 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPT: Token Pruning and Pooling for Efficient Vision Transformers
Oct 03, 2023
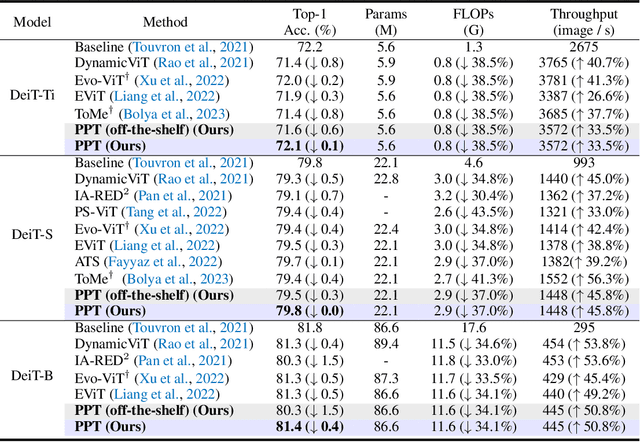


Vision Transformers (ViTs) have emerged as powerful models in the field of computer vision, delivering superior performance across various vision tasks. However, the high computational complexity poses a significant barrier to their practical applications in real-world scenarios. Motivated by the fact that not all tokens contribute equally to the final predictions and fewer tokens bring less computational cost, reducing redundant tokens has become a prevailing paradigm for accelerating vision transformers. However, we argue that it is not optimal to either only reduce inattentive redundancy by token pruning, or only reduce duplicative redundancy by token merging. To this end, in this paper we propose a novel acceleration framework, namely token Pruning & Pooling Transformers (PPT), to adaptively tackle these two types of redundancy in different layers. By heuristically integrating both token pruning and token pooling techniques in ViTs without additional trainable parameters, PPT effectively reduces the model complexity while maintaining its predictive accuracy. For example, PPT reduces over 37% FLOPs and improves the throughput by over 45% for DeiT-S without any accuracy drop on the ImageNet dataset.
Cross-label Suppression: A Discriminative and Fast Dictionary Learning with Group Regularization
May 08, 2017

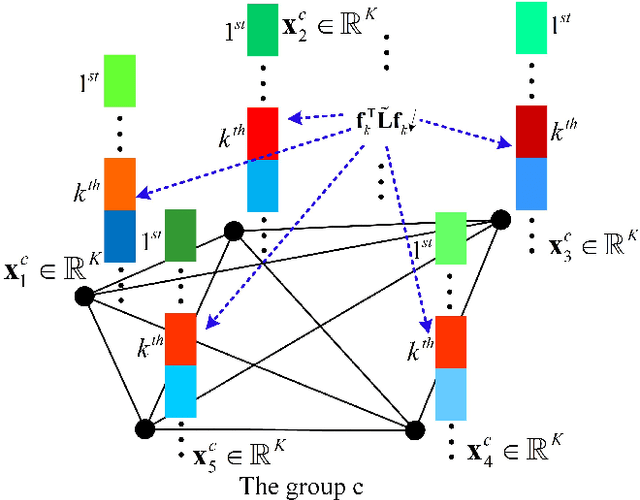

This paper addresses image classification through learning a compact and discriminative dictionary efficiently. Given a structured dictionary with each atom (columns in the dictionary matrix) related to some label, we propose cross-label suppression constraint to enlarge the difference among representations for different classes. Meanwhile, we introduce group regularization to enforce representations to preserve label properties of original samples, meaning the representations for the same class are encouraged to be similar. Upon the cross-label suppression, we don't resort to frequently-used $\ell_0$-norm or $\ell_1$-norm for coding, and obtain computational efficiency without losing the discriminative power for categorization. Moreover, two simple classification schemes are also developed to take full advantage of the learnt dictionary. Extensive experiments on six data sets including face recognition, object categorization, scene classification, texture recognition and sport action categorization are conducted, and the results show that the proposed approach can outperform lots of recently presented dictionary algorithms on both recognition accuracy and computational efficiency.