 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks and Quantifier Conservativity: Does Data Distribution Affect Learnability?
Sep 15, 2018
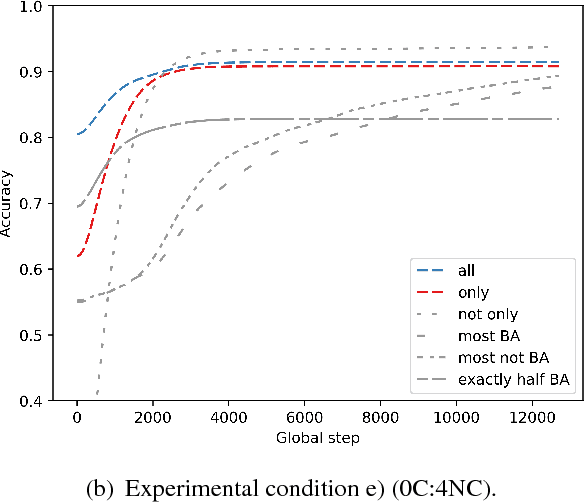
All known natural language determiners are conservative. Psycholinguistic experiments indicate that children exhibit a corresponding learnability bias when faced with the task of learning new determiners. However, recent work indicates that this bias towards conservativity is not observed during the training stage of artificial neural networks. In this work, we investigate whether the learnability bias exhibited by children is in part due to the distribution of quantifiers in natural language. We share results of five experiments, contrasted by the distribution of conservative vs. non-conservative determiners in the training data. We demonstrate that the aquisitional issues with non-conservative quantifiers can not be explained by the distribution of natural language data, which favors conservative quantifiers. This finding indicates that the bias in language acquisition data might be innate or representational.