 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIR-to-VIS Face Recognition via Embedding Relations and Coordinates of the Pairwise Features
Aug 04, 2022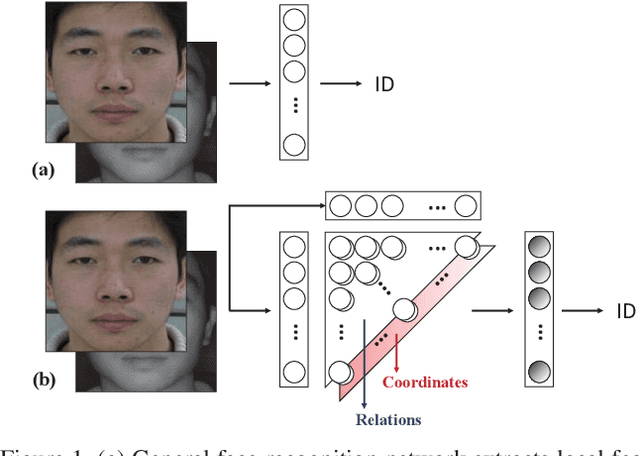

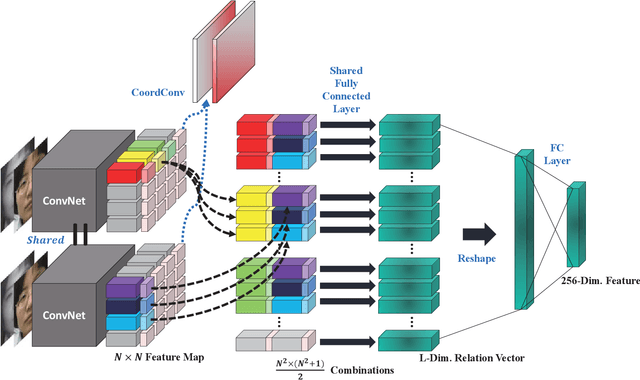
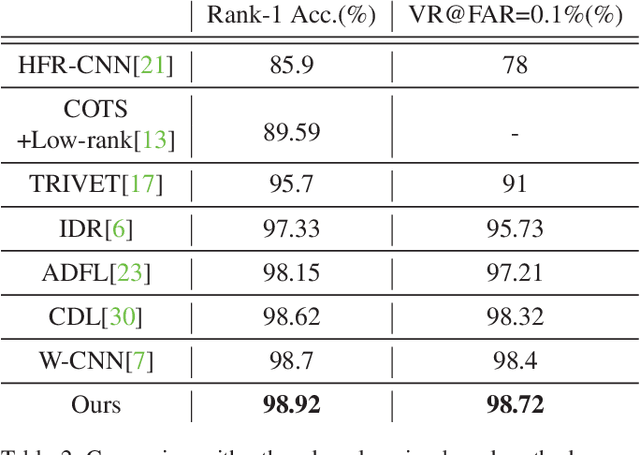
NIR-to-VIS face recognition is identifying faces of two different domains by extracting domain-invariant features. However, this is a challenging problem due to the two different domain characteristics, and the lack of NIR face dataset. In order to reduce domain discrepancy while using the existing face recognition models, we propose a 'Relation Module' which can simply add-on to any face recognition models. The local features extracted from face image contain information of each component of the face. Based on two different domain characteristics, to use the relationships between local features is more domain-invariant than to use it as it is. In addition to these relationships, positional information such as distance from lips to chin or eye to eye, also provides domain-invariant information. In our Relation Module, Relation Layer implicitly captures relationships, and Coordinates Layer models the positional information. Also, our proposed Triplet loss with conditional margin reduces intra-class variation in training, and resulting in additional performance improvements. Different from the general face recognition models, our add-on module does not need to pre-train with the large scale dataset. The proposed module fine-tuned only with CASIA NIR-VIS 2.0 database. With the proposed module, we achieve 14.81% rank-1 accuracy and 15.47% verification rate of 0.1% FAR improvements compare to two baseline models.