 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUGen: Unified Autoregressive Multimodal Model with Progressive Vocabulary Learning
Paper and Code
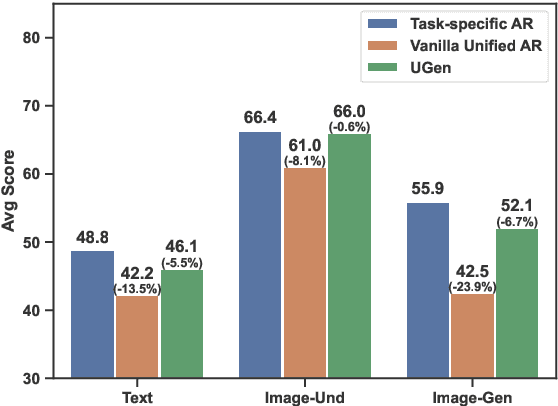
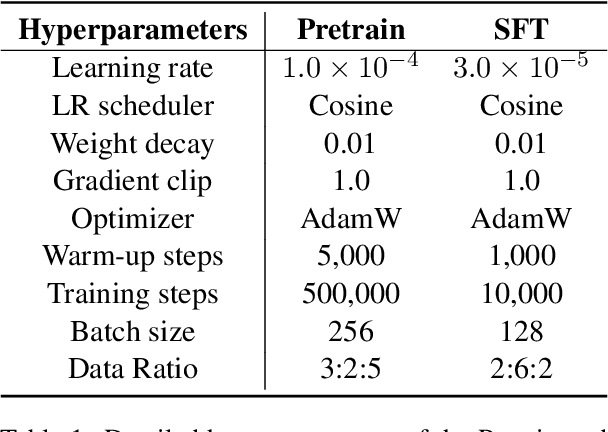
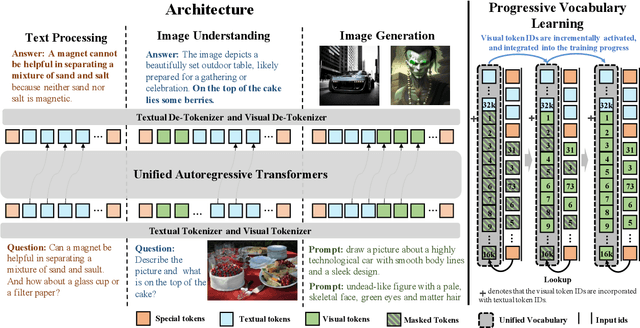
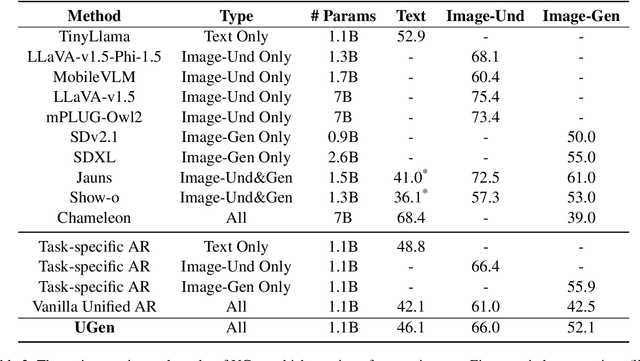
We introduce UGen, a unified autoregressive multimodal model that demonstrates strong performance across text processing, image understanding, and image generation tasks simultaneously. UGen converts both texts and images into discrete token sequences and utilizes a single transformer to generate them uniformly in an autoregressive manner. To address the challenges associated with unified multimodal learning, UGen is trained using a novel mechanism, namely progressive vocabulary learning. In this process, visual token IDs are incrementally activated and integrated into the training phase, ultimately enhancing the effectiveness of unified multimodal learning. Experiments on comprehensive text and image tasks show that UGen achieves a significant overall performance improvement of 13.3% compared to the vanilla unified autoregressive method, and it also delivers competitive results across all tasks against several task-specific models.