 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Regeneration: How well do LLMs match syntactic properties of text domains?
May 12, 2025Recent improvement in large language model performance have, in all likelihood, been accompanied by improvement in how well they can approximate the distribution of their training data. In this work, we explore the following question: which properties of text domains do LLMs faithfully approximate, and how well do they do so? Applying observational approaches familiar from corpus linguistics, we prompt a commonly used, opensource LLM to regenerate text from two domains of permissively licensed English text which are often contained in LLM training data -- Wikipedia and news text. This regeneration paradigm allows us to investigate whether LLMs can faithfully match the original human text domains in a fairly semantically-controlled setting. We investigate varying levels of syntactic abstraction, from more simple properties like sentence length, and article readability, to more complex and higher order properties such as dependency tag distribution, parse depth, and parse complexity. We find that the majority of the regenerated distributions show a shifted mean, a lower standard deviation, and a reduction of the long tail, as compared to the human originals.
A Word on Machine Ethics: A Response to Jiang et al.
Nov 07, 2021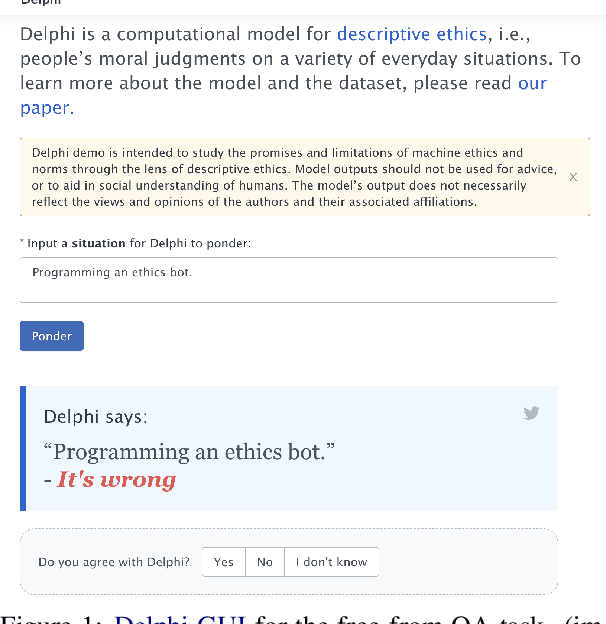

Ethics is one of the longest standing intellectual endeavors of humanity. In recent years, the fields of AI and NLP have attempted to wrangle with how learning systems that interact with humans should be constrained to behave ethically. One proposal in this vein is the construction of morality models that can take in arbitrary text and output a moral judgment about the situation described. In this work, we focus on a single case study of the recently proposed Delphi model and offer a critique of the project's proposed method of automating morality judgments. Through an audit of Delphi, we examine broader issues that would be applicable to any similar attempt. We conclude with a discussion of how machine ethics could usefully proceed, by focusing on current and near-future uses of technology, in a way that centers around transparency, democratic values, and allows for straightforward accountability.
Predicting Declension Class from Form and Meaning
May 28, 2020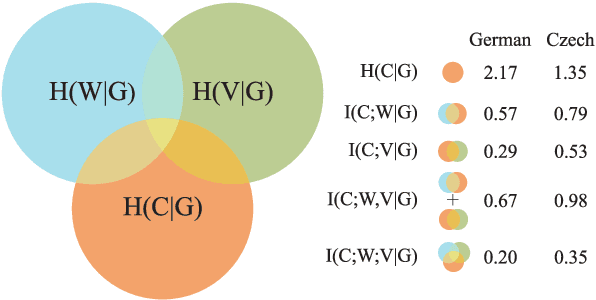


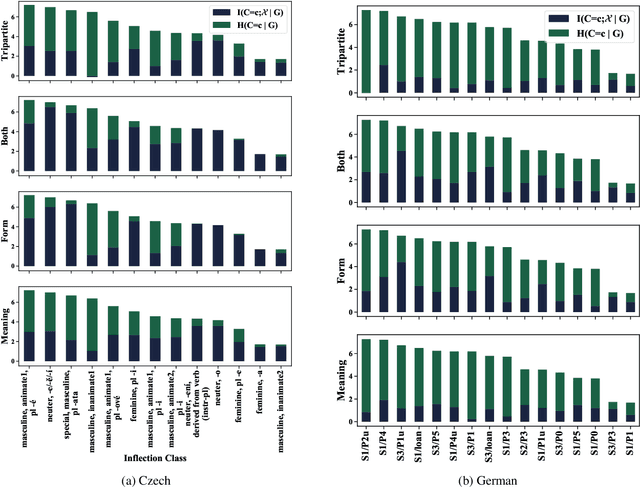
The noun lexica of many natural languages are divided into several declension classes with characteristic morphological properties. Class membership is far from deterministic, but the phonological form of a noun and/or its meaning can often provide imperfect clues. Here, we investigate the strength of those clues. More specifically, we operationalize this by measuring how much information, in bits, we can glean about declension class from knowing the form and/or meaning of nouns. We know that form and meaning are often also indicative of grammatical gender---which, as we quantitatively verify, can itself share information with declension class---so we also control for gender. We find for two Indo-European languages (Czech and German) that form and meaning respectively share significant amounts of information with class (and contribute additional information above and beyond gender). The three-way interaction between class, form, and meaning (given gender) is also significant. Our study is important for two reasons: First, we introduce a new method that provides additional quantitative support for a classic linguistic finding that form and meaning are relevant for the classification of nouns into declensions. Secondly, we show not only that individual declensions classes vary in the strength of their clues within a language, but also that these variations themselves vary across languages.
Investigating BERT's Knowledge of Language: Five Analysis Methods with NPIs
Sep 19, 2019
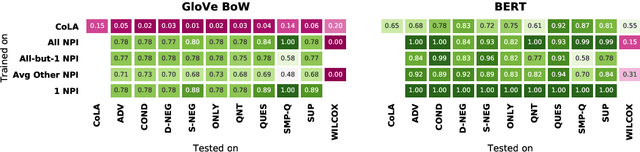

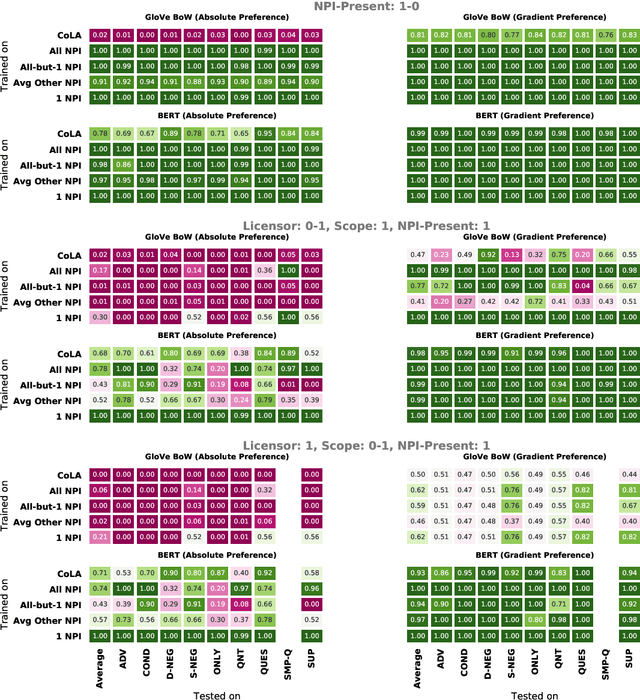
Though state-of-the-art sentence representation models can perform tasks requiring significant knowledge of grammar, it is an open question how best to evaluate their grammatical knowledge. We explore five experimental methods inspired by prior work evaluating pretrained sentence representation models. We use a single linguistic phenomenon, negative polarity item (NPI) licensing in English, as a case study for our experiments. NPIs like "any" are grammatical only if they appear in a licensing environment like negation ("Sue doesn't have any cats" vs. "Sue has any cats"). This phenomenon is challenging because of the variety of NPI licensing environments that exist. We introduce an artificially generated dataset that manipulates key features of NPI licensing for the experiments. We find that BERT has significant knowledge of these features, but its success varies widely across different experimental methods. We conclude that a variety of methods is necessary to reveal all relevant aspects of a model's grammatical knowledge in a given domain.