 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-DPO: Improving Data Utilization in Direct Preference Optimization Using a Guiding Reference Model
Apr 22, 2025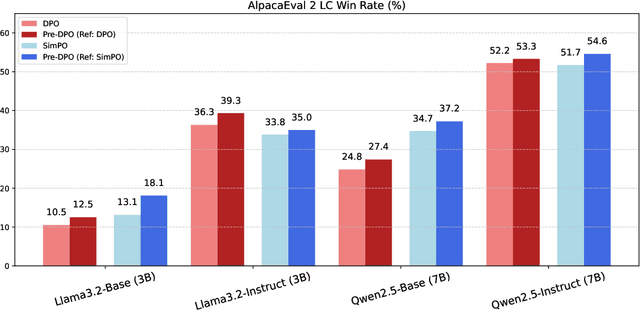
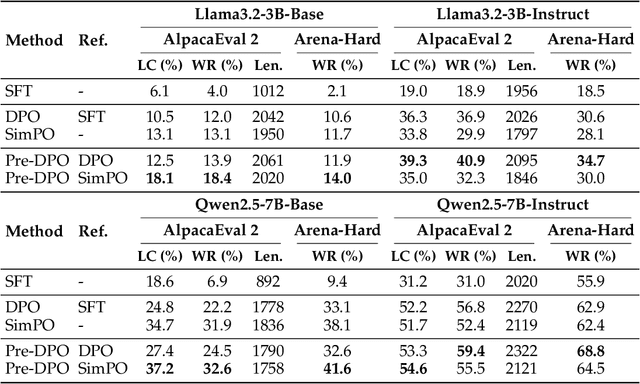
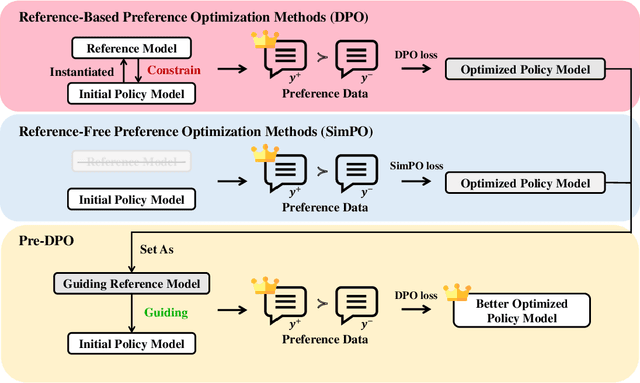
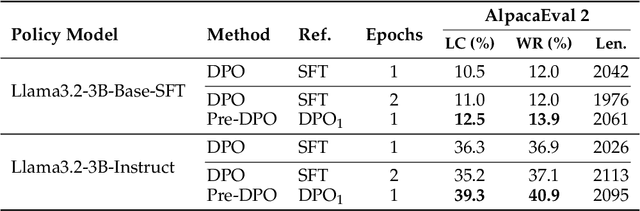
Direct Preference Optimization (DPO) simplifies reinforcement learning from human feedback (RLHF) for large language models (LLMs) by directly optimizing human preferences without an explicit reward model. We find that during DPO training, the reference model plays the role of a data weight adjuster. However, the common practice of initializing the policy and reference models identically in DPO can lead to inefficient data utilization and impose a performance ceiling. Meanwhile, the lack of a reference model in Simple Preference Optimization (SimPO) reduces training robustness and necessitates stricter conditions to prevent catastrophic forgetting. In this work, we propose Pre-DPO, a simple yet effective DPO-based training paradigm that enhances preference optimization performance by leveraging a guiding reference model. This reference model provides foresight into the optimal policy state achievable through the training preference data, serving as a guiding mechanism that adaptively assigns higher weights to samples more suitable for the model and lower weights to those less suitable. Extensive experiments on AlpacaEval 2.0 and Arena-Hard v0.1 benchmarks demonstrate that Pre-DPO consistently improves the performance of both DPO and SimPO, without relying on external models or additional data.
Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese
Nov 03, 2022



The tremendous success of CLIP (Radford et al., 2021) has promoted the research and application of contrastive learning for vision-language pretraining. In this work, we construct a large-scale dataset of image-text pairs in Chinese, where most data are retrieved from publicly available datasets, and we pretrain Chinese CLIP models on the new dataset. We develop 5 Chinese CLIP models of multiple sizes, spanning from 77 to 958 million parameters. Furthermore, we propose a two-stage pretraining method, where the model is first trained with the image encoder frozen and then trained with all parameters being optimized, to achieve enhanced model performance. Our comprehensive experiments demonstrate that Chinese CLIP can achieve the state-of-the-art performance on MUGE, Flickr30K-CN, and COCO-CN in the setups of zero-shot learning and finetuning, and it is able to achieve competitive performance in zero-shot image classification based on the evaluation on the ELEVATER benchmark (Li et al., 2022). We have released our codes, models, and demos in https://github.com/OFA-Sys/Chinese-CLIP
Hierarchical Cross-Modality Semantic Correlation Learning Model for Multimodal Summarization
Dec 16, 2021



Multimodal summarization with multimodal output (MSMO) generates a summary with both textual and visual content. Multimodal news report contains heterogeneous contents, which makes MSMO nontrivial. Moreover, it is observed that different modalities of data in the news report correlate hierarchically. Traditional MSMO methods indistinguishably handle different modalities of data by learning a representation for the whole data, which is not directly adaptable to the heterogeneous contents and hierarchical correlation. In this paper, we propose a hierarchical cross-modality semantic correlation learning model (HCSCL) to learn the intra- and inter-modal correlation existing in the multimodal data. HCSCL adopts a graph network to encode the intra-modal correlation. Then, a hierarchical fusion framework is proposed to learn the hierarchical correlation between text and images. Furthermore, we construct a new dataset with relevant image annotation and image object label information to provide the supervision information for the learning procedure. Extensive experiments on the dataset show that HCSCL significantly outperforms the baseline methods in automatic summarization metrics and fine-grained diversity tests.