 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
An Interpretability Evaluation Benchmark for Pre-trained Language Models
Jul 28, 2022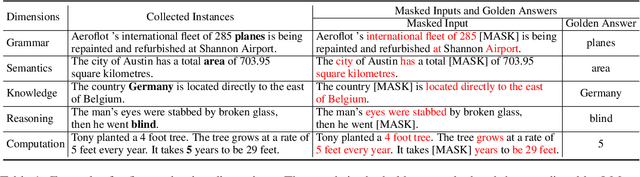
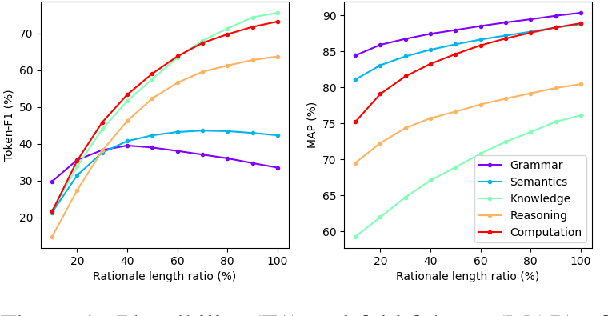

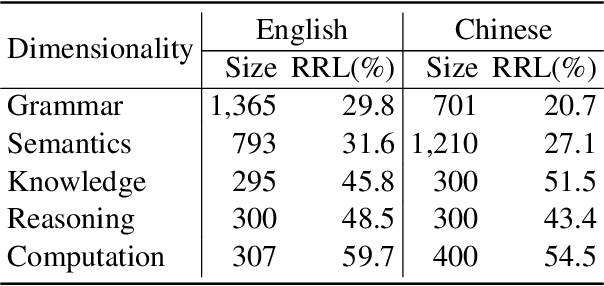
While pre-trained language models (LMs) have brought great improvements in many NLP tasks, there is increasing attention to explore capabilities of LMs and interpret their predictions. However, existing works usually focus only on a certain capability with some downstream tasks. There is a lack of datasets for directly evaluating the masked word prediction performance and the interpretability of pre-trained LMs. To fill in the gap, we propose a novel evaluation benchmark providing with both English and Chinese annotated data. It tests LMs abilities in multiple dimensions, i.e., grammar, semantics, knowledge, reasoning and computation. In addition, it provides carefully annotated token-level rationales that satisfy sufficiency and compactness. It contains perturbed instances for each original instance, so as to use the rationale consistency under perturbations as the metric for faithfulness, a perspective of interpretability. We conduct experiments on several widely-used pre-trained LMs. The results show that they perform very poorly on the dimensions of knowledge and computation. And their plausibility in all dimensions is far from satisfactory, especially when the rationale is short. In addition, the pre-trained LMs we evaluated are not robust on syntax-aware data. We will release this evaluation benchmark at \url{http://xyz}, and hope it can facilitate the research progress of pre-trained LMs.
A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
May 23, 2022
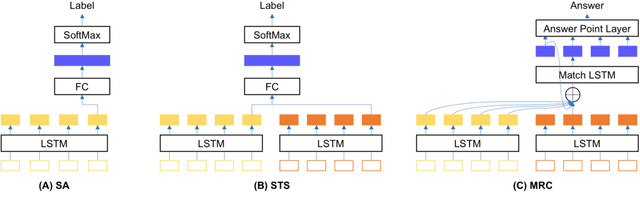
While there is increasing concern about the interpretability of neural models, the evaluation of interpretability remains an open problem, due to the lack of proper evaluation datasets and metrics. In this paper, we present a novel benchmark to evaluate the interpretability of both neural models and saliency methods. This benchmark covers three representative NLP tasks: sentiment analysis, textual similarity and reading comprehension, each provided with both English and Chinese annotated data. In order to precisely evaluate the interpretability, we provide token-level rationales that are carefully annotated to be sufficient, compact and comprehensive. We also design a new metric, i.e., the consistency between the rationales before and after perturbations, to uniformly evaluate the interpretability of models and saliency methods on different tasks. Based on this benchmark, we conduct experiments on three typical models with three saliency methods, and unveil their strengths and weakness in terms of interpretability. We will release this benchmark at \url{https://xyz} and hope it can facilitate the research in building trustworthy systems.