 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropeller-Assisted Robust 3D Hopping Robot with Hierarchical Force Allocation
Jun 06, 2026Monopedal hopping robots are conceptually simple but highly dynamic and inherently unstable. Achieving robust 3D hopping is still difficult because ground reaction forces are available only during the short stance phase, while the robot is underactuated in flight. A key unresolved issue is how to improve flight-phase control authority. Propeller assistance provides a promising solution, but it requires careful coordination of leg-generated contact forces and propeller thrusts across stance and flight. This paper presents Pro-OMEGA2, a propeller-assisted 3D monopedal hopping robot with an active 3-RSR parallel leg and a trunk-mounted tri-rotor for auxiliary attitude regulation. To address the force coordination challenge, we propose a Hierarchical Force Allocation (HFA) framework based on a single rigid body (SRB) model. The leg generates the main stance contact wrench, while the tri-rotor provides auxiliary attitude regulation, compensating the residual attitude moment in stance and maintaining attitude during flight. Real-robot experiments in indoor and outdoor scenarios demonstrate sustained 3D hopping, including terrain transitions and impulsive push recovery, validating robustness under unmodeled contact and external disturbances.
The Alignment Tax: Response Homogenization in Aligned LLMs and Its Implications for Uncertainty Estimation
Mar 25, 2026RLHF-aligned language models exhibit response homogenization: on TruthfulQA (n=790), 40-79% of questions produce a single semantic cluster across 10 i.i.d. samples. On affected questions, sampling-based uncertainty methods have zero discriminative power (AUROC=0.500), while free token entropy retains signal (0.603). This alignment tax is task-dependent: on GSM8K (n=500), token entropy achieves 0.724 (Cohen's d=0.81). A base-vs-instruct ablation confirms the causal role of alignment: the base model shows 1.0% single-cluster rate vs. 28.5% for the instruct model (p < 10^{-6}). A training stage ablation (Base 0.0% -> SFT 1.5% -> DPO 4.0% SCR) localizes the cause to DPO, not SFT. Cross-family replication on four model families reveals alignment tax severity varies by family and scale. We validate across 22 experiments, 5 benchmarks, 4 model families, and 3 model scales (3B-14B), with Jaccard, embedding, and NLI-based baselines at three DeBERTa scales (all ~0.51 AUROC). Cross-embedder validation with two independent embedding families rules out coupling bias. Cross-dataset validation on WebQuestions (58.0% SCR) confirms generalization beyond TruthfulQA. The central finding -- response homogenization -- is implementation-independent and label-free. Motivated by this diagnosis, we explore a cheapest-first cascade (UCBD) over orthogonal uncertainty signals. Selective prediction raises GSM8K accuracy from 84.4% to 93.2% at 50% coverage; weakly dependent boundaries (|r| <= 0.12) enable 57% cost savings.
Design and Experimental Study of Vacuum Suction Grabbing Technology to Grasp Fabric Piece
Aug 18, 2024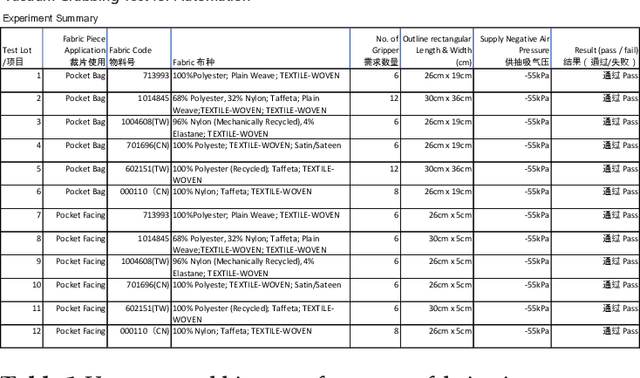

The primary objective of this study was to design the grabbing technique used to determine the vacuum suction gripper and its design parameters for the pocket welting operation in apparel manufacturing. It presents the application of vacuum suction in grabbing technology, a technique that has revolutionized the handling and manipulation to grasp the various fabric materials in a range of garment industries. Vacuum suction, being non-intrusive and non-invasive, offers several advantages compared to traditional grabbing methods. It is particularly useful in scenarios where soft woven fabric and air-impermeable fabric items need to be handled with utmost care. The paper delves into the working principles of vacuum suction, its various components, and the underlying physics involved. Furthermore, it explores the various applications of vacuum suction in the garment industry into the automation exploration. The paper also highlights the challenges and limitations of vacuum suction technology and suggests potential areas for further research and development.
Who Should I Engage with At What Time? A Missing Event Aware Temporal Graph Neural Network
Jan 20, 2023Temporal graph neural network has recently received significant attention due to its wide application scenarios, such as bioinformatics, knowledge graphs, and social networks. There are some temporal graph neural networks that achieve remarkable results. However, these works focus on future event prediction and are performed under the assumption that all historical events are observable. In real-world applications, events are not always observable, and estimating event time is as important as predicting future events. In this paper, we propose MTGN, a missing event-aware temporal graph neural network, which uniformly models evolving graph structure and timing of events to support predicting what will happen in the future and when it will happen.MTGN models the dynamic of both observed and missing events as two coupled temporal point processes, thereby incorporating the effects of missing events into the network. Experimental results on several real-world temporal graphs demonstrate that MTGN significantly outperforms existing methods with up to 89% and 112% more accurate time and link prediction. Code can be found on https://github.com/HIT-ICES/TNNLS-MTGN.
DySR: A Dynamic Representation Learning and Aligning based Model for Service Bundle Recommendation
Aug 07, 2021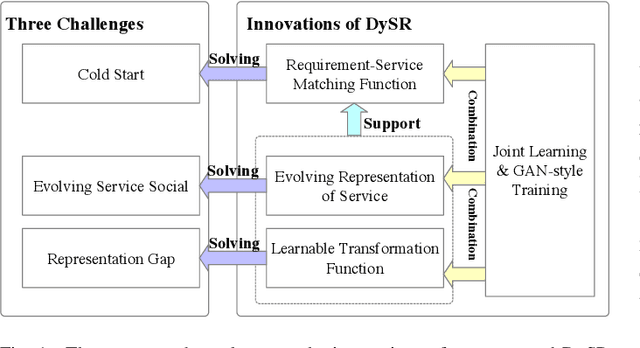
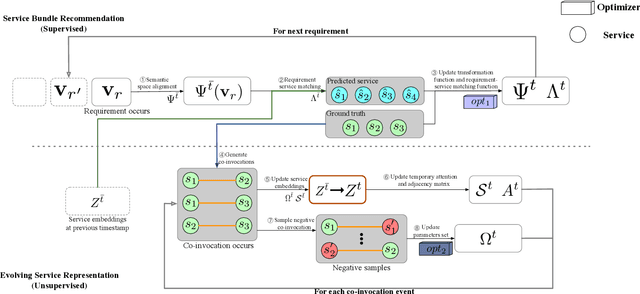
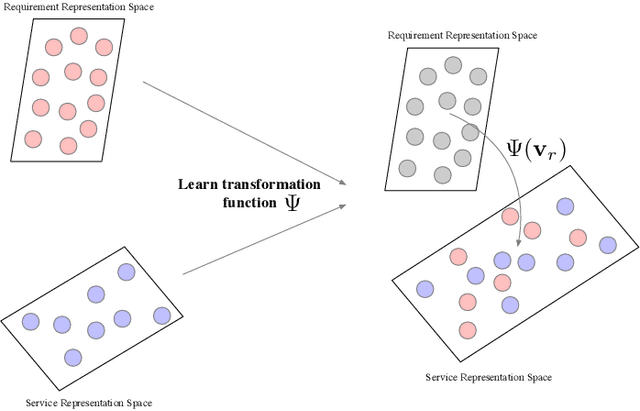
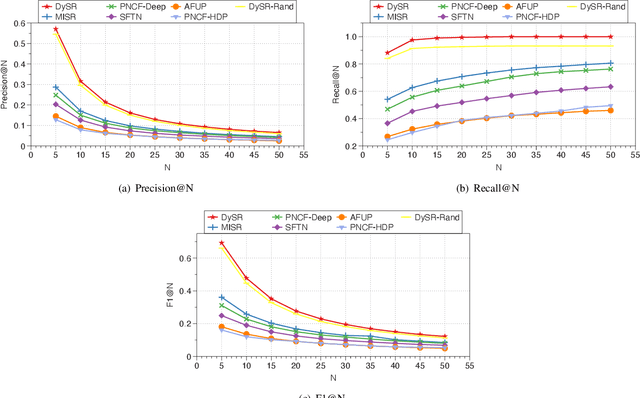
An increasing number and diversity of services are available, which result in significant challenges to effective reuse service during requirement satisfaction. There have been many service bundle recommendation studies and achieved remarkable results. However, there is still plenty of room for improvement in the performance of these methods. The fundamental problem with these studies is that they ignore the evolution of services over time and the representation gap between services and requirements. In this paper, we propose a dynamic representation learning and aligning based model called DySR to tackle these issues. DySR eliminates the representation gap between services and requirements by learning a transformation function and obtains service representations in an evolving social environment through dynamic graph representation learning. Extensive experiments conducted on a real-world dataset from ProgrammableWeb show that DySR outperforms existing state-of-the-art methods in commonly used evaluation metrics, improving $F1@5$ from $36.1\%$ to $69.3\%$.
Learning Representation over Dynamic Graph using Aggregation-Diffusion Mechanism
Jun 03, 2021
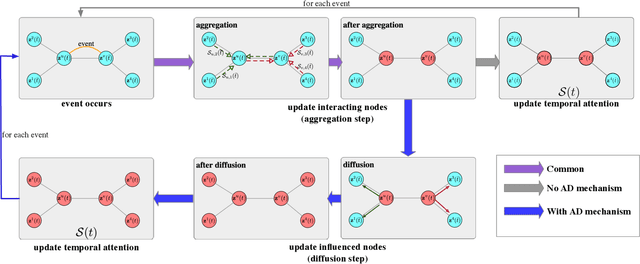
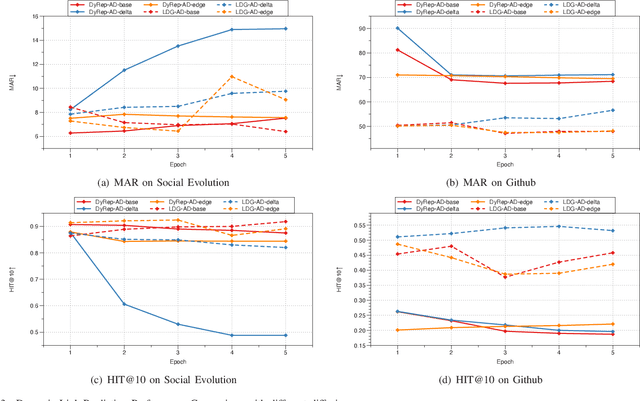
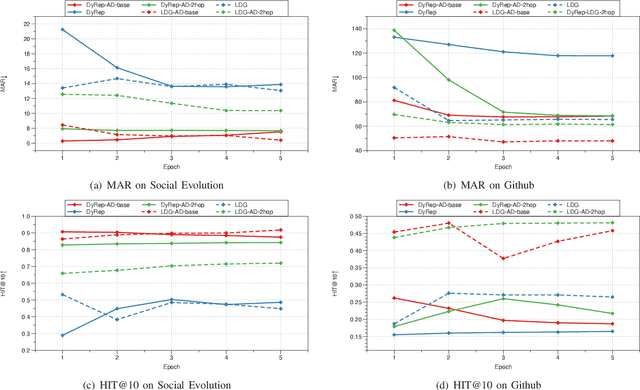
Representation learning on graphs that evolve has recently received significant attention due to its wide application scenarios, such as bioinformatics, knowledge graphs, and social networks. The propagation of information in graphs is important in learning dynamic graph representations, and most of the existing methods achieve this by aggregation. However, relying only on aggregation to propagate information in dynamic graphs can result in delays in information propagation and thus affect the performance of the method. To alleviate this problem, we propose an aggregation-diffusion (AD) mechanism that actively propagates information to its neighbor by diffusion after the node updates its embedding through the aggregation mechanism. In experiments on two real-world datasets in the dynamic link prediction task, the AD mechanism outperforms the baseline models that only use aggregation to propagate information. We further conduct extensive experiments to discuss the influence of different factors in the AD mechanism.
LTP: A New Active Learning Strategy for CRF-Based Named Entity Recognition
Jan 08, 2020
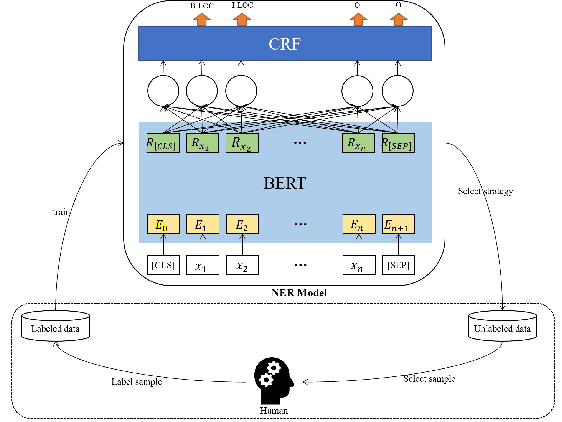
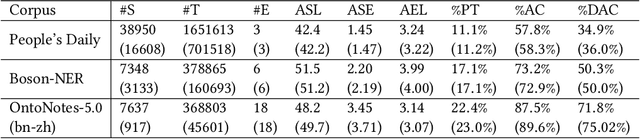
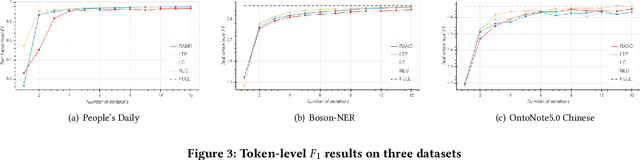
In recent years, deep learning has achieved great success in many natural language processing tasks including named entity recognition. The shortcoming is that a large amount of manually-annotated data is usually required. Previous studies have demonstrated that both transfer learning and active learning could elaborately reduce the cost of data annotation in terms of their corresponding advantages, but there is still plenty of room for improvement. We assume that the convergence of the two methods can complement with each other, so that the model could be trained more accurately with less labelled data, and active learning method could enhance transfer learning method to accurately select the minimum data samples for iterative learning. However, in real applications we found this approach is challenging because the sample selection of traditional active learning strategy merely depends on the final probability value of its model output, and this makes it quite difficult to evaluate the quality of the selected data samples. In this paper, we first examine traditional active learning strategies in a specific case of BERT-CRF that has been widely used in named entity recognition. Then we propose an uncertainty-based active learning strategy called Lowest Token Probability (LTP) which considers not only the final output but also the intermediate results. We test LTP on multiple datasets, and the experiments show that LTP performs better than traditional strategies (incluing LC and NLC) on both token-level $F_1$ and sentence-level accuracy, especially in complex imbalanced datasets.