 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove the autonomy of the SE2(3) group based Extended Kalman Filter for Integrated Navigation: Application
Jan 25, 2026One of the core advantages of SE2(3) Lie group framework for navigation modeling lies in the autonomy of error propagation. In the previous paper, the theoretical analysis of autonomy property of navigation model in inertial, earth and world frames was given. A construction method for SE2(3) group navigation model is proposed to improve the non-inertial navigation model toward full autonomy. This paper serves as a counterpart to previous paper and conducts the real-world strapdown inertial navigation system (SINS)/odometer(ODO) experiments as well as Monte-Carlo simulations to demonstrate the performance of improved SE2(3) group based high-precision navigation models.
EMA-VIO: Deep Visual-Inertial Odometry with External Memory Attention
Sep 18, 2022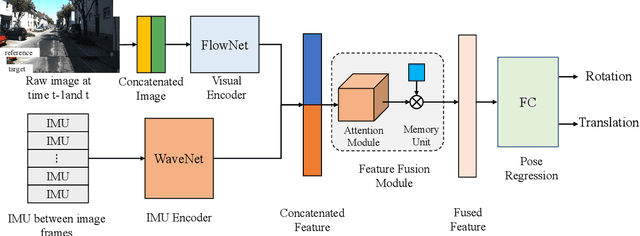
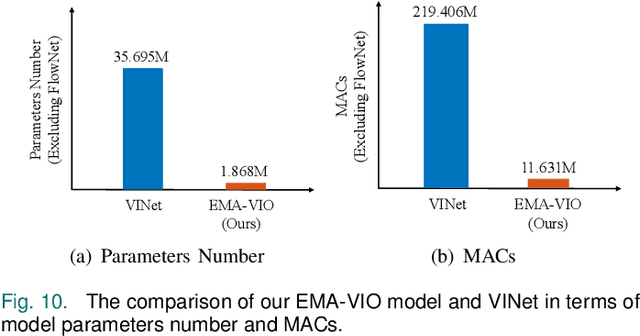
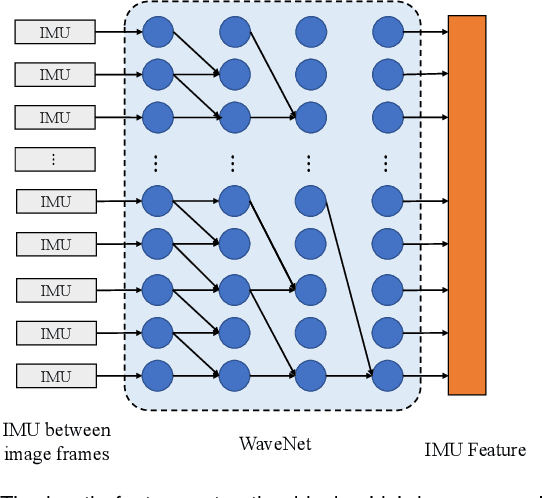
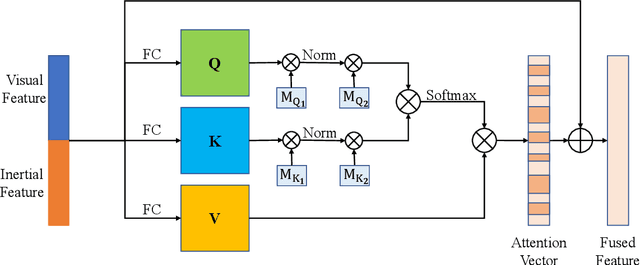
Accurate and robust localization is a fundamental need for mobile agents. Visual-inertial odometry (VIO) algorithms exploit the information from camera and inertial sensors to estimate position and translation. Recent deep learning based VIO models attract attentions as they provide pose information in a data-driven way, without the need of designing hand-crafted algorithms. Existing learning based VIO models rely on recurrent models to fuse multimodal data and process sensor signal, which are hard to train and not efficient enough. We propose a novel learning based VIO framework with external memory attention that effectively and efficiently combines visual and inertial features for states estimation. Our proposed model is able to estimate pose accurately and robustly, even in challenging scenarios, e.g., on overcast days and water-filled ground , which are difficult for traditional VIO algorithms to extract visual features. Experiments validate that it outperforms both traditional and learning based VIO baselines in different scenes.