 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2GenCSR: Retrieving Context Samples for Large Language Model based X-ray Medical Report Generation
Paper and Code
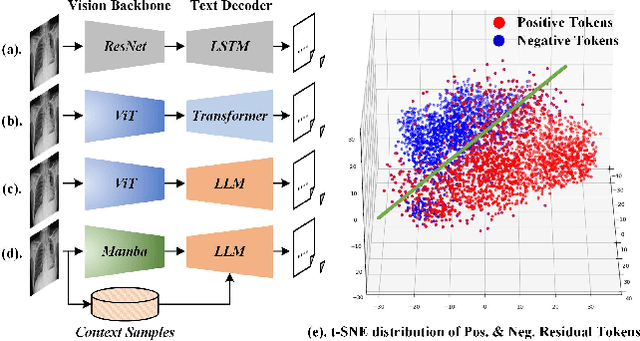
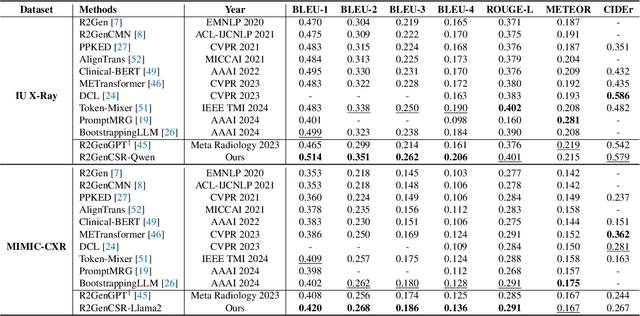
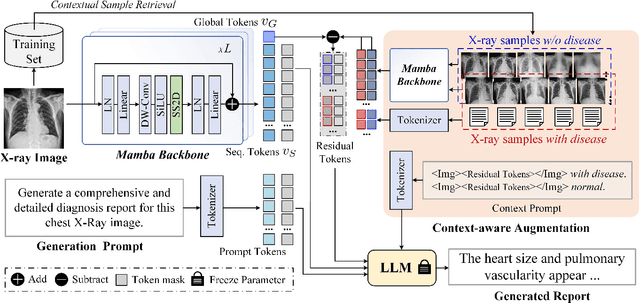
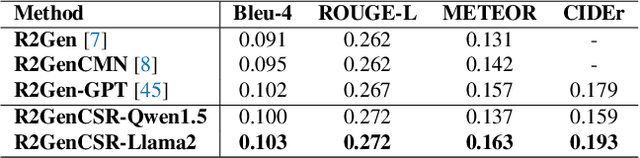
Inspired by the tremendous success of Large Language Models (LLMs), existing X-ray medical report generation methods attempt to leverage large models to achieve better performance. They usually adopt a Transformer to extract the visual features of a given X-ray image, and then, feed them into the LLM for text generation. How to extract more effective information for the LLMs to help them improve final results is an urgent problem that needs to be solved. Additionally, the use of visual Transformer models also brings high computational complexity. To address these issues, this paper proposes a novel context-guided efficient X-ray medical report generation framework. Specifically, we introduce the Mamba as the vision backbone with linear complexity, and the performance obtained is comparable to that of the strong Transformer model. More importantly, we perform context retrieval from the training set for samples within each mini-batch during the training phase, utilizing both positively and negatively related samples to enhance feature representation and discriminative learning. Subsequently, we feed the vision tokens, context information, and prompt statements to invoke the LLM for generating high-quality medical reports. Extensive experiments on three X-ray report generation datasets (i.e., IU-Xray, MIMIC-CXR, CheXpert Plus) fully validated the effectiveness of our proposed model. The source code of this work will be released on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.