 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOCS: Semantically-aware Object Coordinate Space for Category-Level 6D Object Pose Estimation under Large Shape Variations
Mar 18, 2023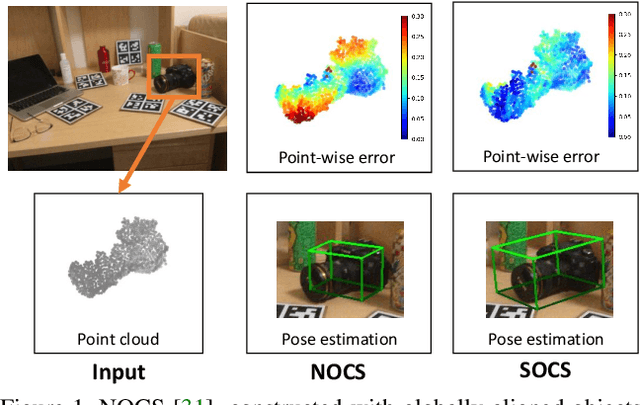
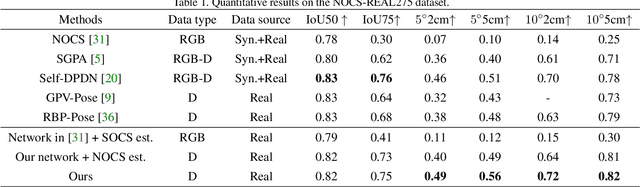
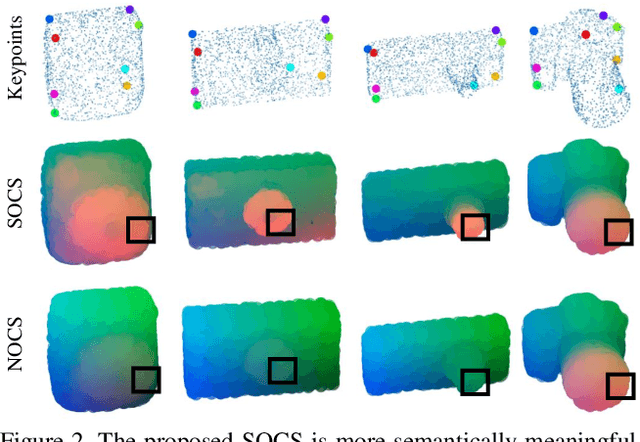
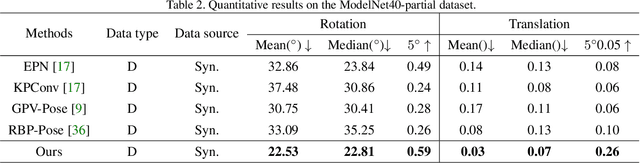
Most learning-based approaches to category-level 6D pose estimation are design around normalized object coordinate space (NOCS). While being successful, NOCS-based methods become inaccurate and less robust when handling objects of a category containing significant intra-category shape variations. This is because the object coordinates induced by global and rigid alignment of objects are semantically incoherent, making the coordinate regression hard to learn and generalize. We propose Semantically-aware Object Coordinate Space (SOCS) built by warping-and-aligning the objects guided by a sparse set of keypoints with semantically meaningful correspondence. SOCS is semantically coherent: Any point on the surface of a object can be mapped to a semantically meaningful location in SOCS, allowing for accurate pose and size estimation under large shape variations. To learn effective coordinate regression to SOCS, we propose a novel multi-scale coordinate-based attention network. Evaluations demonstrate that our method is easy to train, well-generalizing for large intra-category shape variations and robust to inter-object occlusions.
Lexicon-constrained Copying Network for Chinese Abstractive Summarization
Oct 16, 2020
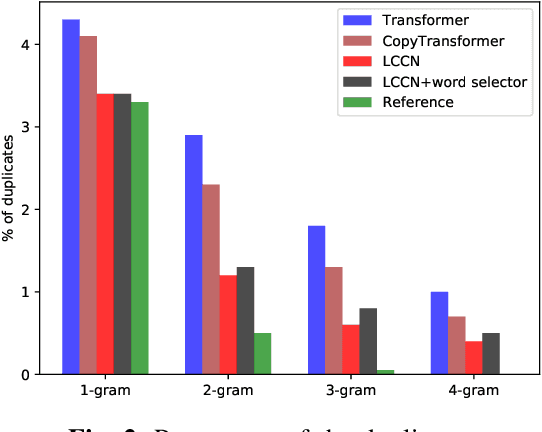

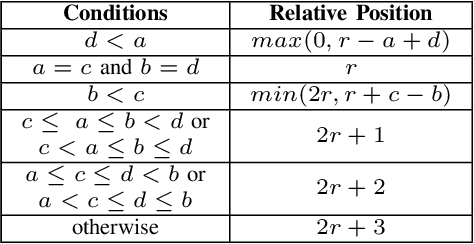
Copy mechanism allows sequence-to-sequence models to choose words from the input and put them directly into the output, which is finding increasing use in abstractive summarization. However, since there is no explicit delimiter in Chinese sentences, most existing models for Chinese abstractive summarization can only perform character copy, resulting in inefficient. To solve this problem, we propose a lexicon-constrained copying network that models multi-granularity in both encoder and decoder. On the source side, words and characters are aggregated into the same input memory using a Transformerbased encoder. On the target side, the decoder can copy either a character or a multi-character word at each time step, and the decoding process is guided by a word-enhanced search algorithm that facilitates the parallel computation and encourages the model to copy more words. Moreover, we adopt a word selector to integrate keyword information. Experiments results on a Chinese social media dataset show that our model can work standalone or with the word selector. Both forms can outperform previous character-based models and achieve competitive performances.