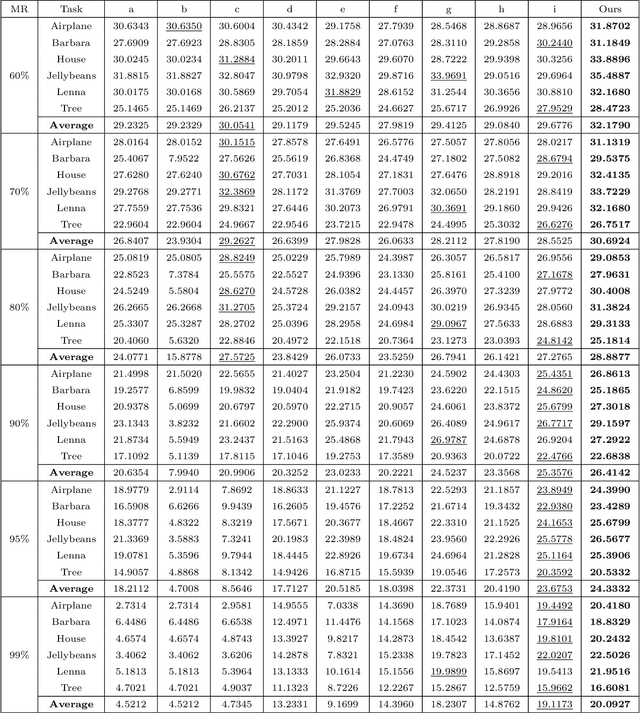
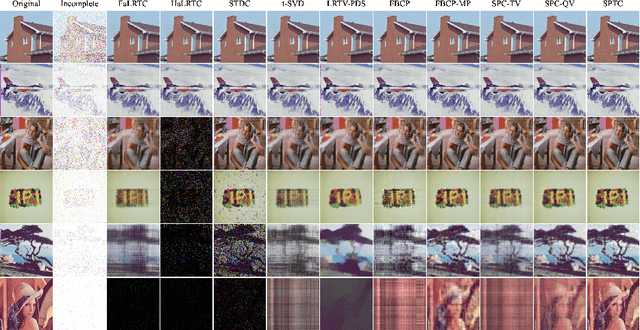

The problem of tensor completion is important to many areas such as computer vision, data analysis, signal processing, etc. Previously, a category of methods known as low-rank tensor completion has been proposed and developed, involving the enforcement of low-rank structures on completed tensors. While such methods have been constantly improved, none have previously considered exploiting the numerical properties of tensor elements. This work attempts to construct a new methodological framework called GCDTC (Generalized CP Decomposition Tensor Completion) based on these properties. In this newly introduced framework, the CP Decomposition is reformulated as a Maximum Likelihood Estimate (MLE) problem, and generalized via the introduction of differing loss functions. The generalized decomposition is subsequently applied to low-rank tensor completion. Such loss functions can also be easily adjusted to consider additional factors in completion, such as smoothness, standardization, etc. An example of nonnegative integer tensor decomposition via the Poisson CP Decomposition is given to demonstrate the new methodology's potentials. Through experimentation with real-life data, it is confirmed that this method could produce results superior to current state-of-the-art methodologies. It is expected that the proposed notion would inspire a new set of tensor completion methods based on the generalization of decompositions, thus contributing to related fields.