 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPA-VGGT:Adapting VGGT to Large Scale Localization by Self-Supervised Learning with Geometry and Physics Aware Loss
Jan 26, 2026Transformer-based general visual geometry frameworks have shown promising performance in camera pose estimation and 3D scene understanding. Recent advancements in Visual Geometry Grounded Transformer (VGGT) models have shown great promise in camera pose estimation and 3D reconstruction. However, these models typically rely on ground truth labels for training, posing challenges when adapting to unlabeled and unseen scenes. In this paper, we propose a self-supervised framework to train VGGT with unlabeled data, thereby enhancing its localization capability in large-scale environments. To achieve this, we extend conventional pair-wise relations to sequence-wise geometric constraints for self-supervised learning. Specifically, in each sequence, we sample multiple source frames and geometrically project them onto different target frames, which improves temporal feature consistency. We formulate physical photometric consistency and geometric constraints as a joint optimization loss to circumvent the requirement for hard labels. By training the model with this proposed method, not only the local and global cross-view attention layers but also the camera and depth heads can effectively capture the underlying multi-view geometry. Experiments demonstrate that the model converges within hundreds of iterations and achieves significant improvements in large-scale localization. Our code will be released at https://github.com/X-yangfan/GPA-VGGT.
VGC-RIO: A Tightly Integrated Radar-Inertial Odometry with Spatial Weighted Doppler Velocity and Local Geometric Constrained RCS Histograms
May 15, 2025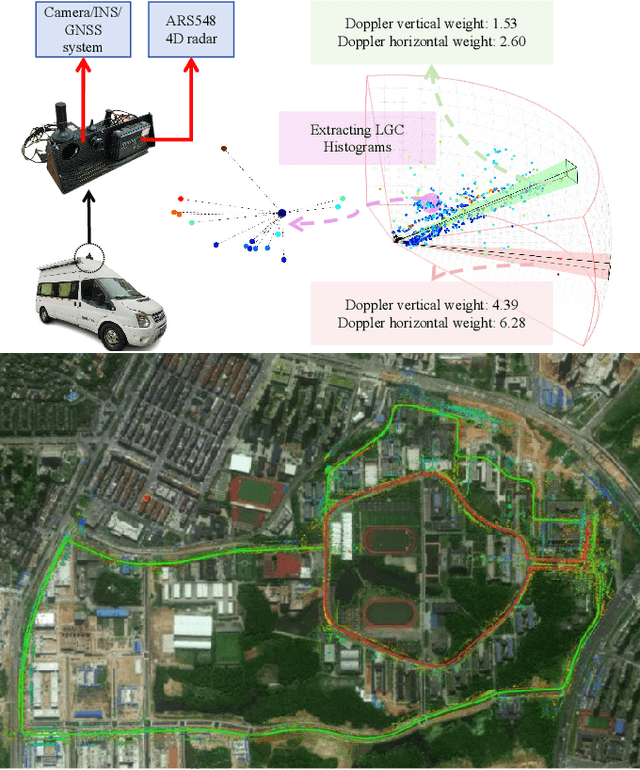
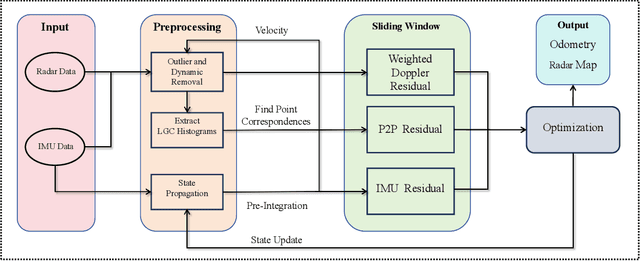
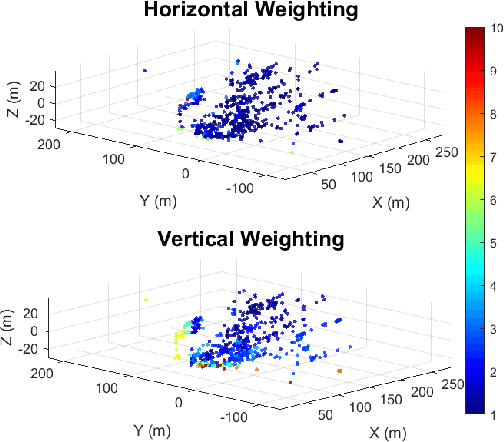
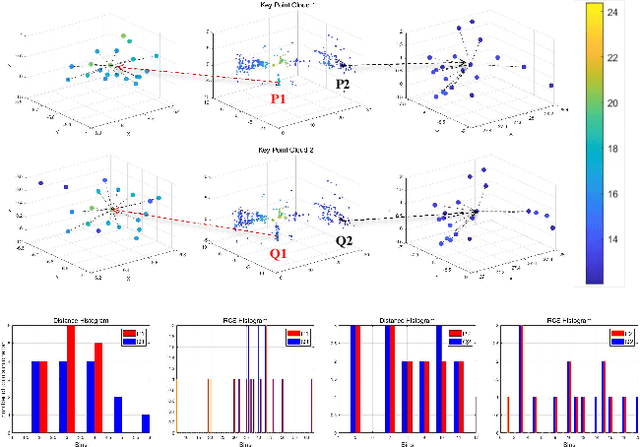
Recent advances in 4D radar-inertial odometry have demonstrated promising potential for autonomous lo calization in adverse conditions. However, effective handling of sparse and noisy radar measurements remains a critical challenge. In this paper, we propose a radar-inertial odometry with a spatial weighting method that adapts to unevenly distributed points and a novel point-description histogram for challenging point registration. To make full use of the Doppler velocity from different spatial sections, we propose a weighting calculation model. To enhance the point cloud registration performance under challenging scenarios, we con struct a novel point histogram descriptor that combines local geometric features and radar cross-section (RCS) features. We have also conducted extensive experiments on both public and self-constructed datasets. The results demonstrate the precision and robustness of the proposed VGC-RIO.
SLAM in the Dark: Self-Supervised Learning of Pose, Depth and Loop-Closure from Thermal Images
Feb 26, 2025



Visual SLAM is essential for mobile robots, drone navigation, and VR/AR, but traditional RGB camera systems struggle in low-light conditions, driving interest in thermal SLAM, which excels in such environments. However, thermal imaging faces challenges like low contrast, high noise, and limited large-scale annotated datasets, restricting the use of deep learning in outdoor scenarios. We present DarkSLAM, a noval deep learning-based monocular thermal SLAM system designed for large-scale localization and reconstruction in complex lighting conditions.Our approach incorporates the Efficient Channel Attention (ECA) mechanism in visual odometry and the Selective Kernel Attention (SKA) mechanism in depth estimation to enhance pose accuracy and mitigate thermal depth degradation. Additionally, the system includes thermal depth-based loop closure detection and pose optimization, ensuring robust performance in low-texture thermal scenes. Extensive outdoor experiments demonstrate that DarkSLAM significantly outperforms existing methods like SC-Sfm-Learner and Shin et al., delivering precise localization and 3D dense mapping even in challenging nighttime environments.
A Polarization Image Dehazing Method Based on the Principle of Physical Diffusion
Nov 15, 2024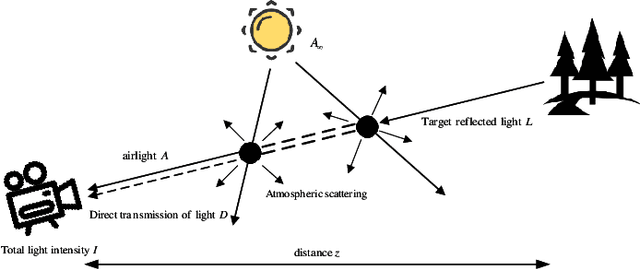
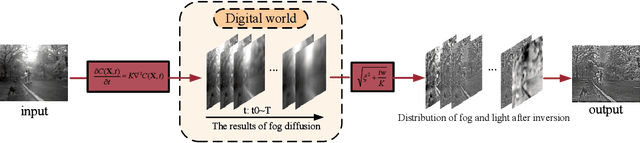


Computer vision is increasingly used in areas such as unmanned vehicles, surveillance systems and remote sensing. However, in foggy scenarios, image degradation leads to loss of target details, which seriously affects the accuracy and effectiveness of these vision tasks. Polarized light, due to the fact that its electromagnetic waves vibrate in a specific direction, is able to resist scattering and refraction effects in complex media more effectively compared to unpolarized light. As a result, polarized light has a greater ability to maintain its polarization characteristics in complex transmission media and under long-distance imaging conditions. This property makes polarized imaging especially suitable for complex scenes such as outdoor and underwater, especially in foggy environments, where higher quality images can be obtained. Based on this advantage, we propose an innovative semi-physical polarization dehazing method that does not rely on an external light source. The method simulates the diffusion process of fog and designs a diffusion kernel that corresponds to the image blurriness caused by this diffusion. By employing spatiotemporal Fourier transforms and deconvolution operations, the method recovers the state of fog droplets prior to diffusion and the light inversion distribution of objects. This approach effectively achieves dehazing and detail enhancement of the scene.
SP-VIO: Robust and Efficient Filter-Based Visual Inertial Odometry with State Transformation Model and Pose-Only Visual Description
Nov 12, 2024



Due to the advantages of high computational efficiency and small memory requirements, filter-based visual inertial odometry (VIO) has a good application prospect in miniaturized and payload-constrained embedded systems. However, the filter-based method has the problem of insufficient accuracy. To this end, we propose the State transformation and Pose-only VIO (SP-VIO) by rebuilding the state and measurement models, and considering further visual deprived conditions. In detail, we first proposed a system model based on the double state transformation extended Kalman filter (DST-EKF), which has been proven to have better observability and consistency than the models based on extended Kalman filter (EKF) and state transformation extended Kalman filter (ST-EKF). Secondly, to reduce the influence of linearization error caused by inaccurate 3D reconstruction, we adopt the Pose-only (PO) theory to decouple the measurement model from 3D features. Moreover, to deal with visual deprived conditions, we propose a double state transformation Rauch-Tung-Striebel (DST-RTS) backtracking method to optimize motion trajectories during visual interruption. Experiments on public (EuRoC, Tum-VI, KITTI) and personal datasets show that SP-VIO has better accuracy and efficiency than state-of-the-art (SOTA) VIO algorithms, and has better robustness under visual deprived conditions.
DK-SLAM: Monocular Visual SLAM with Deep Keypoints Adaptive Learning, Tracking and Loop-Closing
Jan 17, 2024



Unreliable feature extraction and matching in handcrafted features undermine the performance of visual SLAM in complex real-world scenarios. While learned local features, leveraging CNNs, demonstrate proficiency in capturing high-level information and excel in matching benchmarks, they encounter challenges in continuous motion scenes, resulting in poor generalization and impacting loop detection accuracy. To address these issues, we present DK-SLAM, a monocular visual SLAM system with adaptive deep local features. MAML optimizes the training of these features, and we introduce a coarse-to-fine feature tracking approach. Initially, a direct method approximates the relative pose between consecutive frames, followed by a feature matching method for refined pose estimation. To counter cumulative positioning errors, a novel online learning binary feature-based online loop closure module identifies loop nodes within a sequence. Experimental results underscore DK-SLAM's efficacy, outperforms representative SLAM solutions, such as ORB-SLAM3 on publicly available datasets.
Self-supervised Egomotion and Depth Learning via Bi-directional Coarse-to-Fine Scale Recovery
Nov 16, 2022



Self-supervised learning of egomotion and depth has recently attracted great attentions. These learning models can provide pose and depth maps to support navigation and perception task for autonomous driving and robots, while they do not require high-precision ground-truth labels to train the networks. However, monocular vision based methods suffer from pose scale-ambiguity problem, so that can not generate physical meaningful trajectory, and thus their applications are limited in real-world. We propose a novel self-learning deep neural network framework that can learn to estimate egomotion and depths with absolute metric scale from monocular images. Coarse depth scale is recovered via comparing point cloud data against a pretrained model that ensures the consistency of photometric loss. The scale-ambiguity problem is solved by introducing a novel two-stages coarse-to-fine scale recovery strategy that jointly refines coarse poses and depths. Our model successfully produces pose and depth estimates in global scale-metric, even in low-light condition, i.e. driving at night. The evaluation on the public datasets demonstrates that our model outperforms both representative traditional and learning based VOs and VIOs, e.g. VINS-mono, ORB-SLAM, SC-Learner, and UnVIO.
Precise Visual-Inertial Localization for UAV with the Aid of A 2D Georeferenced Map
Jul 13, 2021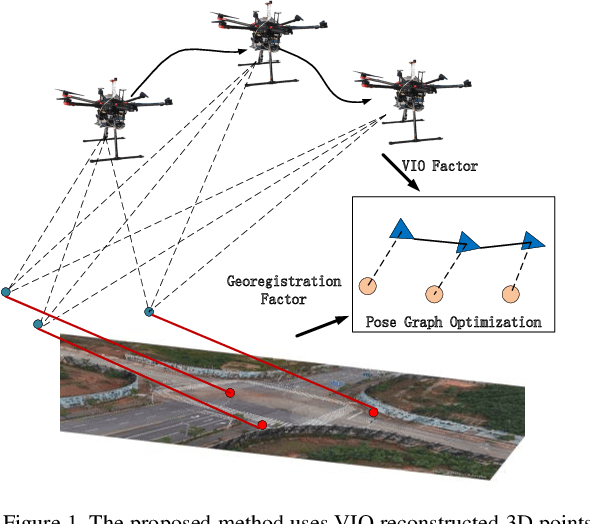
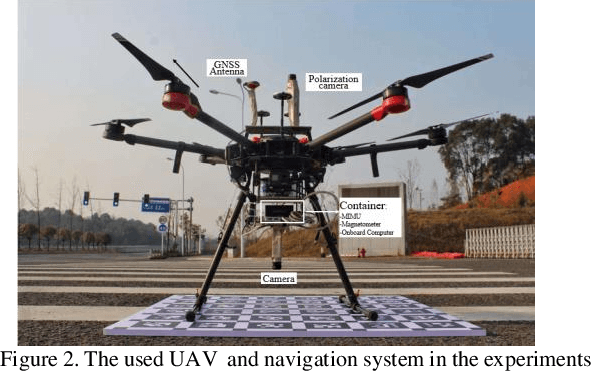
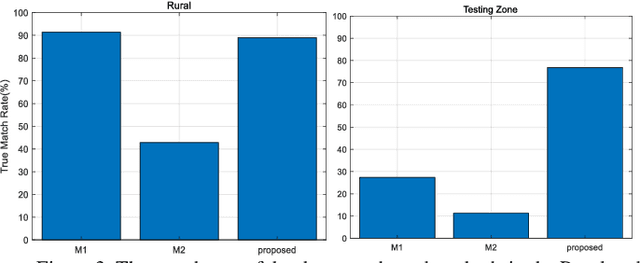

Precise geolocalization is crucial for unmanned aerial vehicles (UAVs). However, most current deployed UAVs rely on the global navigation satellite systems (GNSS) or high precision inertial navigation systems (INS) for geolocalization. In this paper, we propose to use a lightweight visual-inertial system with a 2D georeference map to obtain accurate and consecutive geodetic positions for UAVs. The proposed system firstly integrates a micro inertial measurement unit (MIMU) and a monocular camera as odometry to consecutively estimate the navigation states and reconstruct the 3D position of the observed visual features in the local world frame. To obtain the geolocation, the visual features tracked by the odometry are further registered to the 2D georeferenced map. While most conventional methods perform image-level aerial image registration, we propose to align the reconstructed points to the map points in the geodetic frame; this helps to filter out the large portion of outliers and decouples the negative effects from the horizontal angles. The registered points are then used to relocalize the vehicle in the geodetic frame. Finally, a pose graph is deployed to fuse the geolocation from the aerial image registration and the local navigation result from the visual-inertial odometry (VIO) to achieve consecutive and drift-free geolocalization performance. We have validated the proposed method by installing the sensors to a UAV body rigidly and have conducted two flights in different environments with unknown initials. The results show that the proposed method can achieve less than 4m position error in flight at 100m high and less than 9m position error in flight about 300m high.
A Pose-only Solution to Visual Reconstruction and Navigation
Mar 02, 2021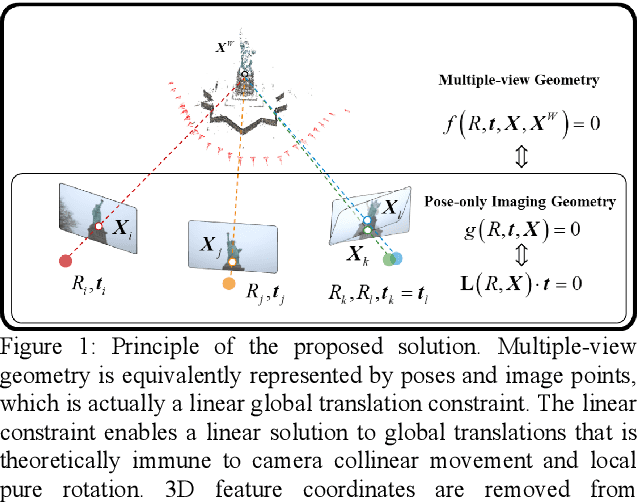
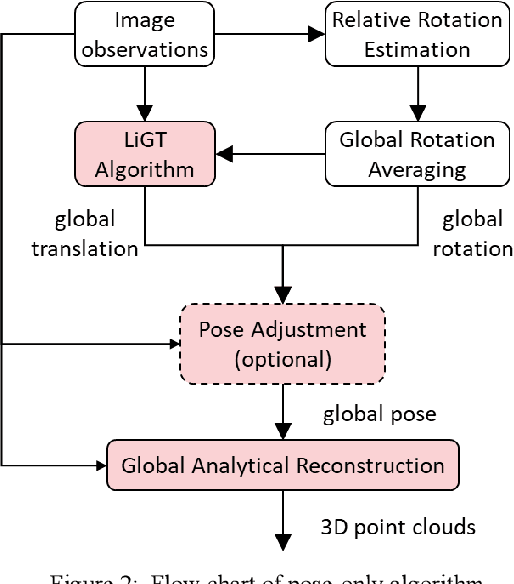
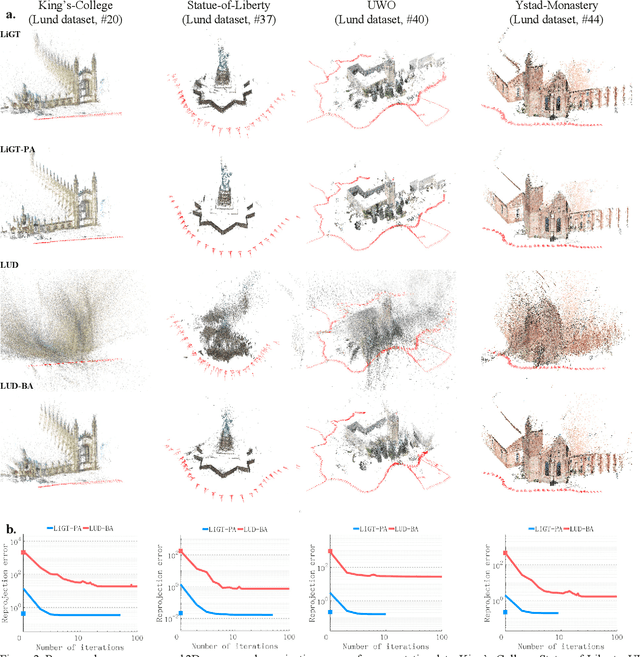

Visual navigation and three-dimensional (3D) scene reconstruction are essential for robotics to interact with the surrounding environment. Large-scale scenes and critical camera motions are great challenges facing the research community to achieve this goal. We raised a pose-only imaging geometry framework and algorithms that can help solve these challenges. The representation is a linear function of camera global translations, which allows for efficient and robust camera motion estimation. As a result, the spatial feature coordinates can be analytically reconstructed and do not require nonlinear optimization. Experiments demonstrate that the computational efficiency of recovering the scene and associated camera poses is significantly improved by 2-4 orders of magnitude. This solution might be promising to unlock real-time 3D visual computing in many forefront applications.
Equivalent Constraints for Two-View Geometry: Pose Solution/Pure Rotation Identification and 3D Reconstruction
Oct 13, 2018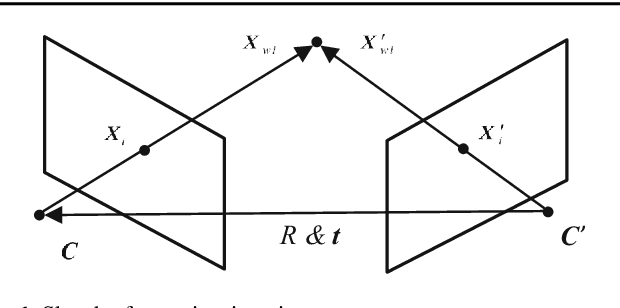



Two-view relative pose estimation and structure reconstruction is a classical problem in computer vision. The typical methods usually employ the singular value decomposition of the essential matrix to get multiple solutions of the relative pose, from which the right solution is picked out by reconstructing the three-dimension (3D) feature points and imposing the constraint of positive depth. This paper revisits the two-view geometry problem and discovers that the two-view imaging geometry is equivalently governed by a Pair of new Pose-Only (PPO) constraints: the same-side constraint and the intersection constraint. From the perspective of solving equation, the complete pose solutions of the essential matrix are explicitly derived and we rigorously prove that the orientation part of the pose can still be recovered in the case of pure rotation. The PPO constraints are simplified and formulated in the form of inequalities to directly identify the right pose solution with no need of 3D reconstruction and the 3D reconstruction can be analytically achieved from the identified right pose. Furthermore, the intersection inequality also enables a robust criterion for pure rotation identification. Experiment results validate the correctness of analyses and the robustness of the derived pose solution/pure rotation identification and analytical 3D reconstruction.