 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoCI-DiffCom: Longitudinal Consistency-Informed Diffusion Model for 3D Infant Brain Image Completion
May 17, 2024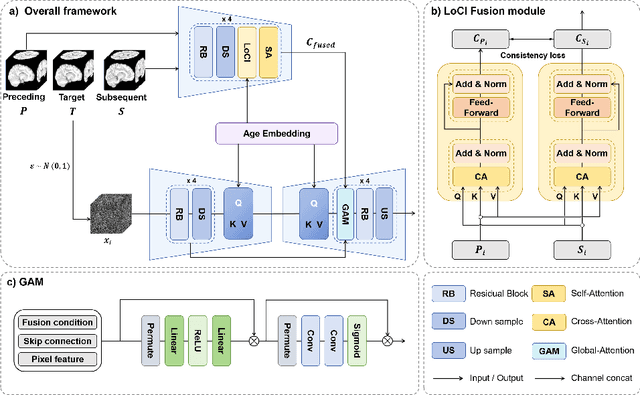
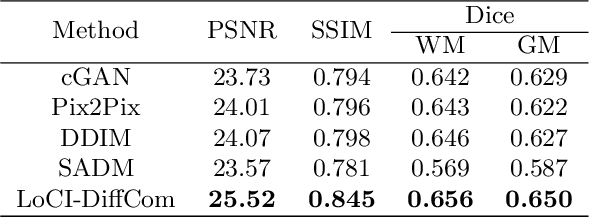
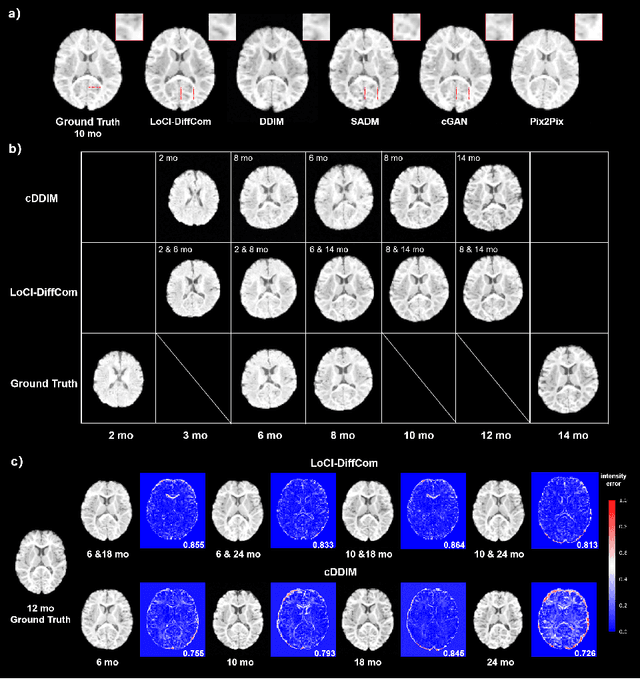
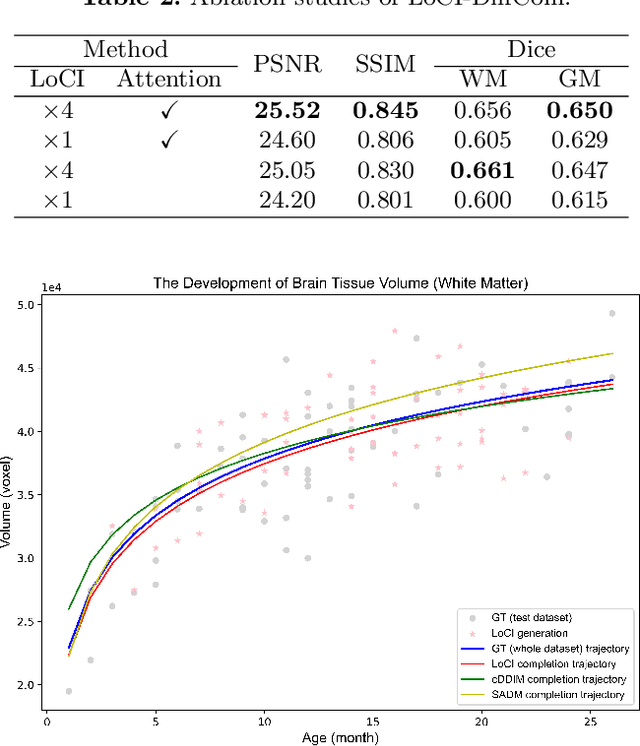
The infant brain undergoes rapid development in the first few years after birth.Compared to cross-sectional studies, longitudinal studies can depict the trajectories of infants brain development with higher accuracy, statistical power and flexibility.However, the collection of infant longitudinal magnetic resonance (MR) data suffers a notorious dropout problem, resulting in incomplete datasets with missing time points. This limitation significantly impedes subsequent neuroscience and clinical modeling. Yet, existing deep generative models are facing difficulties in missing brain image completion, due to sparse data and the nonlinear, dramatic contrast/geometric variations in the developing brain. We propose LoCI-DiffCom, a novel Longitudinal Consistency-Informed Diffusion model for infant brain image Completion,which integrates the images from preceding and subsequent time points to guide a diffusion model for generating high-fidelity missing data. Our designed LoCI module can work on highly sparse sequences, relying solely on data from two temporal points. Despite wide separation and diversity between age time points, our approach can extract individualized developmental features while ensuring context-aware consistency. Our experiments on a large infant brain MR dataset demonstrate its effectiveness with consistent performance on missing infant brain MR completion even in big gap scenarios, aiding in better delineation of early developmental trajectories.
Potential Convolution: Embedding Point Clouds into Potential Fields
Apr 05, 2021

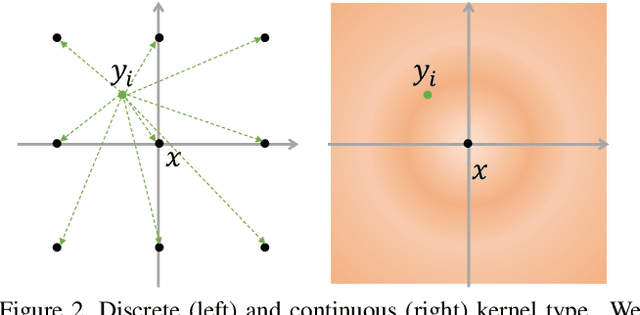
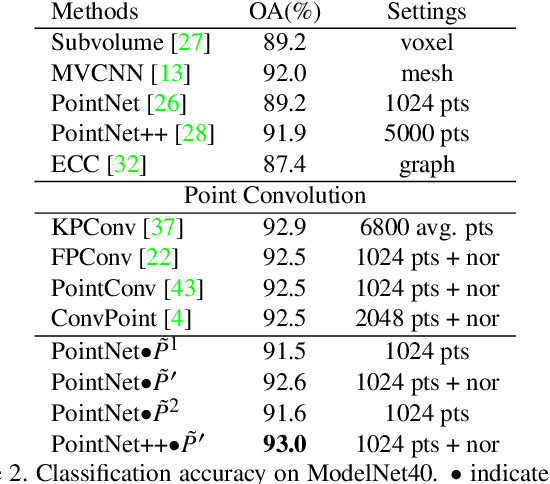
Recently, various convolutions based on continuous or discrete kernels for point cloud processing have been widely studied, and achieve impressive performance in many applications, such as shape classification, scene segmentation and so on. However, they still suffer from some drawbacks. For continuous kernels, the inaccurate estimation of the kernel weights constitutes a bottleneck for further improving the performance; while for discrete ones, the kernels represented as the points located in the 3D space are lack of rich geometry information. In this work, rather than defining a continuous or discrete kernel, we directly embed convolutional kernels into the learnable potential fields, giving rise to potential convolution. It is convenient for us to define various potential functions for potential convolution which can generalize well to a wide range of tasks. Specifically, we provide two simple yet effective potential functions via point-wise convolution operations. Comprehensive experiments demonstrate the effectiveness of our method, which achieves superior performance on the popular 3D shape classification and scene segmentation benchmarks compared with other state-of-the-art point convolution methods.
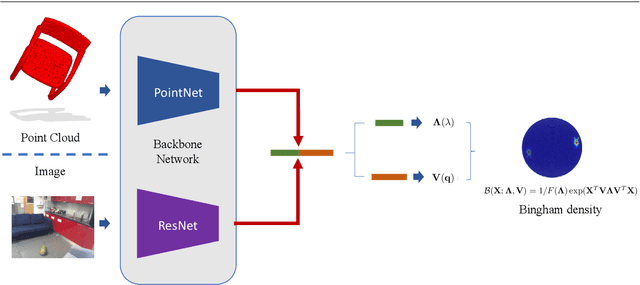
Deep Bingham Networks: Dealing with Uncertainty and Ambiguity in Pose Estimation
Dec 20, 2020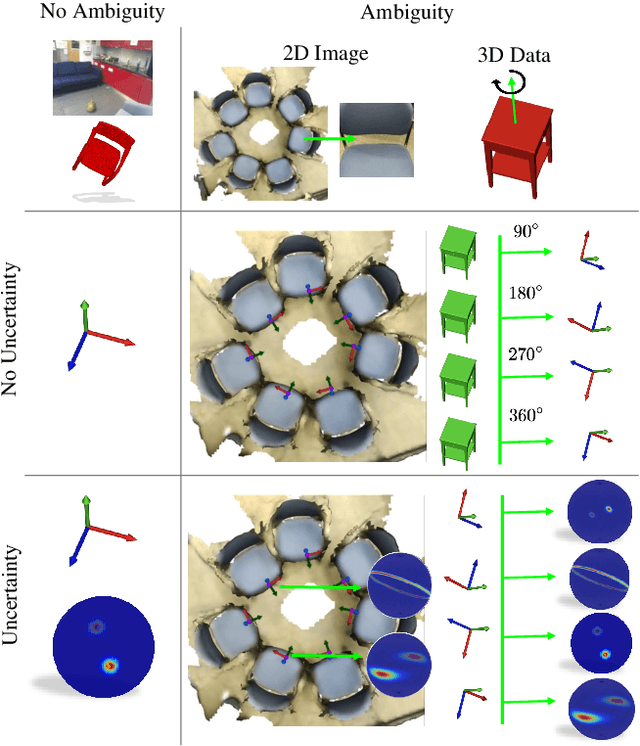

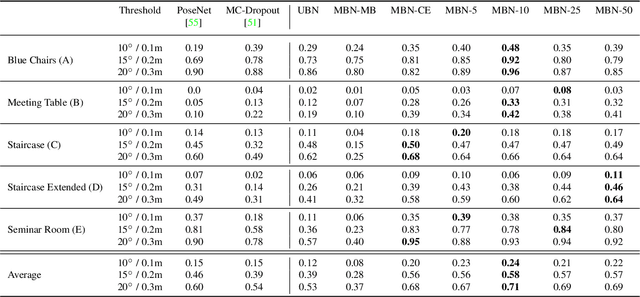
In this work, we introduce Deep Bingham Networks (DBN), a generic framework that can naturally handle pose-related uncertainties and ambiguities arising in almost all real life applications concerning 3D data. While existing works strive to find a single solution to the pose estimation problem, we make peace with the ambiguities causing high uncertainty around which solutions to identify as the best. Instead, we report a family of poses which capture the nature of the solution space. DBN extends the state of the art direct pose regression networks by (i) a multi-hypotheses prediction head which can yield different distribution modes; and (ii) novel loss functions that benefit from Bingham distributions on rotations. This way, DBN can work both in unambiguous cases providing uncertainty information, and in ambiguous scenes where an uncertainty per mode is desired. On a technical front, our network regresses continuous Bingham mixture models and is applicable to both 2D data such as images and to 3D data such as point clouds. We proposed new training strategies so as to avoid mode or posterior collapse during training and to improve numerical stability. Our methods are thoroughly tested on two different applications exploiting two different modalities: (i) 6D camera relocalization from images; and (ii) object pose estimation from 3D point clouds, demonstrating decent advantages over the state of the art. For the former we contributed our own dataset composed of five indoor scenes where it is unavoidable to capture images corresponding to views that are hard to uniquely identify. For the latter we achieve the top results especially for symmetric objects of ModelNet dataset.
6D Camera Relocalization in Ambiguous Scenes via Continuous Multimodal Inference
Apr 09, 2020
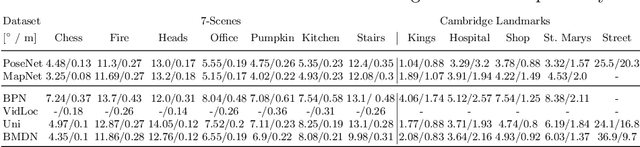

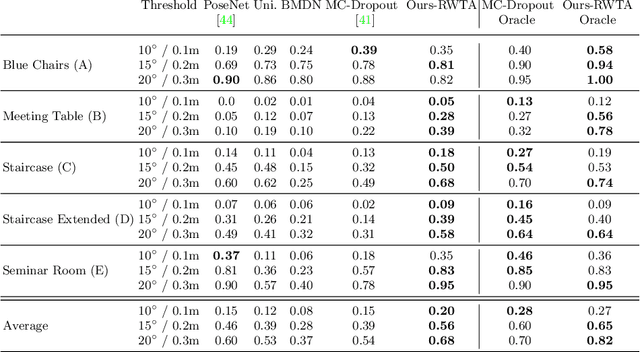
We present a multimodal camera relocalization framework that captures ambiguities and uncertainties with continuous mixture models defined on the manifold of camera poses. In highly ambiguous environments, which can easily arise due to symmetries and repetitive structures in the scene, computing one plausible solution (what most state-of-the-art methods currently regress) may not be sufficient. Instead we predict multiple camera pose hypotheses as well as the respective uncertainty for each prediction. Towards this aim, we use Bingham distributions, to model the orientation of the camera pose, and a multivariate Gaussian to model the position, with an end-to-end deep neural network. By incorporating a Winner-Takes-All training scheme, we finally obtain a mixture model that is well suited for explaining ambiguities in the scene, yet does not suffer from mode collapse, a common problem with mixture density networks. We introduce a new dataset specifically designed to foster camera localization research in ambiguous environments and exhaustively evaluate our method on synthetic as well as real data on both ambiguous scenes and on non-ambiguous benchmark datasets. We plan to release our code and dataset under $\href{https://multimodal3dvision.github.io}{multimodal3dvision.github.io}$.
3D Local Features for Direct Pairwise Registration
Apr 08, 2019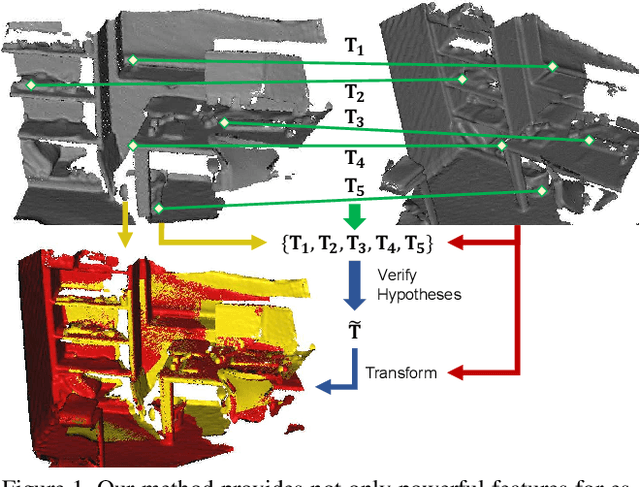

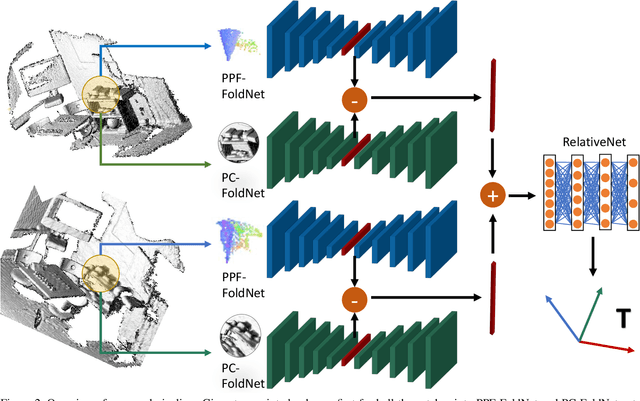
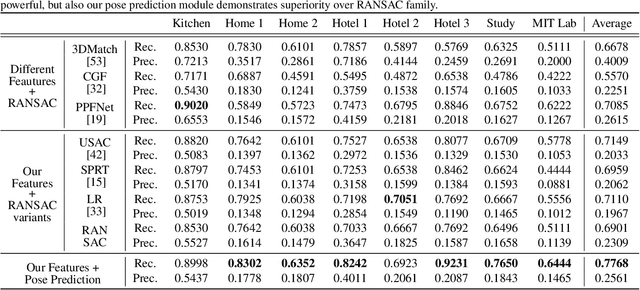
We present a novel, data driven approach for solving the problem of registration of two point cloud scans. Our approach is direct in the sense that a single pair of corresponding local patches already provides the necessary transformation cue for the global registration. To achieve that, we first endow the state of the art PPF-FoldNet auto-encoder (AE) with a pose-variant sibling, where the discrepancy between the two leads to pose-specific descriptors. Based upon this, we introduce RelativeNet, a relative pose estimation network to assign correspondence-specific orientations to the keypoints, eliminating any local reference frame computations. Finally, we devise a simple yet effective hypothesize-and-verify algorithm to quickly use the predictions and align two point sets. Our extensive quantitative and qualitative experiments suggests that our approach outperforms the state of the art in challenging real datasets of pairwise registration and that augmenting the keypoints with local pose information leads to better generalization and a dramatic speed-up.
3D Point-Capsule Networks
Dec 27, 2018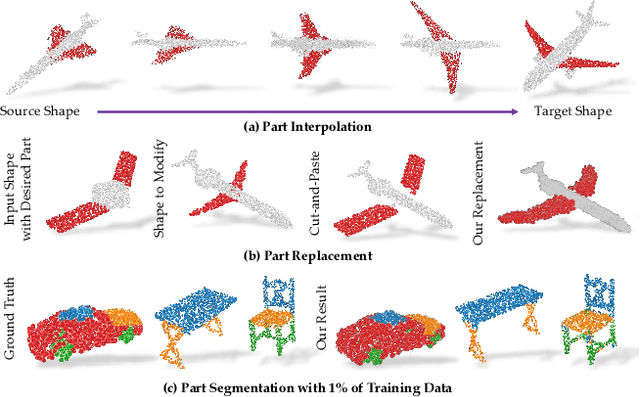
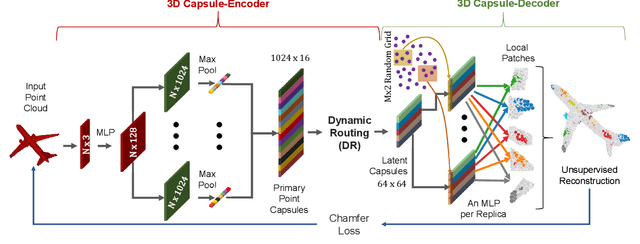

In this paper, we propose 3D point-capsule networks, an auto-encoder designed to process sparse 3D point clouds while preserving spatial arrangements of the input data. 3D capsule networks arise as a direct consequence of our novel unified 3D auto-encoder formulation. Their dynamic routing scheme and the peculiar 2D latent space deployed by our approach bring in improvements for several common point cloud-related tasks, such as object classification, object reconstruction and part segmentation as substantiated by our extensive evaluations. Moreover, it enables new applications such as part interpolation and replacement.
PPF-FoldNet: Unsupervised Learning of Rotation Invariant 3D Local Descriptors
Aug 30, 2018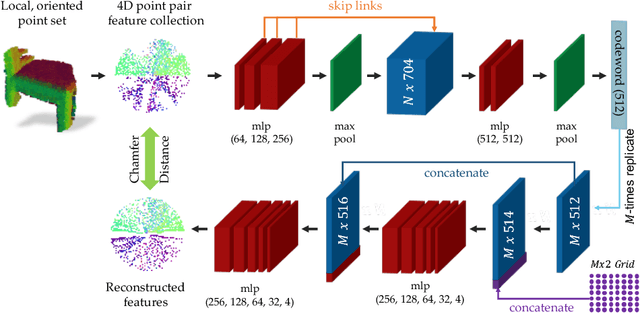
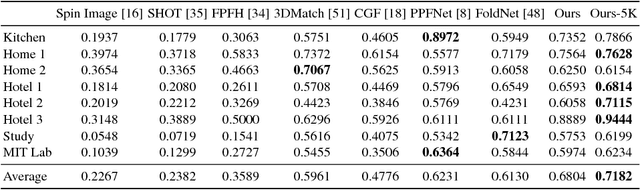


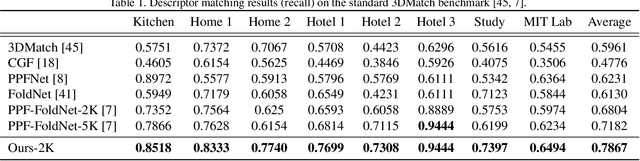
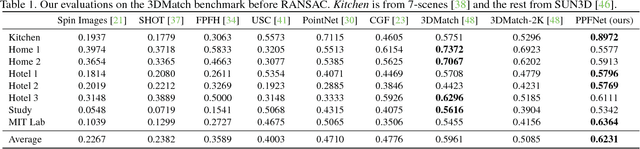
We present PPF-FoldNet for unsupervised learning of 3D local descriptors on pure point cloud geometry. Based on the folding-based auto-encoding of well known point pair features, PPF-FoldNet offers many desirable properties: it necessitates neither supervision, nor a sensitive local reference frame, benefits from point-set sparsity, is end-to-end, fast, and can extract powerful rotation invariant descriptors. Thanks to a novel feature visualization, its evolution can be monitored to provide interpretable insights. Our extensive experiments demonstrate that despite having six degree-of-freedom invariance and lack of training labels, our network achieves state of the art results in standard benchmark datasets and outperforms its competitors when rotations and varying point densities are present. PPF-FoldNet achieves $9\%$ higher recall on standard benchmarks, $23\%$ higher recall when rotations are introduced into the same datasets and finally, a margin of $>35\%$ is attained when point density is significantly decreased.
PPFNet: Global Context Aware Local Features for Robust 3D Point Matching
Mar 01, 2018
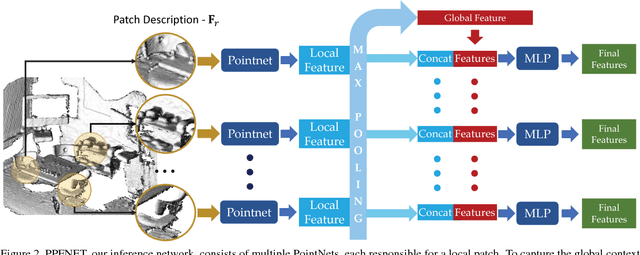

We present PPFNet - Point Pair Feature NETwork for deeply learning a globally informed 3D local feature descriptor to find correspondences in unorganized point clouds. PPFNet learns local descriptors on pure geometry and is highly aware of the global context, an important cue in deep learning. Our 3D representation is computed as a collection of point-pair-features combined with the points and normals within a local vicinity. Our permutation invariant network design is inspired by PointNet and sets PPFNet to be ordering-free. As opposed to voxelization, our method is able to consume raw point clouds to exploit the full sparsity. PPFNet uses a novel $\textit{N-tuple}$ loss and architecture injecting the global information naturally into the local descriptor. It shows that context awareness also boosts the local feature representation. Qualitative and quantitative evaluations of our network suggest increased recall, improved robustness and invariance as well as a vital step in the 3D descriptor extraction performance.