 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fine-grained Interpretability Evaluation Benchmark for Neural NLP
May 23, 2022
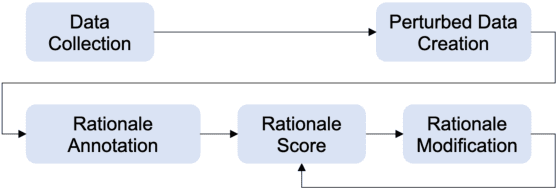
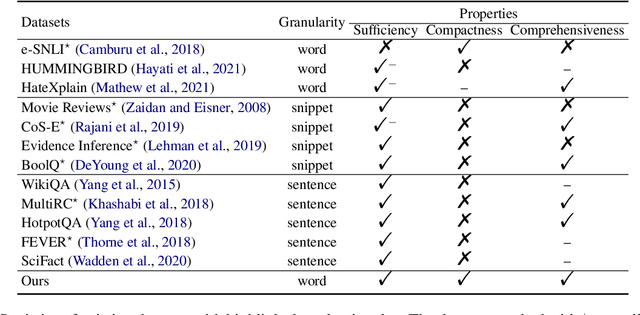
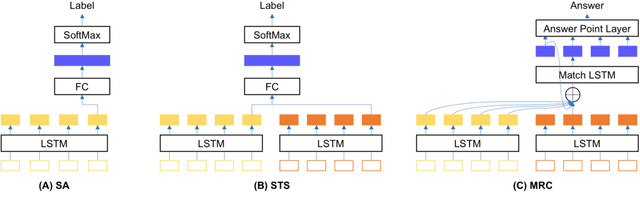
While there is increasing concern about the interpretability of neural models, the evaluation of interpretability remains an open problem, due to the lack of proper evaluation datasets and metrics. In this paper, we present a novel benchmark to evaluate the interpretability of both neural models and saliency methods. This benchmark covers three representative NLP tasks: sentiment analysis, textual similarity and reading comprehension, each provided with both English and Chinese annotated data. In order to precisely evaluate the interpretability, we provide token-level rationales that are carefully annotated to be sufficient, compact and comprehensive. We also design a new metric, i.e., the consistency between the rationales before and after perturbations, to uniformly evaluate the interpretability of models and saliency methods on different tasks. Based on this benchmark, we conduct experiments on three typical models with three saliency methods, and unveil their strengths and weakness in terms of interpretability. We will release this benchmark at \url{https://xyz} and hope it can facilitate the research in building trustworthy systems.
DuTrust: A Sentiment Analysis Dataset for Trustworthiness Evaluation
Sep 07, 2021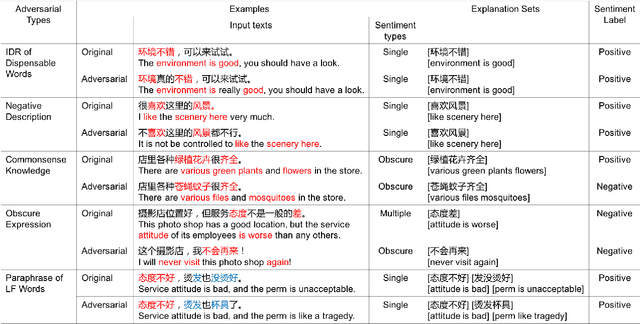
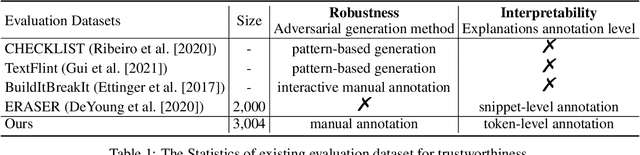


While deep learning models have greatly improved the performance of most artificial intelligence tasks, they are often criticized to be untrustworthy due to the black-box problem. Consequently, many works have been proposed to study the trustworthiness of deep learning. However, as most open datasets are designed for evaluating the accuracy of model outputs, there is still a lack of appropriate datasets for evaluating the inner workings of neural networks. The lack of datasets obviously hinders the development of trustworthiness research. Therefore, in order to systematically evaluate the factors for building trustworthy systems, we propose a novel and well-annotated sentiment analysis dataset to evaluate robustness and interpretability. To evaluate these factors, our dataset contains diverse annotations about the challenging distribution of instances, manual adversarial instances and sentiment explanations. Several evaluation metrics are further proposed for interpretability and robustness. Based on the dataset and metrics, we conduct comprehensive comparisons for the trustworthiness of three typical models, and also study the relations between accuracy, robustness and interpretability. We release this trustworthiness evaluation dataset at \url{https://github/xyz} and hope our work can facilitate the progress on building more trustworthy systems for real-world applications.