 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL for Consistency Models: Faster Reward Guided Text-to-Image Generation
Paper and Code
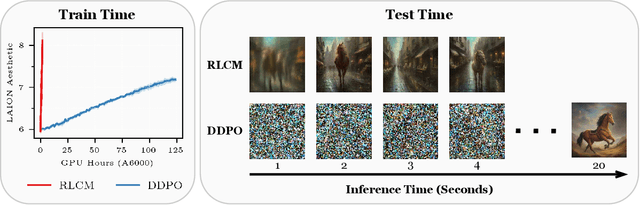
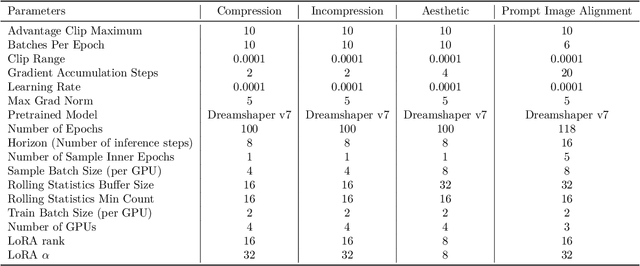
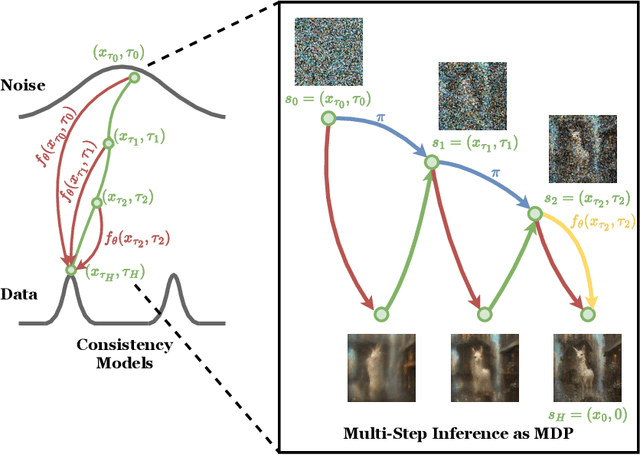

Reinforcement learning (RL) has improved guided image generation with diffusion models by directly optimizing rewards that capture image quality, aesthetics, and instruction following capabilities. However, the resulting generative policies inherit the same iterative sampling process of diffusion models that causes slow generation. To overcome this limitation, consistency models proposed learning a new class of generative models that directly map noise to data, resulting in a model that can generate an image in as few as one sampling iteration. In this work, to optimize text-to-image generative models for task specific rewards and enable fast training and inference, we propose a framework for fine-tuning consistency models via RL. Our framework, called Reinforcement Learning for Consistency Model (RLCM), frames the iterative inference process of a consistency model as an RL procedure. RLCM improves upon RL fine-tuned diffusion models on text-to-image generation capabilities and trades computation during inference time for sample quality. Experimentally, we show that RLCM can adapt text-to-image consistency models to objectives that are challenging to express with prompting, such as image compressibility, and those derived from human feedback, such as aesthetic quality. Comparing to RL finetuned diffusion models, RLCM trains significantly faster, improves the quality of the generation measured under the reward objectives, and speeds up the inference procedure by generating high quality images with as few as two inference steps. Our code is available at https://rlcm.owenoertell.com