 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVVTRec: Radio Interferometric Reconstruction through Visual and Textual Modality Enrichment
Jan 10, 2026Radio astronomy is an indispensable discipline for observing distant celestial objects. Measurements of wave signals from radio telescopes, called visibility, need to be transformed into images for astronomical observations. These dirty images blend information from real sources and artifacts. Therefore, astronomers usually perform reconstruction before imaging to obtain cleaner images. Existing methods consider only a single modality of sparse visibility data, resulting in images with remaining artifacts and insufficient modeling of correlation. To enhance the extraction of visibility information and emphasize output quality in the image domain, we propose VVTRec, a multimodal radio interferometric data reconstruction method with visibility-guided visual and textual modality enrichment. In our VVTRec, sparse visibility is transformed into image-form and text-form features to obtain enhancements in terms of spatial and semantic information, improving the structural integrity and accuracy of images. Also, we leverage Vision-Language Models (VLMs) to achieve additional training-free performance improvements. VVTRec enables sparse visibility, as a foreign modality unseen by VLMs, to accurately extract pre-trained knowledge as a supplement. Our experiments demonstrate that VVTRec effectively enhances imaging results by exploiting multimodal information without introducing excessive computational overhead.
D-GAP: Improving Out-of-Domain Robustness via Dataset-Agnostic and Gradient-Guided Augmentation in Amplitude and Pixel Spaces
Nov 14, 2025Out-of-domain (OOD) robustness is challenging to achieve in real-world computer vision applications, where shifts in image background, style, and acquisition instruments always degrade model performance. Generic augmentations show inconsistent gains under such shifts, whereas dataset-specific augmentations require expert knowledge and prior analysis. Moreover, prior studies show that neural networks adapt poorly to domain shifts because they exhibit a learning bias to domain-specific frequency components. Perturbing frequency values can mitigate such bias but overlooks pixel-level details, leading to suboptimal performance. To address these problems, we propose D-GAP (Dataset-agnostic and Gradient-guided augmentation in Amplitude and Pixel spaces), improving OOD robustness by introducing targeted augmentation in both the amplitude space (frequency space) and pixel space. Unlike conventional handcrafted augmentations, D-GAP computes sensitivity maps in the frequency space from task gradients, which reflect how strongly the model responds to different frequency components, and uses the maps to adaptively interpolate amplitudes between source and target samples. This way, D-GAP reduces the learning bias in frequency space, while a complementary pixel-space blending procedure restores fine spatial details. Extensive experiments on four real-world datasets and three domain-adaptation benchmarks show that D-GAP consistently outperforms both generic and dataset-specific augmentations, improving average OOD performance by +5.3% on real-world datasets and +1.8% on benchmark datasets.
Improving Out-of-Domain Robustness with Targeted Augmentation in Frequency and Pixel Spaces
May 18, 2025



Out-of-domain (OOD) robustness under domain adaptation settings, where labeled source data and unlabeled target data come from different distributions, is a key challenge in real-world applications. A common approach to improving OOD robustness is through data augmentations. However, in real-world scenarios, models trained with generic augmentations can only improve marginally when generalized under distribution shifts toward unlabeled target domains. While dataset-specific targeted augmentations can address this issue, they typically require expert knowledge and extensive prior data analysis to identify the nature of the datasets and domain shift. To address these challenges, we propose Frequency-Pixel Connect, a domain-adaptation framework that enhances OOD robustness by introducing a targeted augmentation in both the frequency space and pixel space. Specifically, we mix the amplitude spectrum and pixel content of a source image and a target image to generate augmented samples that introduce domain diversity while preserving the semantic structure of the source image. Unlike previous targeted augmentation methods that are both dataset-specific and limited to the pixel space, Frequency-Pixel Connect is dataset-agnostic, enabling broader and more flexible applicability beyond natural image datasets. We further analyze the effectiveness of Frequency-Pixel Connect by evaluating the performance of our method connecting same-class cross-domain samples while separating different-class examples. We demonstrate that Frequency-Pixel Connect significantly improves cross-domain connectivity and outperforms previous generic methods on four diverse real-world benchmarks across vision, medical, audio, and astronomical domains, and it also outperforms other dataset-specific targeted augmentation methods.
An Enhanced Iterative Deepening Search Algorithm for the Unrestricted Container Rehandling Problem
Apr 12, 2025



In container terminal yards, the Container Rehandling Problem (CRP) involves rearranging containers between stacks under specific operational rules, and it is a pivotal optimization challenge in intelligent container scheduling systems. Existing CRP studies primarily focus on minimizing reallocation costs using two-dimensional bay structures, considering factors such as container size, weight, arrival sequences, and retrieval priorities. This paper introduces an enhanced deepening search algorithm integrated with improved lower bounds to boost search efficiency. To further reduce the search space, we design mutually consistent pruning rules to avoid excessive computational overhead. The proposed algorithm is validated on three widely used benchmark datasets for the Unrestricted Container Rehandling Problem (UCRP). Experimental results demonstrate that our approach outperforms state-of-the-art exact algorithms in solving the more general UCRP variant, particularly exhibiting superior efficiency when handling containers within the same priority group under strict time constraints.
Effective Fine-Tuning of Vision-Language Models for Accurate Galaxy Morphology Analysis
Nov 29, 2024



Galaxy morphology analysis involves classifying galaxies by their shapes and structures. For this task, directly training domain-specific models on large, annotated astronomical datasets is effective but costly. In contrast, fine-tuning vision foundation models on a smaller set of astronomical images is more resource-efficient but generally results in lower accuracy. To harness the benefits of both approaches and address their shortcomings, we propose GalaxAlign, a novel method that fine-tunes pre-trained foundation models to achieve high accuracy on astronomical tasks. Specifically, our method extends a contrastive learning architecture to align three types of data in fine-tuning: (1) a set of schematic symbols representing galaxy shapes and structures, (2) textual labels of these symbols, and (3) galaxy images. This way, GalaxAlign not only eliminates the need for expensive pretraining but also enhances the effectiveness of fine-tuning. Extensive experiments on galaxy classification and similarity search demonstrate that our method effectively fine-tunes general pre-trained models for astronomical tasks by incorporating domain-specific multi-modal knowledge.
VisRec: A Semi-Supervised Approach to Radio Interferometric Data Reconstruction
Mar 01, 2024



Radio telescopes produce visibility data about celestial objects, but these data are sparse and noisy. As a result, images created on raw visibility data are of low quality. Recent studies have used deep learning models to reconstruct visibility data to get cleaner images. However, these methods rely on a substantial amount of labeled training data, which requires significant labeling effort from radio astronomers. Addressing this challenge, we propose VisRec, a model-agnostic semi-supervised learning approach to the reconstruction of visibility data. Specifically, VisRec consists of both a supervised learning module and an unsupervised learning module. In the supervised learning module, we introduce a set of data augmentation functions to produce diverse training examples. In comparison, the unsupervised learning module in VisRec augments unlabeled data and uses reconstructions from non-augmented visibility data as pseudo-labels for training. This hybrid approach allows VisRec to effectively leverage both labeled and unlabeled data. This way, VisRec performs well even when labeled data is scarce. Our evaluation results show that VisRec outperforms all baseline methods in reconstruction quality, robustness against common observation perturbation, and generalizability to different telescope configurations.
A Transformer-Conditioned Neural Fields Pipeline with Polar Coordinate Representation for Astronomical Radio Interferometric Data Reconstruction
Aug 28, 2023



In radio astronomy, visibility data, which are measurements of wave signals from radio telescopes, are transformed into images for observation of distant celestial objects. However, these resultant images usually contain both real sources and artifacts, due to signal sparsity and other factors. One way to obtain cleaner images is to reconstruct samples into dense forms before imaging. Unfortunately, existing visibility reconstruction methods may miss some components of the frequency data, so blurred object edges and persistent artifacts remain in the images. Furthermore, the computation overhead is high on irregular visibility samples due to the data skew. To address these problems, we propose PolarRec, a reconstruction method for interferometric visibility data, which consists of a transformer-conditioned neural fields pipeline with a polar coordinate representation. This representation matches the way in which telescopes observe a celestial area as the Earth rotates. We further propose Radial Frequency Loss function, using radial coordinates in the polar coordinate system to correlate with the frequency information, to help reconstruct complete visibility. We also group visibility sample points by angular coordinates in the polar coordinate system, and use groups as the granularity for subsequent encoding with a Transformer encoder. Consequently, our method can capture the inherent characteristics of visibility data effectively and efficiently. Our experiments demonstrate that PolarRec markedly improves imaging results by faithfully reconstructing all frequency components in the visibility domain while significantly reducing the computation cost.
A Conditional Denoising Diffusion Probabilistic Model for Radio Interferometric Image Reconstruction
May 16, 2023
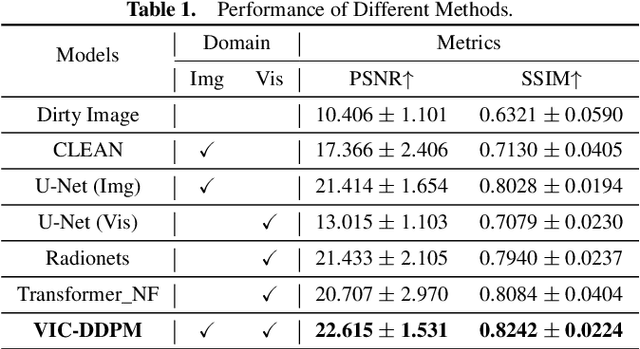
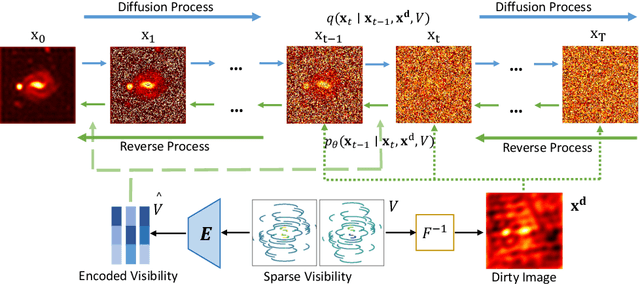
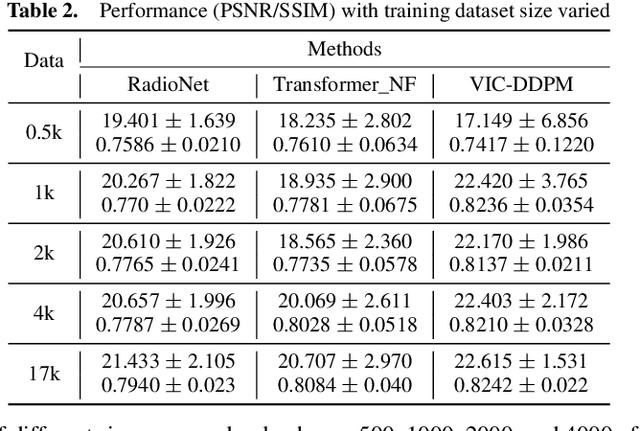
In radio astronomy, signals from radio telescopes are transformed into images of observed celestial objects, or sources. However, these images, called dirty images, contain real sources as well as artifacts due to signal sparsity and other factors. Therefore, radio interferometric image reconstruction is performed on dirty images, aiming to produce clean images in which artifacts are reduced and real sources are recovered. So far, existing methods have limited success on recovering faint sources, preserving detailed structures, and eliminating artifacts. In this paper, we present VIC-DDPM, a Visibility and Image Conditioned Denoising Diffusion Probabilistic Model. Our main idea is to use both the original visibility data in the spectral domain and dirty images in the spatial domain to guide the image generation process with DDPM. This way, we can leverage DDPM to generate fine details and eliminate noise, while utilizing visibility data to separate signals from noise and retaining spatial information in dirty images. We have conducted experiments in comparison with both traditional methods and recent deep learning based approaches. Our results show that our method significantly improves the resulting images by reducing artifacts, preserving fine details, and recovering dim sources. This advancement further facilitates radio astronomical data analysis tasks on celestial phenomena.
AMMASurv: Asymmetrical Multi-Modal Attention for Accurate Survival Analysis with Whole Slide Images and Gene Expression Data
Aug 28, 2021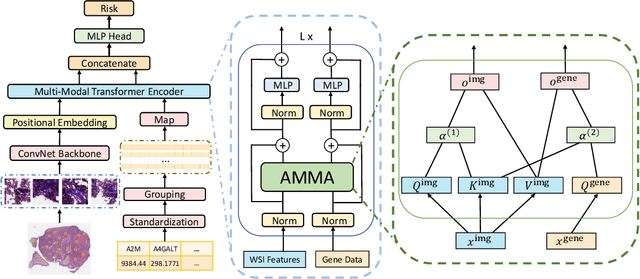
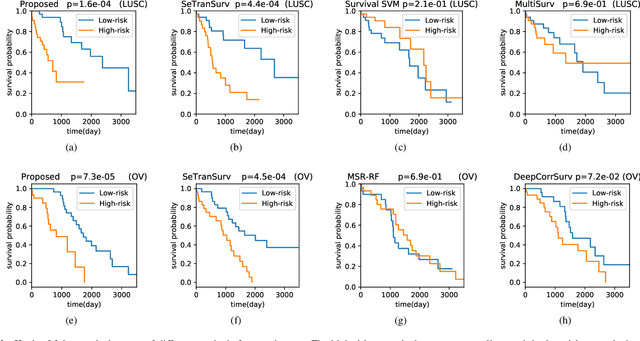
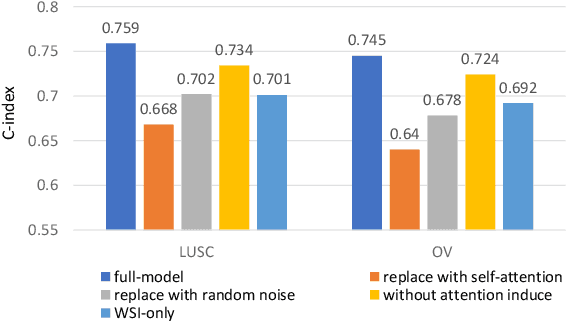
The use of multi-modal data such as the combination of whole slide images (WSIs) and gene expression data for survival analysis can lead to more accurate survival predictions. Previous multi-modal survival models are not able to efficiently excavate the intrinsic information within each modality. Moreover, despite experimental results show that WSIs provide more effective information than gene expression data, previous methods regard the information from different modalities as similarly important so they cannot flexibly utilize the potential connection between the modalities. To address the above problems, we propose a new asymmetrical multi-modal method, termed as AMMASurv. Specifically, we design an asymmetrical multi-modal attention mechanism (AMMA) in Transformer encoder for multi-modal data to enable a more flexible multi-modal information fusion for survival prediction. Different from previous works, AMMASurv can effectively utilize the intrinsic information within every modality and flexibly adapts to the modalities of different importance. Extensive experiments are conducted to validate the effectiveness of the proposed model. Encouraging results demonstrate the superiority of our method over other state-of-the-art methods.