 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSTM-CF: Unifying Context Modeling and Fusion with LSTMs for RGB-D Scene Labeling
Paper and Code

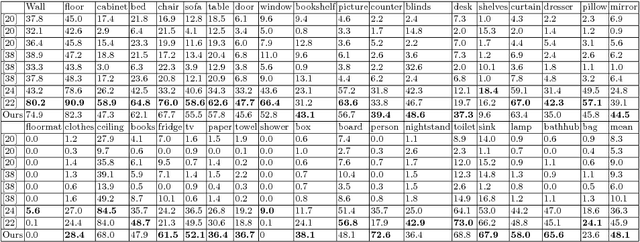

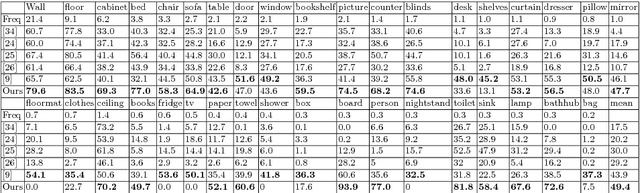
Semantic labeling of RGB-D scenes is crucial to many intelligent applications including perceptual robotics. It generates pixelwise and fine-grained label maps from simultaneously sensed photometric (RGB) and depth channels. This paper addresses this problem by i) developing a novel Long Short-Term Memorized Context Fusion (LSTM-CF) Model that captures and fuses contextual information from multiple channels of photometric and depth data, and ii) incorporating this model into deep convolutional neural networks (CNNs) for end-to-end training. Specifically, contexts in photometric and depth channels are, respectively, captured by stacking several convolutional layers and a long short-term memory layer; the memory layer encodes both short-range and long-range spatial dependencies in an image along the vertical direction. Another long short-term memorized fusion layer is set up to integrate the contexts along the vertical direction from different channels, and perform bi-directional propagation of the fused vertical contexts along the horizontal direction to obtain true 2D global contexts. At last, the fused contextual representation is concatenated with the convolutional features extracted from the photometric channels in order to improve the accuracy of fine-scale semantic labeling. Our proposed model has set a new state of the art, i.e., 48.1% and 49.4% average class accuracy over 37 categories (2.2% and 5.4% improvement) on the large-scale SUNRGBD dataset and the NYUDv2dataset, respectively.