 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexicon-constrained Copying Network for Chinese Abstractive Summarization
Paper and Code
Oct 16, 2020
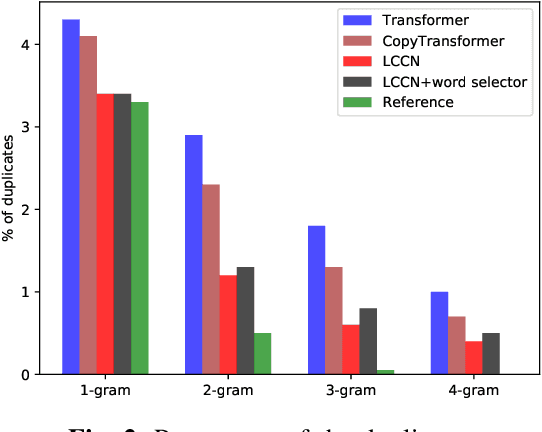

Copy mechanism allows sequence-to-sequence models to choose words from the input and put them directly into the output, which is finding increasing use in abstractive summarization. However, since there is no explicit delimiter in Chinese sentences, most existing models for Chinese abstractive summarization can only perform character copy, resulting in inefficient. To solve this problem, we propose a lexicon-constrained copying network that models multi-granularity in both encoder and decoder. On the source side, words and characters are aggregated into the same input memory using a Transformerbased encoder. On the target side, the decoder can copy either a character or a multi-character word at each time step, and the decoding process is guided by a word-enhanced search algorithm that facilitates the parallel computation and encourages the model to copy more words. Moreover, we adopt a word selector to integrate keyword information. Experiments results on a Chinese social media dataset show that our model can work standalone or with the word selector. Both forms can outperform previous character-based models and achieve competitive performances.