 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForge-and-Quench: Enhancing Image Generation for Higher Fidelity in Unified Multimodal Models
Jan 08, 2026Integrating image generation and understanding into a single framework has become a pivotal goal in the multimodal domain. However, how understanding can effectively assist generation has not been fully explored. Unlike previous works that focus on leveraging reasoning abilities and world knowledge from understanding models, this paper introduces a novel perspective: leveraging understanding to enhance the fidelity and detail richness of generated images. To this end, we propose Forge-and-Quench, a new unified framework that puts this principle into practice. In the generation process of our framework, an MLLM first reasons over the entire conversational context, including text instructions, to produce an enhanced text instruction. This refined instruction is then mapped to a virtual visual representation, termed the Bridge Feature, via a novel Bridge Adapter. This feature acts as a crucial link, forging insights from the understanding model to quench and refine the generation process. It is subsequently injected into the T2I backbone as a visual guidance signal, alongside the enhanced text instruction that replaces the original input. To validate this paradigm, we conduct comprehensive studies on the design of the Bridge Feature and Bridge Adapter. Our framework demonstrates exceptional extensibility and flexibility, enabling efficient migration across different MLLM and T2I models with significant savings in training overhead, all without compromising the MLLM's inherent multimodal understanding capabilities. Experiments show that Forge-and-Quench significantly improves image fidelity and detail across multiple models, while also maintaining instruction-following accuracy and enhancing world knowledge application. Models and codes are available at https://github.com/YanbingZeng/Forge-and-Quench.
LongCat-Image Technical Report
Dec 08, 2025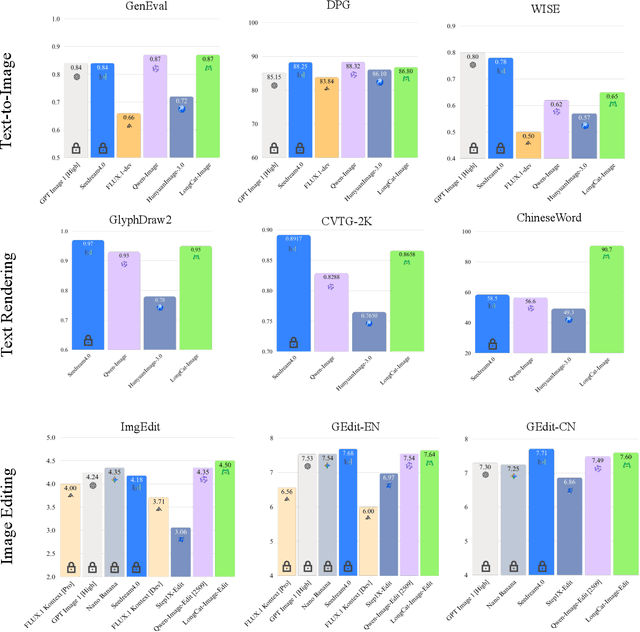
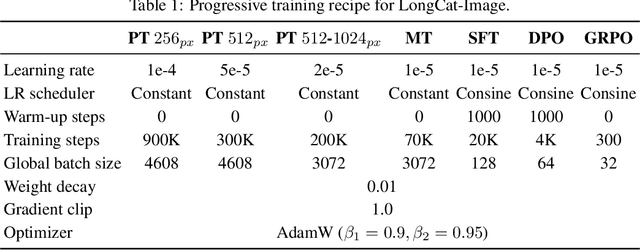

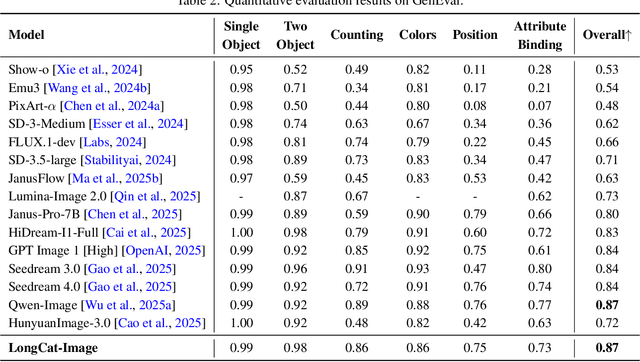
We introduce LongCat-Image, a pioneering open-source and bilingual (Chinese-English) foundation model for image generation, designed to address core challenges in multilingual text rendering, photorealism, deployment efficiency, and developer accessibility prevalent in current leading models. 1) We achieve this through rigorous data curation strategies across the pre-training, mid-training, and SFT stages, complemented by the coordinated use of curated reward models during the RL phase. This strategy establishes the model as a new state-of-the-art (SOTA), delivering superior text-rendering capabilities and remarkable photorealism, and significantly enhancing aesthetic quality. 2) Notably, it sets a new industry standard for Chinese character rendering. By supporting even complex and rare characters, it outperforms both major open-source and commercial solutions in coverage, while also achieving superior accuracy. 3) The model achieves remarkable efficiency through its compact design. With a core diffusion model of only 6B parameters, it is significantly smaller than the nearly 20B or larger Mixture-of-Experts (MoE) architectures common in the field. This ensures minimal VRAM usage and rapid inference, significantly reducing deployment costs. Beyond generation, LongCat-Image also excels in image editing, achieving SOTA results on standard benchmarks with superior editing consistency compared to other open-source works. 4) To fully empower the community, we have established the most comprehensive open-source ecosystem to date. We are releasing not only multiple model versions for text-to-image and image editing, including checkpoints after mid-training and post-training stages, but also the entire toolchain of training procedure. We believe that the openness of LongCat-Image will provide robust support for developers and researchers, pushing the frontiers of visual content creation.
Kangaroo: A Powerful Video-Language Model Supporting Long-context Video Input
Aug 28, 2024



Rapid advancements have been made in extending Large Language Models (LLMs) to Large Multi-modal Models (LMMs). However, extending input modality of LLMs to video data remains a challenging endeavor, especially for long videos. Due to insufficient access to large-scale high-quality video data and the excessive compression of visual features, current methods exhibit limitations in effectively processing long videos. In this paper, we introduce Kangaroo, a powerful Video LMM aimed at addressing these challenges. Confronted with issue of inadequate training data, we develop a data curation system to build a large-scale dataset with high-quality annotations for vision-language pre-training and instruction tuning. In addition, we design a curriculum training pipeline with gradually increasing resolution and number of input frames to accommodate long videos. Evaluation results demonstrate that, with 8B parameters, Kangaroo achieves state-of-the-art performance across a variety of video understanding benchmarks while exhibiting competitive results on others. Particularly, on benchmarks specialized for long videos, Kangaroo excels some larger models with over 10B parameters and proprietary models.