 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuReaderrobust: A Chinese Dataset Towards Evaluating the Robustness of Machine Reading Comprehension Models
Paper and Code



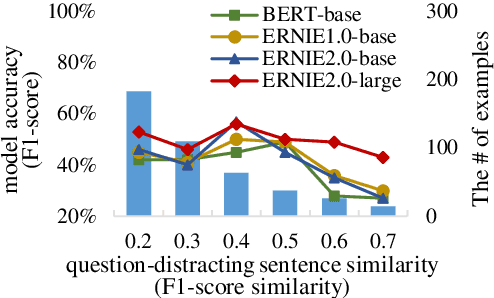
Machine Reading Comprehension (MRC) is a crucial and challenging task in natural language processing. Although several MRC models obtains human parity performance on several datasets, we find that these models are still far from robust. To comprehensively evaluate the robustness of MRC models, we create a Chinese dataset, namely DuReader_{robust}. It is designed to challenge MRC models from the following aspects: (1) over-sensitivity, (2) over-stability and (3) generalization. Most of previous work studies these problems by altering the inputs to unnatural texts. By contrast, the advantage of DuReader_{robust} is that its questions and documents are natural texts. It presents the robustness challenges when applying MRC models to real-world applications. The experimental results show that MRC models based on the pre-trained language models perform much worse than human does on the robustness test set, although they perform as well as human on in-domain test set. Additionally, we analyze the behavior of existing models on the robustness test set, which might give suggestions for future model development. The dataset and codes are available at \url{https://github.com/PaddlePaddle/Research/tree/master/NLP/DuReader-Robust-BASELINE}