 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training for Unsupervised Parsing with PRPN
Paper and Code


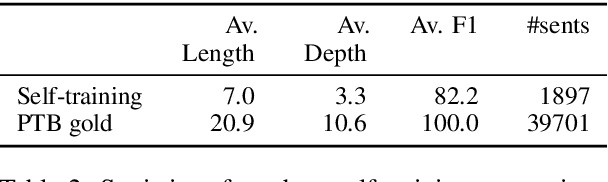

Neural unsupervised parsing (UP) models learn to parse without access to syntactic annotations, while being optimized for another task like language modeling. In this work, we propose self-training for neural UP models: we leverage aggregated annotations predicted by copies of our model as supervision for future copies. To be able to use our model's predictions during training, we extend a recent neural UP architecture, the PRPN (Shen et al., 2018a) such that it can be trained in a semi-supervised fashion. We then add examples with parses predicted by our model to our unlabeled UP training data. Our self-trained model outperforms the PRPN by 8.1% F1 and the previous state of the art by 1.6% F1. In addition, we show that our architecture can also be helpful for semi-supervised parsing in ultra-low-resource settings.