 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDK-SLAM: Monocular Visual SLAM with Deep Keypoints Adaptive Learning, Tracking and Loop-Closing
Jan 17, 2024



Unreliable feature extraction and matching in handcrafted features undermine the performance of visual SLAM in complex real-world scenarios. While learned local features, leveraging CNNs, demonstrate proficiency in capturing high-level information and excel in matching benchmarks, they encounter challenges in continuous motion scenes, resulting in poor generalization and impacting loop detection accuracy. To address these issues, we present DK-SLAM, a monocular visual SLAM system with adaptive deep local features. MAML optimizes the training of these features, and we introduce a coarse-to-fine feature tracking approach. Initially, a direct method approximates the relative pose between consecutive frames, followed by a feature matching method for refined pose estimation. To counter cumulative positioning errors, a novel online learning binary feature-based online loop closure module identifies loop nodes within a sequence. Experimental results underscore DK-SLAM's efficacy, outperforms representative SLAM solutions, such as ORB-SLAM3 on publicly available datasets.
Self-supervised Egomotion and Depth Learning via Bi-directional Coarse-to-Fine Scale Recovery
Nov 16, 2022



Self-supervised learning of egomotion and depth has recently attracted great attentions. These learning models can provide pose and depth maps to support navigation and perception task for autonomous driving and robots, while they do not require high-precision ground-truth labels to train the networks. However, monocular vision based methods suffer from pose scale-ambiguity problem, so that can not generate physical meaningful trajectory, and thus their applications are limited in real-world. We propose a novel self-learning deep neural network framework that can learn to estimate egomotion and depths with absolute metric scale from monocular images. Coarse depth scale is recovered via comparing point cloud data against a pretrained model that ensures the consistency of photometric loss. The scale-ambiguity problem is solved by introducing a novel two-stages coarse-to-fine scale recovery strategy that jointly refines coarse poses and depths. Our model successfully produces pose and depth estimates in global scale-metric, even in low-light condition, i.e. driving at night. The evaluation on the public datasets demonstrates that our model outperforms both representative traditional and learning based VOs and VIOs, e.g. VINS-mono, ORB-SLAM, SC-Learner, and UnVIO.
Precise Visual-Inertial Localization for UAV with the Aid of A 2D Georeferenced Map
Jul 13, 2021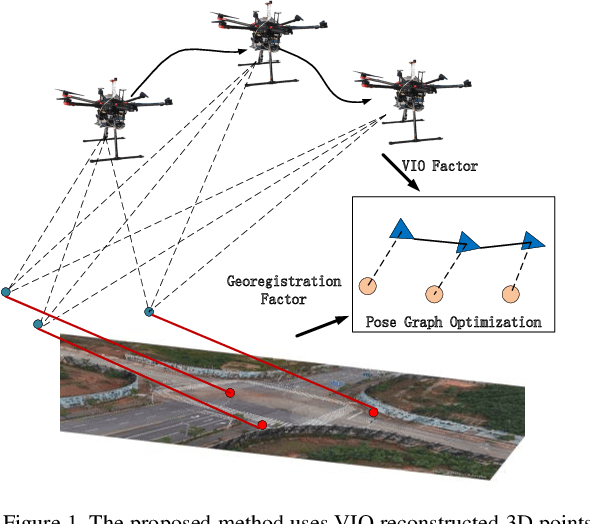
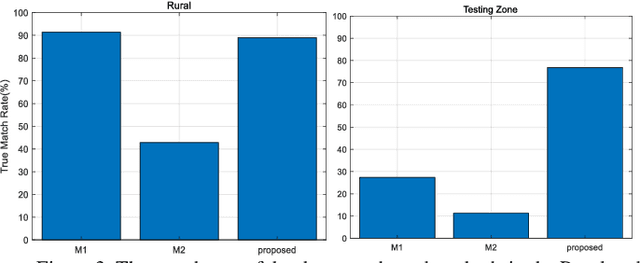

Precise geolocalization is crucial for unmanned aerial vehicles (UAVs). However, most current deployed UAVs rely on the global navigation satellite systems (GNSS) or high precision inertial navigation systems (INS) for geolocalization. In this paper, we propose to use a lightweight visual-inertial system with a 2D georeference map to obtain accurate and consecutive geodetic positions for UAVs. The proposed system firstly integrates a micro inertial measurement unit (MIMU) and a monocular camera as odometry to consecutively estimate the navigation states and reconstruct the 3D position of the observed visual features in the local world frame. To obtain the geolocation, the visual features tracked by the odometry are further registered to the 2D georeferenced map. While most conventional methods perform image-level aerial image registration, we propose to align the reconstructed points to the map points in the geodetic frame; this helps to filter out the large portion of outliers and decouples the negative effects from the horizontal angles. The registered points are then used to relocalize the vehicle in the geodetic frame. Finally, a pose graph is deployed to fuse the geolocation from the aerial image registration and the local navigation result from the visual-inertial odometry (VIO) to achieve consecutive and drift-free geolocalization performance. We have validated the proposed method by installing the sensors to a UAV body rigidly and have conducted two flights in different environments with unknown initials. The results show that the proposed method can achieve less than 4m position error in flight at 100m high and less than 9m position error in flight about 300m high.
Observability of Strapdown INS Alignment: A Global Perspective
Dec 22, 2011

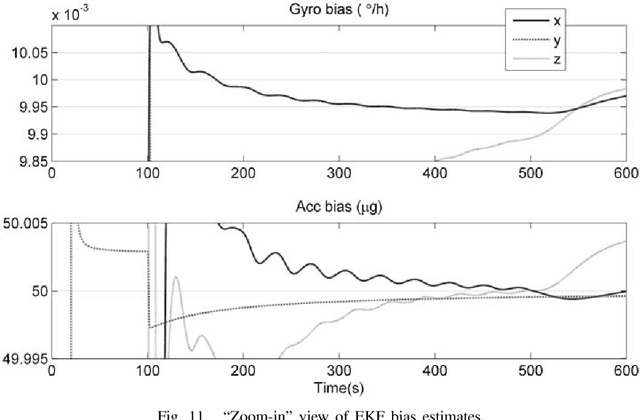
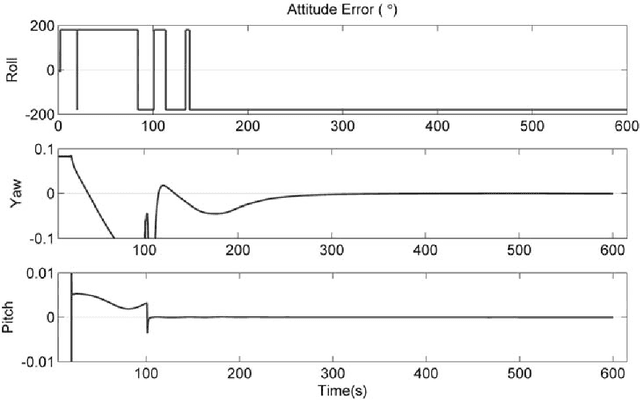
Alignment of the strapdown inertial navigation system (INS) has strong nonlinearity, even worse when maneuvers, e.g., tumbling techniques, are employed to improve the alignment. There is no general rule to attack the observability of a nonlinear system, so most previous works addressed the observability of the corresponding linearized system by implicitly assuming that the original nonlinear system and the linearized one have identical observability characteristics. Strapdown INS alignment is a nonlinear system that has its own characteristics. Using the inherent properties of strapdown INS, e.g., the attitude evolution on the SO(3) manifold, we start from the basic definition and develop a global and constructive approach to investigate the observability of strapdown INS static and tumbling alignment, highlighting the effects of the attitude maneuver on observability. We prove that strapdown INS alignment, considering the unknown constant sensor biases, will be completely observable if the strapdown INS is rotated successively about two different axes and will be nearly observable for finite known unobservable states (no more than two) if it is rotated about a single axis. Observability from a global perspective provides us with insights into and a clearer picture of the problem, shedding light on previous theoretical results on strapdown INS alignment that were not comprehensive or consistent.. The reporting of inconsistencies calls for a review of all linearization-based observability studies in the vast literature. Extensive simulations with constructed ideal observers and an extended Kalman filter are carried out, and the numerical results accord with the analysis. The conclusions can also assist in designing the optimal tumbling strategy and the appropriate state observer in practice to maximize the alignment performance.
* 25 pages; IEEE Trans. on Aerospace and Electronic Systems, Jan. 2012