 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Not Merge My Model! Safeguarding Open-Source LLMs Against Unauthorized Model Merging
Nov 13, 2025Model merging has emerged as an efficient technique for expanding large language models (LLMs) by integrating specialized expert models. However, it also introduces a new threat: model merging stealing, where free-riders exploit models through unauthorized model merging. Unfortunately, existing defense mechanisms fail to provide effective protection. Specifically, we identify three critical protection properties that existing methods fail to simultaneously satisfy: (1) proactively preventing unauthorized merging; (2) ensuring compatibility with general open-source settings; (3) achieving high security with negligible performance loss. To address the above issues, we propose MergeBarrier, a plug-and-play defense that proactively prevents unauthorized merging. The core design of MergeBarrier is to disrupt the Linear Mode Connectivity (LMC) between the protected model and its homologous counterparts, thereby eliminating the low-loss path required for effective model merging. Extensive experiments show that MergeBarrier effectively prevents model merging stealing with negligible accuracy loss.
RAGFort: Dual-Path Defense Against Proprietary Knowledge Base Extraction in Retrieval-Augmented Generation
Nov 13, 2025
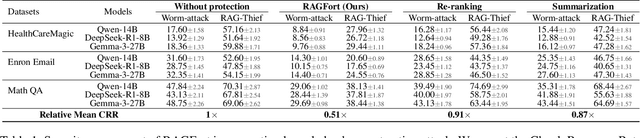
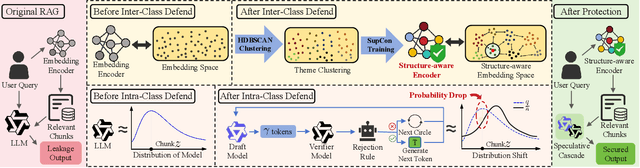
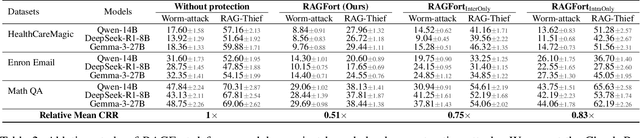
Retrieval-Augmented Generation (RAG) systems deployed over proprietary knowledge bases face growing threats from reconstruction attacks that aggregate model responses to replicate knowledge bases. Such attacks exploit both intra-class and inter-class paths, progressively extracting fine-grained knowledge within topics and diffusing it across semantically related ones, thereby enabling comprehensive extraction of the original knowledge base. However, existing defenses target only one path, leaving the other unprotected. We conduct a systematic exploration to assess the impact of protecting each path independently and find that joint protection is essential for effective defense. Based on this, we propose RAGFort, a structure-aware dual-module defense combining "contrastive reindexing" for inter-class isolation and "constrained cascade generation" for intra-class protection. Experiments across security, performance, and robustness confirm that RAGFort significantly reduces reconstruction success while preserving answer quality, offering comprehensive defense against knowledge base extraction attacks.
HijackRAG: Hijacking Attacks against Retrieval-Augmented Large Language Models
Oct 30, 2024



Retrieval-Augmented Generation (RAG) systems enhance large language models (LLMs) by integrating external knowledge, making them adaptable and cost-effective for various applications. However, the growing reliance on these systems also introduces potential security risks. In this work, we reveal a novel vulnerability, the retrieval prompt hijack attack (HijackRAG), which enables attackers to manipulate the retrieval mechanisms of RAG systems by injecting malicious texts into the knowledge database. When the RAG system encounters target questions, it generates the attacker's pre-determined answers instead of the correct ones, undermining the integrity and trustworthiness of the system. We formalize HijackRAG as an optimization problem and propose both black-box and white-box attack strategies tailored to different levels of the attacker's knowledge. Extensive experiments on multiple benchmark datasets show that HijackRAG consistently achieves high attack success rates, outperforming existing baseline attacks. Furthermore, we demonstrate that the attack is transferable across different retriever models, underscoring the widespread risk it poses to RAG systems. Lastly, our exploration of various defense mechanisms reveals that they are insufficient to counter HijackRAG, emphasizing the urgent need for more robust security measures to protect RAG systems in real-world deployments.
CoreGuard: Safeguarding Foundational Capabilities of LLMs Against Model Stealing in Edge Deployment
Oct 16, 2024



Proprietary large language models (LLMs) demonstrate exceptional generalization ability across various tasks. Additionally, deploying LLMs on edge devices is trending for efficiency and privacy reasons. However, edge deployment of proprietary LLMs introduces new security threats: attackers who obtain an edge-deployed LLM can easily use it as a base model for various tasks due to its high generalization ability, which we call foundational capability stealing. Unfortunately, existing model protection mechanisms are often task-specific and fail to protect general-purpose LLMs, as they mainly focus on protecting task-related parameters using trusted execution environments (TEEs). Although some recent TEE-based methods are able to protect the overall model parameters in a computation-efficient way, they still suffer from prohibitive communication costs between TEE and CPU/GPU, making it impractical to deploy for edge LLMs. To protect the foundational capabilities of edge LLMs, we propose CoreGuard, a computation- and communication-efficient model protection approach against model stealing on edge devices. The core component of CoreGuard is a lightweight and propagative authorization module residing in TEE. Extensive experiments show that CoreGuard achieves the same security protection as the black-box security guarantees with negligible overhead.
TransLinkGuard: Safeguarding Transformer Models Against Model Stealing in Edge Deployment
Apr 17, 2024

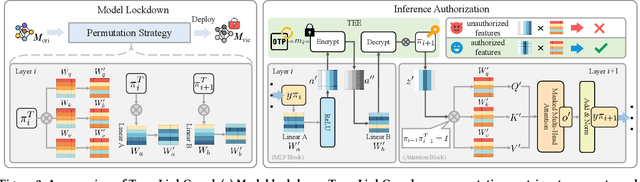

Proprietary large language models (LLMs) have been widely applied in various scenarios. Additionally, deploying LLMs on edge devices is trending for efficiency and privacy reasons. However, edge deployment of proprietary LLMs introduces new security challenges: edge-deployed models are exposed as white-box accessible to users, enabling adversaries to conduct effective model stealing (MS) attacks. Unfortunately, existing defense mechanisms fail to provide effective protection. Specifically, we identify four critical protection properties that existing methods fail to simultaneously satisfy: (1) maintaining protection after a model is physically copied; (2) authorizing model access at request level; (3) safeguarding runtime reverse engineering; (4) achieving high security with negligible runtime overhead. To address the above issues, we propose TransLinkGuard, a plug-and-play model protection approach against model stealing on edge devices. The core part of TransLinkGuard is a lightweight authorization module residing in a secure environment, e.g., TEE. The authorization module can freshly authorize each request based on its input. Extensive experiments show that TransLinkGuard achieves the same security protection as the black-box security guarantees with negligible overhead.