 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretability Evaluation Benchmark for Pre-trained Language Models
Paper and Code
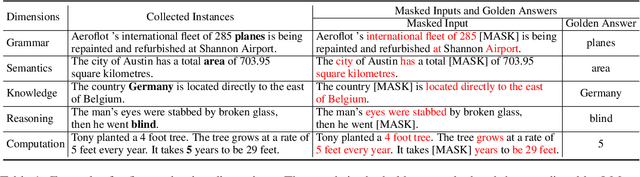
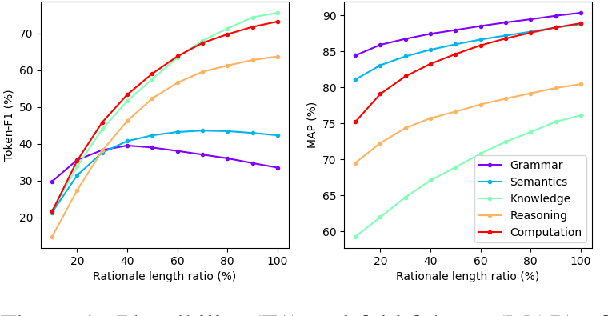

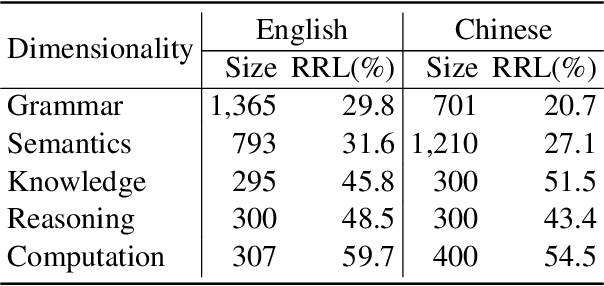
While pre-trained language models (LMs) have brought great improvements in many NLP tasks, there is increasing attention to explore capabilities of LMs and interpret their predictions. However, existing works usually focus only on a certain capability with some downstream tasks. There is a lack of datasets for directly evaluating the masked word prediction performance and the interpretability of pre-trained LMs. To fill in the gap, we propose a novel evaluation benchmark providing with both English and Chinese annotated data. It tests LMs abilities in multiple dimensions, i.e., grammar, semantics, knowledge, reasoning and computation. In addition, it provides carefully annotated token-level rationales that satisfy sufficiency and compactness. It contains perturbed instances for each original instance, so as to use the rationale consistency under perturbations as the metric for faithfulness, a perspective of interpretability. We conduct experiments on several widely-used pre-trained LMs. The results show that they perform very poorly on the dimensions of knowledge and computation. And their plausibility in all dimensions is far from satisfactory, especially when the rationale is short. In addition, the pre-trained LMs we evaluated are not robust on syntax-aware data. We will release this evaluation benchmark at \url{http://xyz}, and hope it can facilitate the research progress of pre-trained LMs.