 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemGeoNav:A Safety-Guided Visual Navigation Approach with Semantic Reasoning and Geometric Planning
Jun 15, 2026Learning-based visual navigation has enhanced semantic goal-reaching capabilities. However, due to their black-box nature, purely end-to-end models often lack explicit geometric constraints, leading to unpredictable and unreliable obstacle avoidance in open environments. Conversely, traditional geometric planners ensure safety but struggle with high-dimensional visual targets. To address these limitations, we propose SemGeoNav, a novel hierarchical visual navigation framework.It tightly integrates the high-level semantic reasoning of end-to-end models with the reliable local planning ability of geometry-based methods, achieving robust image-based navigation while significantly improving obstacle avoidance. Furthermore, we introduce a temporal trajectory smoothing mechanism to ensure continuous and stable robot motion. We evaluated SemGeoNav on a Unitree Go2 quadruped robot in real-world environments. The results demonstrate that SemGeoNav outperforms existing representative methods, including ViNT and NoMaD, achieving higher success rates and shorter navigation times.
Improve the autonomy of the SE2(3) group based Extended Kalman Filter for Integrated Navigation: Application
Jan 25, 2026One of the core advantages of SE2(3) Lie group framework for navigation modeling lies in the autonomy of error propagation. In the previous paper, the theoretical analysis of autonomy property of navigation model in inertial, earth and world frames was given. A construction method for SE2(3) group navigation model is proposed to improve the non-inertial navigation model toward full autonomy. This paper serves as a counterpart to previous paper and conducts the real-world strapdown inertial navigation system (SINS)/odometer(ODO) experiments as well as Monte-Carlo simulations to demonstrate the performance of improved SE2(3) group based high-precision navigation models.
ReLoc-PDR: Visual Relocalization Enhanced Pedestrian Dead Reckoning via Graph Optimization
Sep 04, 2023Accurately and reliably positioning pedestrians in satellite-denied conditions remains a significant challenge. Pedestrian dead reckoning (PDR) is commonly employed to estimate pedestrian location using low-cost inertial sensor. However, PDR is susceptible to drift due to sensor noise, incorrect step detection, and inaccurate stride length estimation. This work proposes ReLoc-PDR, a fusion framework combining PDR and visual relocalization using graph optimization. ReLoc-PDR leverages time-correlated visual observations and learned descriptors to achieve robust positioning in visually-degraded environments. A graph optimization-based fusion mechanism with the Tukey kernel effectively corrects cumulative errors and mitigates the impact of abnormal visual observations. Real-world experiments demonstrate that our ReLoc-PDR surpasses representative methods in accuracy and robustness, achieving accurte and robust pedestrian positioning results using only a smartphone in challenging environments such as less-textured corridors and dark nighttime scenarios.
Deep Learning for Inertial Positioning: A Survey
Mar 20, 2023Inertial sensors are widely utilized in smartphones, drones, robots, and IoT devices, playing a crucial role in enabling ubiquitous and reliable localization. Inertial sensor-based positioning is essential in various applications, including personal navigation, location-based security, and human-device interaction. However, low-cost MEMS inertial sensors' measurements are inevitably corrupted by various error sources, leading to unbounded drifts when integrated doubly in traditional inertial navigation algorithms, subjecting inertial positioning to the problem of error drifts. In recent years, with the rapid increase in sensor data and computational power, deep learning techniques have been developed, sparking significant research into addressing the problem of inertial positioning. Relevant literature in this field spans across mobile computing, robotics, and machine learning. In this article, we provide a comprehensive review of deep learning-based inertial positioning and its applications in tracking pedestrians, drones, vehicles, and robots. We connect efforts from different fields and discuss how deep learning can be applied to address issues such as sensor calibration, positioning error drift reduction, and multi-sensor fusion. This article aims to attract readers from various backgrounds, including researchers and practitioners interested in the potential of deep learning-based techniques to solve inertial positioning problems. Our review demonstrates the exciting possibilities that deep learning brings to the table and provides a roadmap for future research in this field.
Self-supervised Egomotion and Depth Learning via Bi-directional Coarse-to-Fine Scale Recovery
Nov 16, 2022



Self-supervised learning of egomotion and depth has recently attracted great attentions. These learning models can provide pose and depth maps to support navigation and perception task for autonomous driving and robots, while they do not require high-precision ground-truth labels to train the networks. However, monocular vision based methods suffer from pose scale-ambiguity problem, so that can not generate physical meaningful trajectory, and thus their applications are limited in real-world. We propose a novel self-learning deep neural network framework that can learn to estimate egomotion and depths with absolute metric scale from monocular images. Coarse depth scale is recovered via comparing point cloud data against a pretrained model that ensures the consistency of photometric loss. The scale-ambiguity problem is solved by introducing a novel two-stages coarse-to-fine scale recovery strategy that jointly refines coarse poses and depths. Our model successfully produces pose and depth estimates in global scale-metric, even in low-light condition, i.e. driving at night. The evaluation on the public datasets demonstrates that our model outperforms both representative traditional and learning based VOs and VIOs, e.g. VINS-mono, ORB-SLAM, SC-Learner, and UnVIO.
EMA-VIO: Deep Visual-Inertial Odometry with External Memory Attention
Sep 18, 2022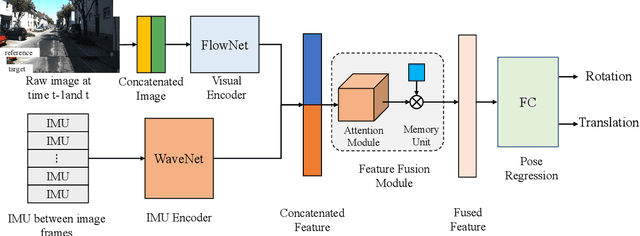
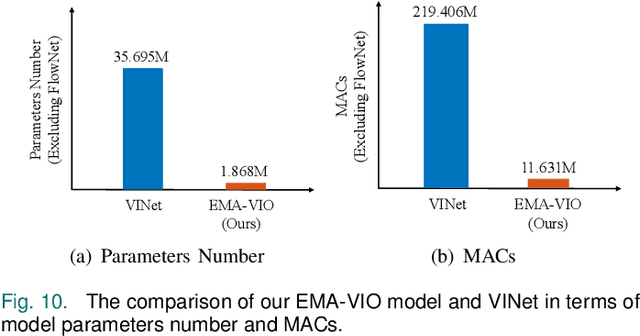
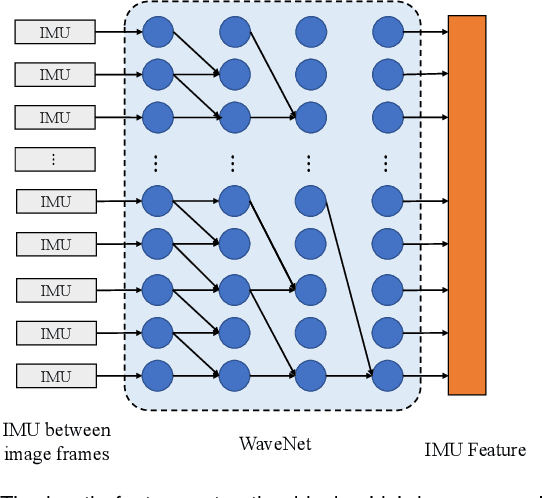
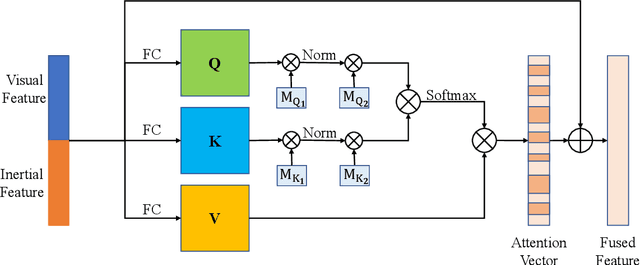
Accurate and robust localization is a fundamental need for mobile agents. Visual-inertial odometry (VIO) algorithms exploit the information from camera and inertial sensors to estimate position and translation. Recent deep learning based VIO models attract attentions as they provide pose information in a data-driven way, without the need of designing hand-crafted algorithms. Existing learning based VIO models rely on recurrent models to fuse multimodal data and process sensor signal, which are hard to train and not efficient enough. We propose a novel learning based VIO framework with external memory attention that effectively and efficiently combines visual and inertial features for states estimation. Our proposed model is able to estimate pose accurately and robustly, even in challenging scenarios, e.g., on overcast days and water-filled ground , which are difficult for traditional VIO algorithms to extract visual features. Experiments validate that it outperforms both traditional and learning based VIO baselines in different scenes.
Underwater Doppler Navigation with Self-calibration
Sep 07, 2015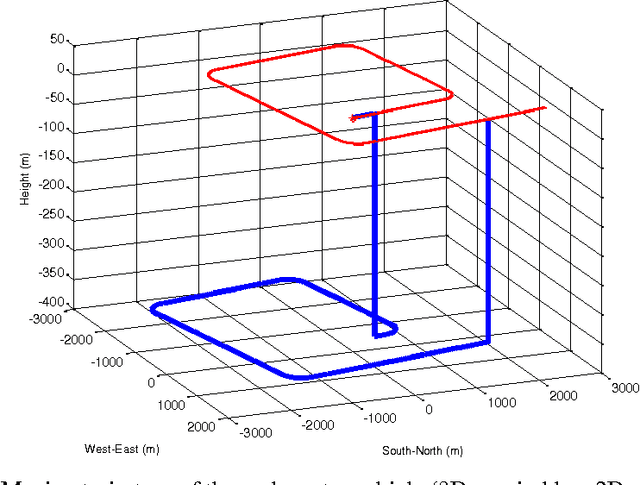

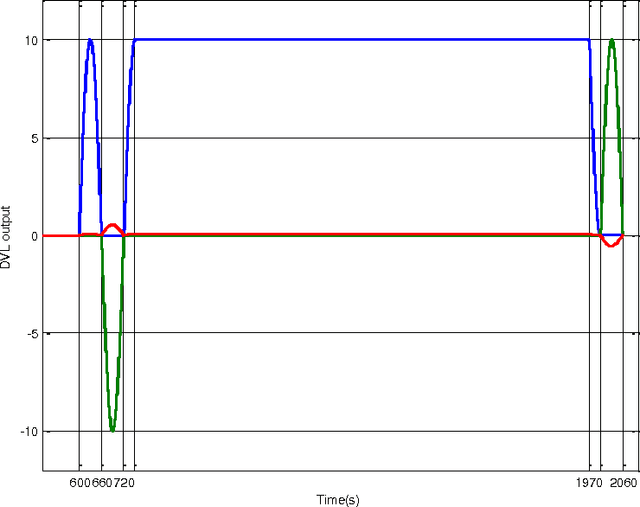
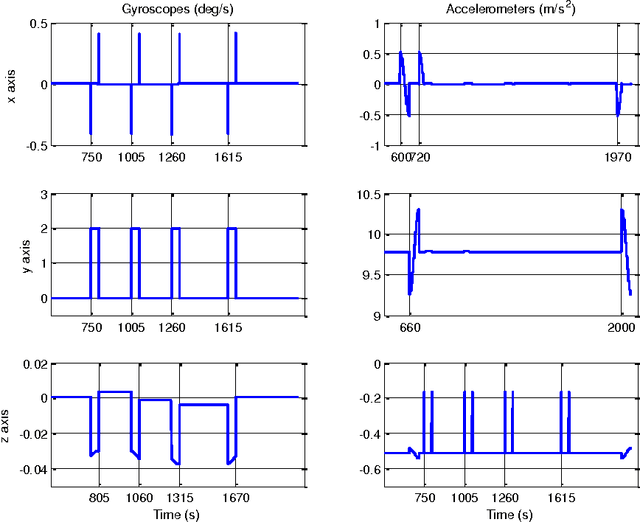
Precise autonomous navigation remains a substantial challenge to all underwater platforms. Inertial Measurement Units (IMU) and Doppler Velocity Logs (DVL) have complementary characteristics and are promising sensors that could enable fully autonomous underwater navigation in unexplored areas without relying on additional external Global Positioning System (GPS) or acoustic beacons. This paper addresses the combined IMU/DVL navigation system from the viewpoint of observability. We show by analysis that under moderate conditions the combined system is observable. Specifically, the DVL parameters, including the scale factor and misalignment angles, can be calibrated in-situ without using external GPS or acoustic beacon sensors. Simulation results using a practical estimator validate the analytic conclusions.
Velocity/Position Integration Formula (II): Application to Inertial Navigation Computation
Jul 06, 2012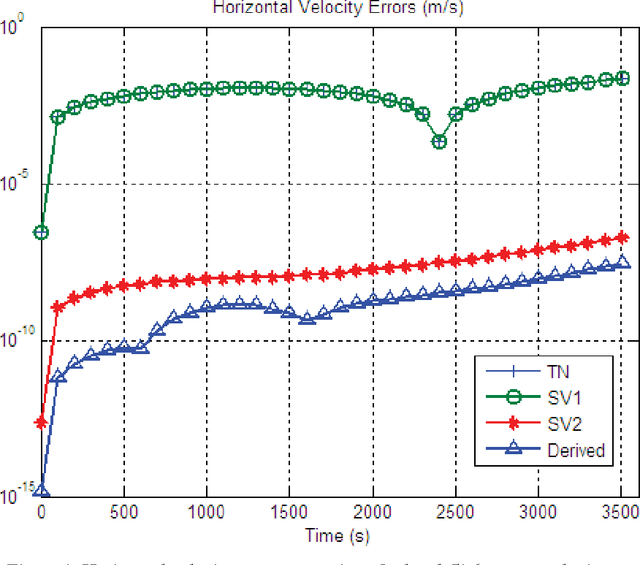
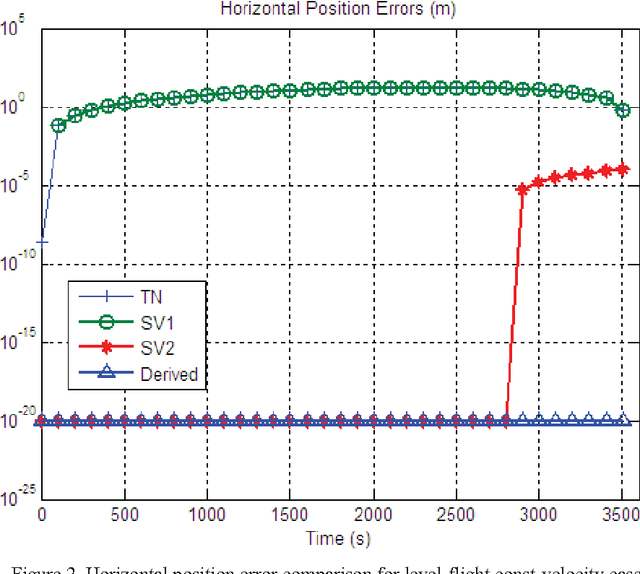
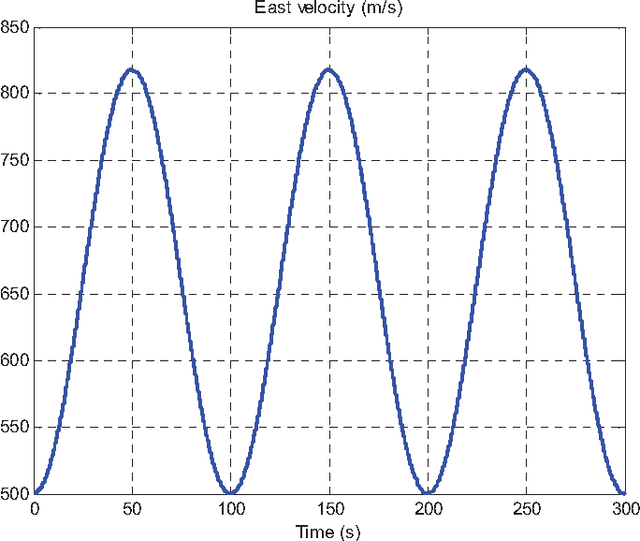
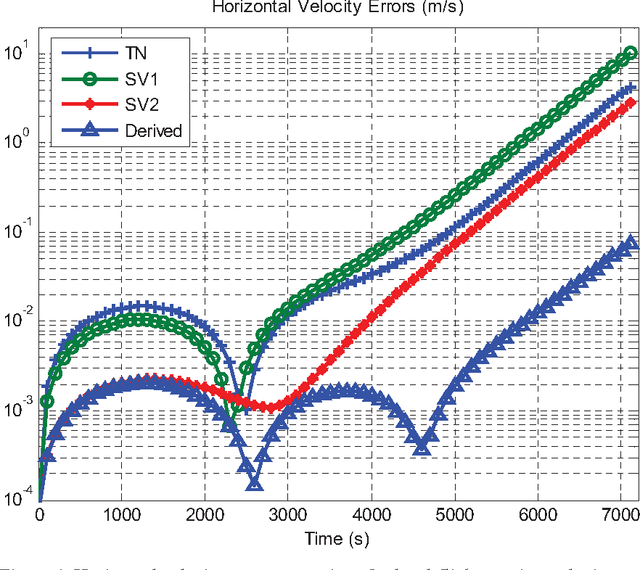
Inertial navigation applications are usually referenced to a rotating frame. Consideration of the navigation reference frame rotation in the inertial navigation algorithm design is an important but so far less seriously treated issue, especially for ultra-high-speed flying aircraft or the future ultra-precision navigation system of several meters per hour. This paper proposes a rigorous approach to tackle the issue of navigation frame rotation in velocity/position computation by use of the newly-devised velocity/position integration formulae in the Part I companion paper. The two integration formulae set a well-founded cornerstone for the velocity/position algorithms design that makes the comprehension of the inertial navigation computation principle more accessible to practitioners, and different approximations to the integrals involved will give birth to various velocity/position update algorithms. Two-sample velocity and position algorithms are derived to exemplify the design process. In the context of level-flight airplane examples, the derived algorithm is analytically and numerically compared to the typical algorithms existing in the literature. The results throw light on the problems in existing algorithms and the potential benefits of the derived algorithm.
* IEEE Trans. on Aerospace and Electronic Systems, in press
Velocity/Position Integration Formula : Application to In-flight Coarse Alignment
Jul 06, 2012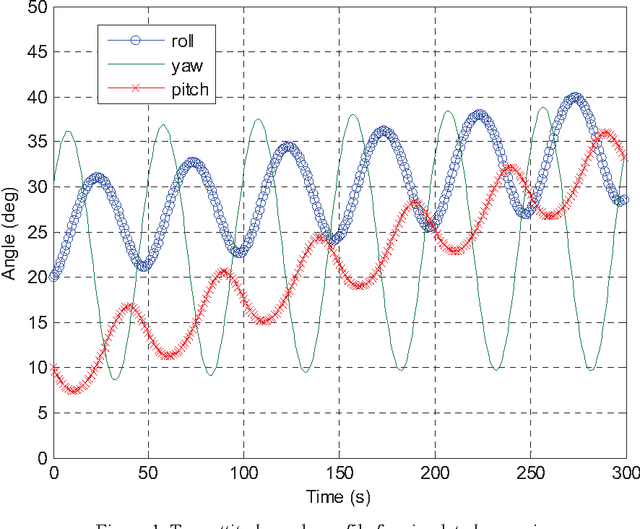
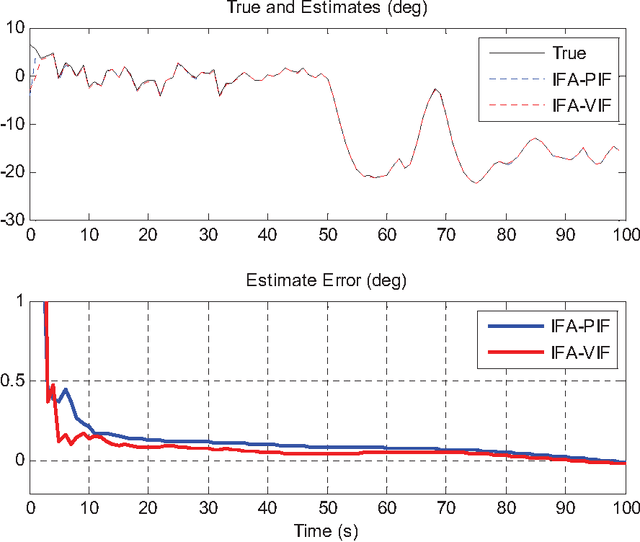
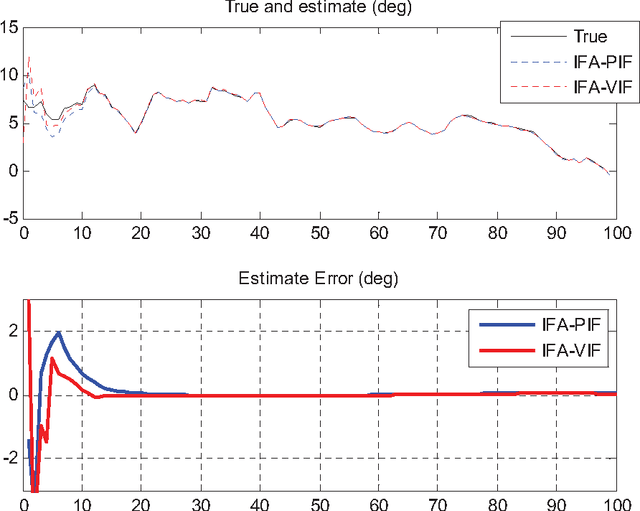
The in-flight alignment is a critical stage for airborne INS/GPS applications. The alignment task is usually carried out by the Kalman filtering technique that necessitates a good initial attitude to obtain satisfying performance. Due to the airborne dynamics, the in-flight alignment is much difficult than alignment on the ground. This paper proposes an optimization-based coarse alignment approach using GPS position/velocity as input, founded on the newly-derived velocity/position integration formulae. Simulation and flight test results show that, with the GPS lever arm well handled, it is potentially able to yield the initial heading up to one degree accuracy in ten seconds. It can serve as a nice coarse in-flight alignment without any prior attitude information for the subsequent fine Kalman alignment. The approach can also be applied to other applications that require aligning the INS on the run.
* IEEE Trans. on Aerospace and Electronic Systems, in press