 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time guidewire tracking and segmentation in intraoperative x-ray
Apr 12, 2024During endovascular interventions, physicians have to perform accurate and immediate operations based on the available real-time information, such as the shape and position of guidewires observed on the fluoroscopic images, haptic information and the patients' physiological signals. For this purpose, real-time and accurate guidewire segmentation and tracking can enhance the visualization of guidewires and provide visual feedback for physicians during the intervention as well as for robot-assisted interventions. Nevertheless, this task often comes with the challenge of elongated deformable structures that present themselves with low contrast in the noisy fluoroscopic image sequences. To address these issues, a two-stage deep learning framework for real-time guidewire segmentation and tracking is proposed. In the first stage, a Yolov5s detector is trained, using the original X-ray images as well as synthetic ones, which is employed to output the bounding boxes of possible target guidewires. More importantly, a refinement module based on spatiotemporal constraints is incorporated to robustly localize the guidewire and remove false detections. In the second stage, a novel and efficient network is proposed to segment the guidewire in each detected bounding box. The network contains two major modules, namely a hessian-based enhancement embedding module and a dual self-attention module. Quantitative and qualitative evaluations on clinical intra-operative images demonstrate that the proposed approach significantly outperforms our baselines as well as the current state of the art and, in comparison, shows higher robustness to low quality images.
DistillPose: Lightweight Camera Localization Using Auxiliary Learning
Aug 09, 2021
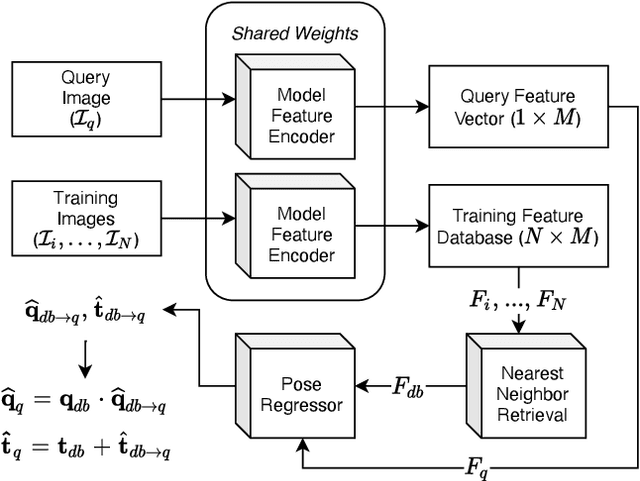
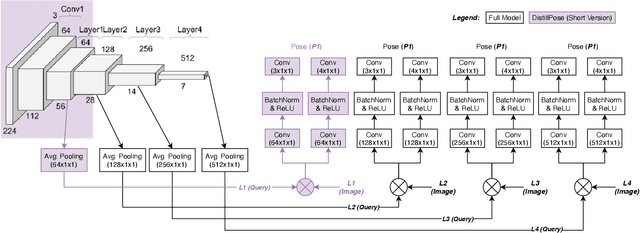
We propose a lightweight retrieval-based pipeline to predict 6DOF camera poses from RGB images. Our pipeline uses a convolutional neural network (CNN) to encode a query image as a feature vector. A nearest neighbor lookup finds the pose-wise nearest database image. A siamese convolutional neural network regresses the relative pose from the nearest neighboring database image to the query image. The relative pose is then applied to the nearest neighboring absolute pose to obtain the query image's final absolute pose prediction. Our model is a distilled version of NN-Net that reduces its parameters by 98.87%, information retrieval feature vector size by 87.5%, and inference time by 89.18% without a significant decrease in localization accuracy.
Deep Bingham Networks: Dealing with Uncertainty and Ambiguity in Pose Estimation
Dec 20, 2020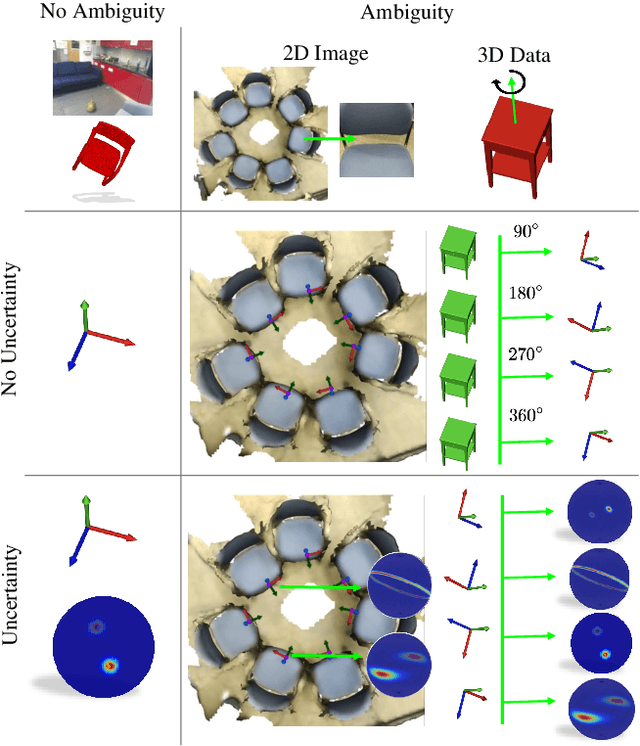

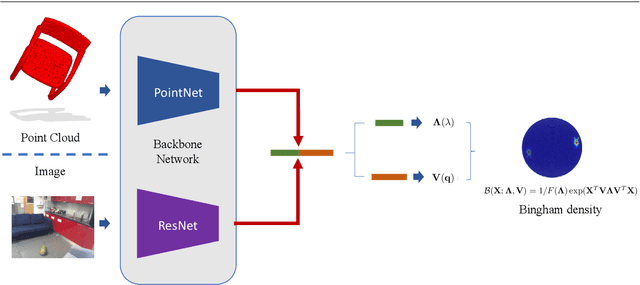
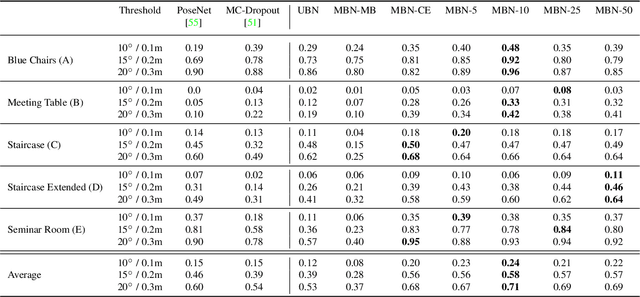
In this work, we introduce Deep Bingham Networks (DBN), a generic framework that can naturally handle pose-related uncertainties and ambiguities arising in almost all real life applications concerning 3D data. While existing works strive to find a single solution to the pose estimation problem, we make peace with the ambiguities causing high uncertainty around which solutions to identify as the best. Instead, we report a family of poses which capture the nature of the solution space. DBN extends the state of the art direct pose regression networks by (i) a multi-hypotheses prediction head which can yield different distribution modes; and (ii) novel loss functions that benefit from Bingham distributions on rotations. This way, DBN can work both in unambiguous cases providing uncertainty information, and in ambiguous scenes where an uncertainty per mode is desired. On a technical front, our network regresses continuous Bingham mixture models and is applicable to both 2D data such as images and to 3D data such as point clouds. We proposed new training strategies so as to avoid mode or posterior collapse during training and to improve numerical stability. Our methods are thoroughly tested on two different applications exploiting two different modalities: (i) 6D camera relocalization from images; and (ii) object pose estimation from 3D point clouds, demonstrating decent advantages over the state of the art. For the former we contributed our own dataset composed of five indoor scenes where it is unavoidable to capture images corresponding to views that are hard to uniquely identify. For the latter we achieve the top results especially for symmetric objects of ModelNet dataset.
6D Camera Relocalization in Ambiguous Scenes via Continuous Multimodal Inference
Apr 09, 2020
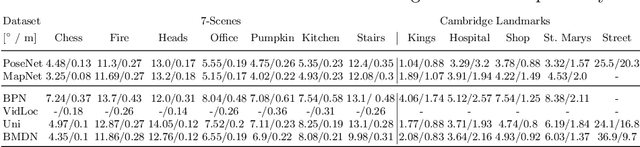

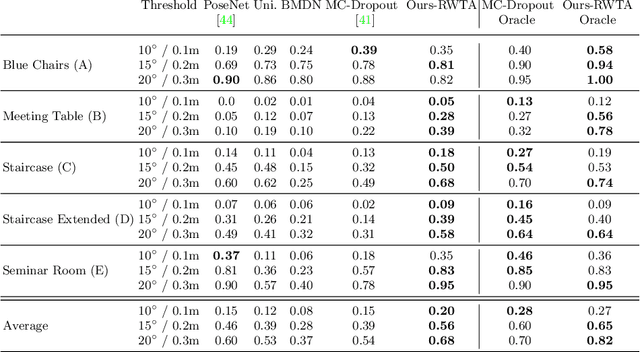
We present a multimodal camera relocalization framework that captures ambiguities and uncertainties with continuous mixture models defined on the manifold of camera poses. In highly ambiguous environments, which can easily arise due to symmetries and repetitive structures in the scene, computing one plausible solution (what most state-of-the-art methods currently regress) may not be sufficient. Instead we predict multiple camera pose hypotheses as well as the respective uncertainty for each prediction. Towards this aim, we use Bingham distributions, to model the orientation of the camera pose, and a multivariate Gaussian to model the position, with an end-to-end deep neural network. By incorporating a Winner-Takes-All training scheme, we finally obtain a mixture model that is well suited for explaining ambiguities in the scene, yet does not suffer from mode collapse, a common problem with mixture density networks. We introduce a new dataset specifically designed to foster camera localization research in ambiguous environments and exhaustively evaluate our method on synthetic as well as real data on both ambiguous scenes and on non-ambiguous benchmark datasets. We plan to release our code and dataset under $\href{https://multimodal3dvision.github.io}{multimodal3dvision.github.io}$.
Adversarial Joint Image and Pose Distribution Learning for Camera Pose Regression and Refinement
Mar 26, 2019

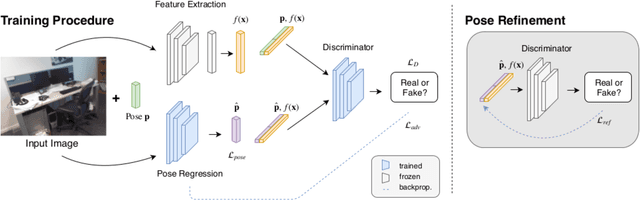

Despite recent advances on the topic of direct camera pose regression using neural networks, accurately estimating the camera pose of a single RGB image still remains a challenging task. To address this problem, we introduce a novel framework based, in its core, on the idea of modeling the joint distribution of RGB images and their corresponding camera poses using adversarial learning. Our method allows not only to regress the camera pose from a single image, however, also offers a solely RGB-based solution for camera pose refinement using the discriminator network. Further, we show that our method can effectively be used to optimize the predicted camera poses and thus improve the localization accuracy. To this end, we validate our proposed method on the publicly available 7-Scenes dataset improving upon the results of current state-of-the-art direct camera pose regression methods.
Scene Coordinate and Correspondence Learning for Image-Based Localization
Jul 26, 2018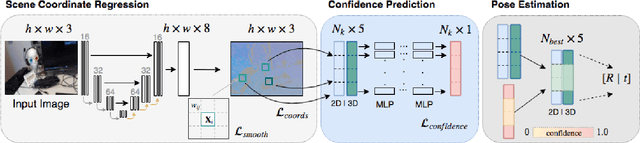
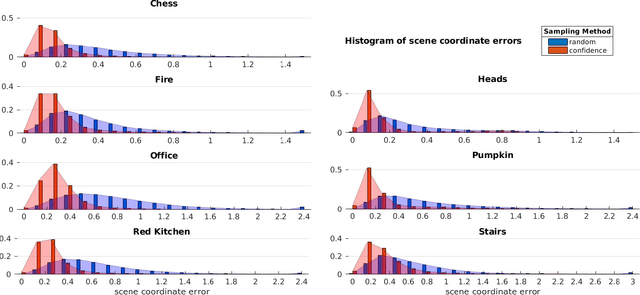

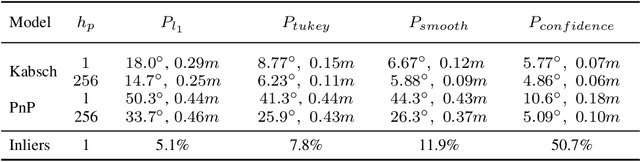
Scene coordinate regression has become an essential part of current camera re-localization methods. Different versions, such as regression forests and deep learning methods, have been successfully applied to estimate the corresponding camera pose given a single input image. In this work, we propose to regress the scene coordinates pixel-wise for a given RGB image by using deep learning. Compared to the recent methods, which usually employ RANSAC to obtain a robust pose estimate from the established point correspondences, we propose to regress confidences of these correspondences, which allows us to immediately discard erroneous predictions and improve the initial pose estimates. Finally, the resulting confidences can be used to score initial pose hypothesis and aid in pose refinement, offering a generalized solution to solve this task.
When Regression Meets Manifold Learning for Object Recognition and Pose Estimation
May 16, 2018
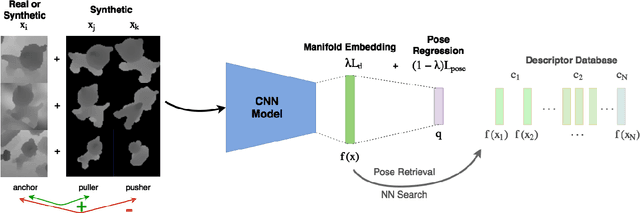
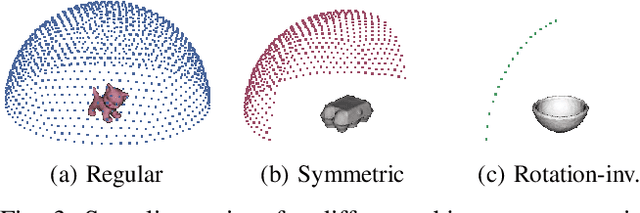
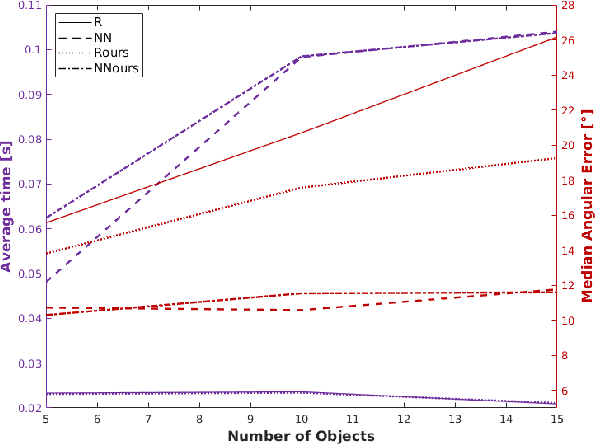
In this work, we propose a method for object recognition and pose estimation from depth images using convolutional neural networks. Previous methods addressing this problem rely on manifold learning to learn low dimensional viewpoint descriptors and employ them in a nearest neighbor search on an estimated descriptor space. In comparison we create an efficient multi-task learning framework combining manifold descriptor learning and pose regression. By combining the strengths of manifold learning using triplet loss and pose regression, we could either estimate the pose directly reducing the complexity compared to NN search, or use learned descriptor for the NN descriptor matching. By in depth experimental evaluation of the novel loss function we observed that the view descriptors learned by the network are much more discriminative resulting in almost 30% increase regarding relative pose accuracy compared to related works. On the other hand, regarding directly regressed poses we obtained important improvement compared to simple pose regression. By leveraging the advantages of both manifold learning and regression tasks, we are able to improve the current state-of-the-art for object recognition and pose retrieval that we demonstrate through in depth experimental evaluation.