 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition
Apr 30, 2025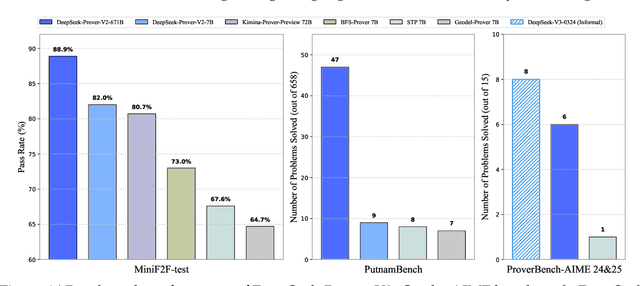
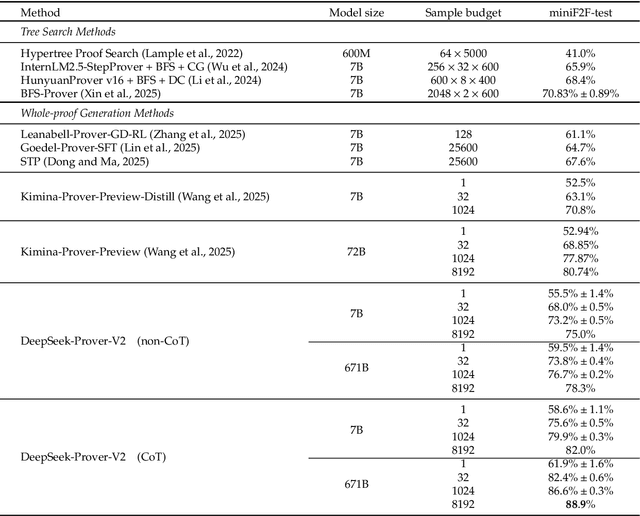

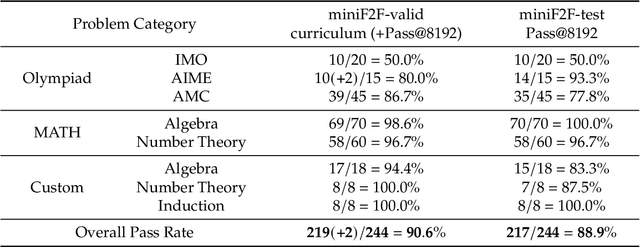
We introduce DeepSeek-Prover-V2, an open-source large language model designed for formal theorem proving in Lean 4, with initialization data collected through a recursive theorem proving pipeline powered by DeepSeek-V3. The cold-start training procedure begins by prompting DeepSeek-V3 to decompose complex problems into a series of subgoals. The proofs of resolved subgoals are synthesized into a chain-of-thought process, combined with DeepSeek-V3's step-by-step reasoning, to create an initial cold start for reinforcement learning. This process enables us to integrate both informal and formal mathematical reasoning into a unified model. The resulting model, DeepSeek-Prover-V2-671B, achieves state-of-the-art performance in neural theorem proving, reaching 88.9% pass ratio on the MiniF2F-test and solving 49 out of 658 problems from PutnamBench. In addition to standard benchmarks, we introduce ProverBench, a collection of 325 formalized problems, to enrich our evaluation, including 15 selected problems from the recent AIME competitions (years 24-25). Further evaluation on these 15 AIME problems shows that the model successfully solves 6 of them. In comparison, DeepSeek-V3 solves 8 of these problems using majority voting, highlighting that the gap between formal and informal mathematical reasoning in large language models is substantially narrowing.
UGen: Unified Autoregressive Multimodal Model with Progressive Vocabulary Learning
Mar 27, 2025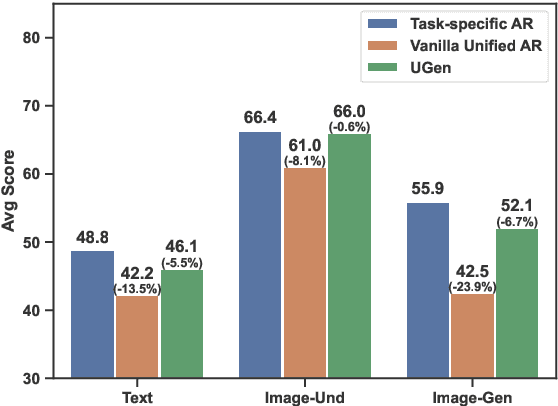
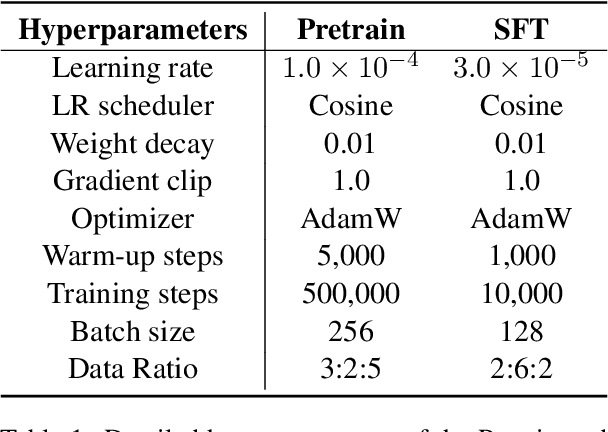
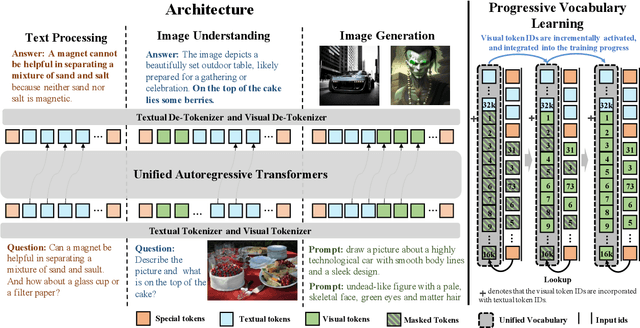
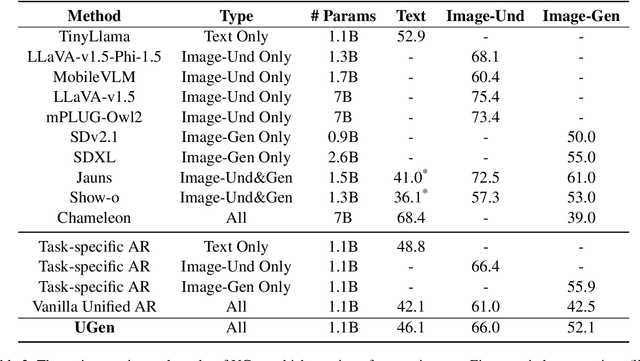
We introduce UGen, a unified autoregressive multimodal model that demonstrates strong performance across text processing, image understanding, and image generation tasks simultaneously. UGen converts both texts and images into discrete token sequences and utilizes a single transformer to generate them uniformly in an autoregressive manner. To address the challenges associated with unified multimodal learning, UGen is trained using a novel mechanism, namely progressive vocabulary learning. In this process, visual token IDs are incrementally activated and integrated into the training phase, ultimately enhancing the effectiveness of unified multimodal learning. Experiments on comprehensive text and image tasks show that UGen achieves a significant overall performance improvement of 13.3% compared to the vanilla unified autoregressive method, and it also delivers competitive results across all tasks against several task-specific models.
Gnothi Seauton: Empowering Faithful Self-Interpretability in Black-Box Models
Oct 29, 2024



The debate between self-interpretable models and post-hoc explanations for black-box models is central to Explainable AI (XAI). Self-interpretable models, such as concept-based networks, offer insights by connecting decisions to human-understandable concepts but often struggle with performance and scalability. Conversely, post-hoc methods like Shapley values, while theoretically robust, are computationally expensive and resource-intensive. To bridge the gap between these two lines of research, we propose a novel method that combines their strengths, providing theoretically guaranteed self-interpretability for black-box models without compromising prediction accuracy. Specifically, we introduce a parameter-efficient pipeline, *AutoGnothi*, which integrates a small side network into the black-box model, allowing it to generate Shapley value explanations without changing the original network parameters. This side-tuning approach significantly reduces memory, training, and inference costs, outperforming traditional parameter-efficient methods, where full fine-tuning serves as the optimal baseline. *AutoGnothi* enables the black-box model to predict and explain its predictions with minimal overhead. Extensive experiments show that *AutoGnothi* offers accurate explanations for both vision and language tasks, delivering superior computational efficiency with comparable interpretability.
Divide-and-Conquer Meets Consensus: Unleashing the Power of Functions in Code Generation
May 30, 2024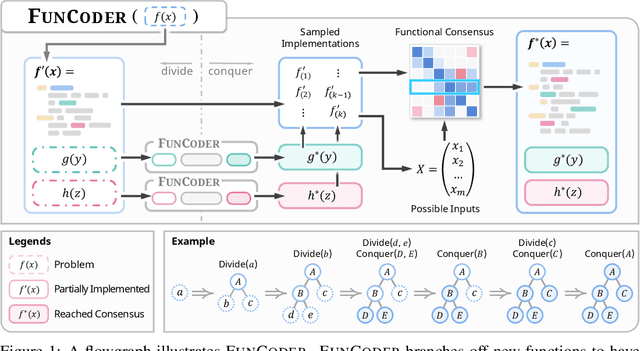
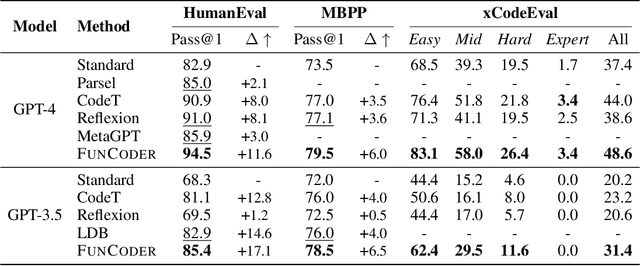


Despite recent progress made by large language models in code generation, they still struggle with programs that meet complex requirements. Recent work utilizes plan-and-solve decomposition to decrease the complexity and leverage self-tests to refine the generated program. Yet, planning deep-inside requirements in advance can be challenging, and the tests need to be accurate to accomplish self-improvement. To this end, we propose FunCoder, a code generation framework incorporating the divide-and-conquer strategy with functional consensus. Specifically, FunCoder recursively branches off sub-functions as smaller goals during code generation, represented by a tree hierarchy. These sub-functions are then composited to attain more complex objectives. Additionally, we designate functions via a consensus formed by identifying similarities in program behavior, mitigating error propagation. FunCoder outperforms state-of-the-art methods by +9.8% on average in HumanEval, MBPP, xCodeEval and MATH with GPT-3.5 and GPT-4. Moreover, our method demonstrates superiority on smaller models: With FunCoder, StableCode-3b surpasses GPT-3.5 by +18.6% and achieves 97.7% of GPT-4's performance on HumanEval. Further analysis reveals that our proposed dynamic function decomposition is capable of handling complex requirements, and the functional consensus prevails over self-testing in correctness evaluation.
A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
May 23, 2022
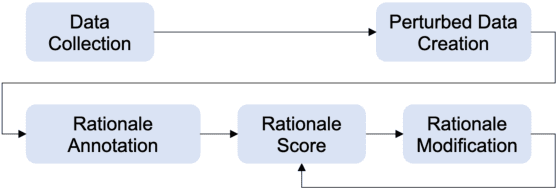
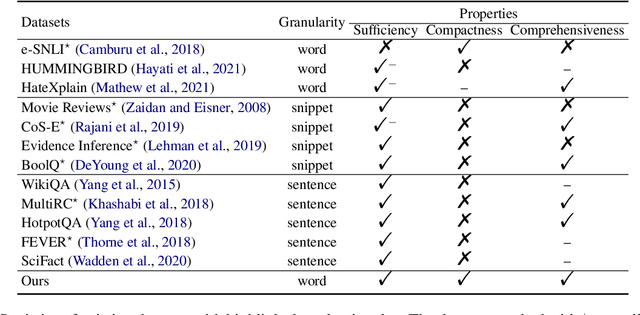
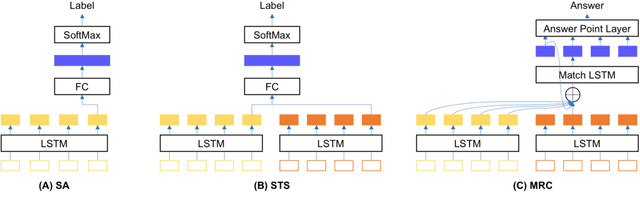
While there is increasing concern about the interpretability of neural models, the evaluation of interpretability remains an open problem, due to the lack of proper evaluation datasets and metrics. In this paper, we present a novel benchmark to evaluate the interpretability of both neural models and saliency methods. This benchmark covers three representative NLP tasks: sentiment analysis, textual similarity and reading comprehension, each provided with both English and Chinese annotated data. In order to precisely evaluate the interpretability, we provide token-level rationales that are carefully annotated to be sufficient, compact and comprehensive. We also design a new metric, i.e., the consistency between the rationales before and after perturbations, to uniformly evaluate the interpretability of models and saliency methods on different tasks. Based on this benchmark, we conduct experiments on three typical models with three saliency methods, and unveil their strengths and weakness in terms of interpretability. We will release this benchmark at \url{https://xyz} and hope it can facilitate the research in building trustworthy systems.
A Multimodal Sentiment Dataset for Video Recommendation
Sep 17, 2021


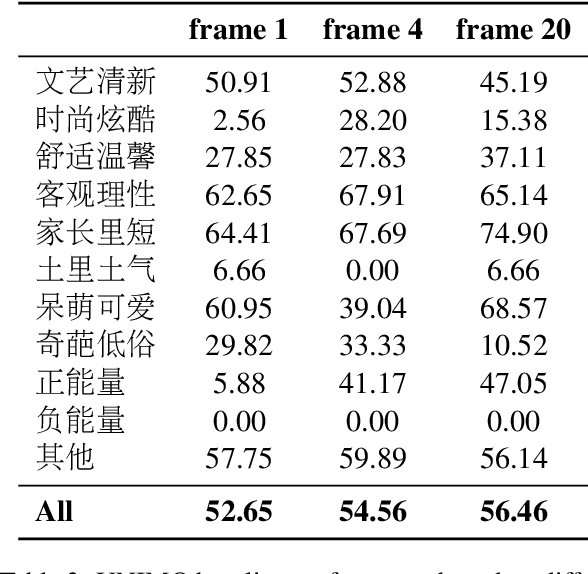
Recently, multimodal sentiment analysis has seen remarkable advance and a lot of datasets are proposed for its development. In general, current multimodal sentiment analysis datasets usually follow the traditional system of sentiment/emotion, such as positive, negative and so on. However, when applied in the scenario of video recommendation, the traditional sentiment/emotion system is hard to be leveraged to represent different contents of videos in the perspective of visual senses and language understanding. Based on this, we propose a multimodal sentiment analysis dataset, named baiDu Video Sentiment dataset (DuVideoSenti), and introduce a new sentiment system which is designed to describe the sentimental style of a video on recommendation scenery. Specifically, DuVideoSenti consists of 5,630 videos which displayed on Baidu, each video is manually annotated with a sentimental style label which describes the user's real feeling of a video. Furthermore, we propose UNIMO as our baseline for DuVideoSenti. Experimental results show that DuVideoSenti brings new challenges to multimodal sentiment analysis, and could be used as a new benchmark for evaluating approaches designed for video understanding and multimodal fusion. We also expect our proposed DuVideoSenti could further improve the development of multimodal sentiment analysis and its application to video recommendations.
DuTrust: A Sentiment Analysis Dataset for Trustworthiness Evaluation
Sep 07, 2021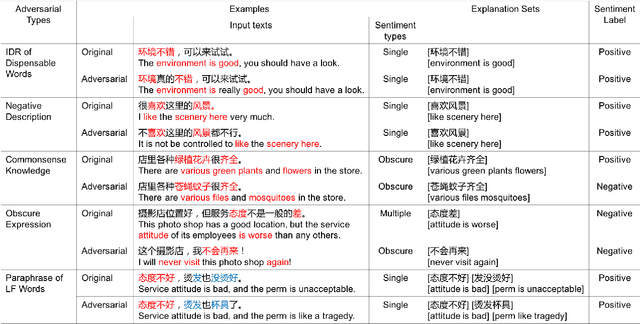
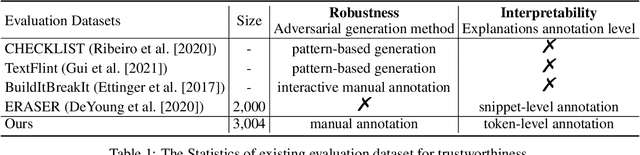


While deep learning models have greatly improved the performance of most artificial intelligence tasks, they are often criticized to be untrustworthy due to the black-box problem. Consequently, many works have been proposed to study the trustworthiness of deep learning. However, as most open datasets are designed for evaluating the accuracy of model outputs, there is still a lack of appropriate datasets for evaluating the inner workings of neural networks. The lack of datasets obviously hinders the development of trustworthiness research. Therefore, in order to systematically evaluate the factors for building trustworthy systems, we propose a novel and well-annotated sentiment analysis dataset to evaluate robustness and interpretability. To evaluate these factors, our dataset contains diverse annotations about the challenging distribution of instances, manual adversarial instances and sentiment explanations. Several evaluation metrics are further proposed for interpretability and robustness. Based on the dataset and metrics, we conduct comprehensive comparisons for the trustworthiness of three typical models, and also study the relations between accuracy, robustness and interpretability. We release this trustworthiness evaluation dataset at \url{https://github/xyz} and hope our work can facilitate the progress on building more trustworthy systems for real-world applications.
DuReaderrobust: A Chinese Dataset Towards Evaluating the Robustness of Machine Reading Comprehension Models
Apr 23, 2020


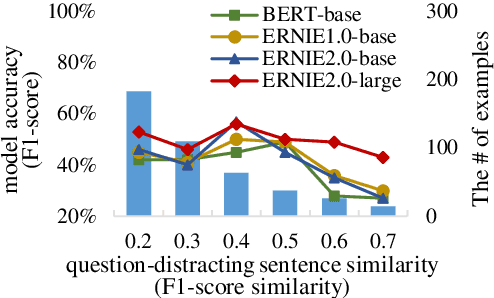
Machine Reading Comprehension (MRC) is a crucial and challenging task in natural language processing. Although several MRC models obtains human parity performance on several datasets, we find that these models are still far from robust. To comprehensively evaluate the robustness of MRC models, we create a Chinese dataset, namely DuReader_{robust}. It is designed to challenge MRC models from the following aspects: (1) over-sensitivity, (2) over-stability and (3) generalization. Most of previous work studies these problems by altering the inputs to unnatural texts. By contrast, the advantage of DuReader_{robust} is that its questions and documents are natural texts. It presents the robustness challenges when applying MRC models to real-world applications. The experimental results show that MRC models based on the pre-trained language models perform much worse than human does on the robustness test set, although they perform as well as human on in-domain test set. Additionally, we analyze the behavior of existing models on the robustness test set, which might give suggestions for future model development. The dataset and codes are available at \url{https://github.com/PaddlePaddle/Research/tree/master/NLP/DuReader-Robust-BASELINE}