 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Envelope of Low-Bit LLM via Dynamic Error Compensation
Dec 28, 2024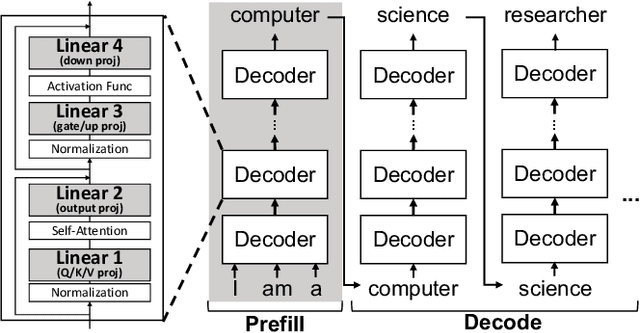
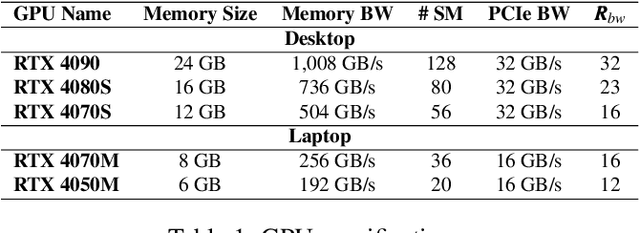

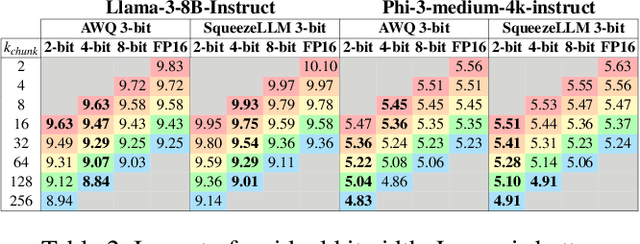
Quantization of Large Language Models (LLMs) has recently gained popularity, particularly for on-device settings with limited hardware resources. While efficient, quantization inevitably degrades model quality, especially in aggressive low-bit settings such as 3-bit and 4-bit precision. In this paper, we propose QDEC, an inference scheme that improves the quality of low-bit LLMs while preserving the key benefits of quantization: GPU memory savings and inference latency reduction. QDEC stores the residual matrix -- the difference between full-precision and quantized weights -- in CPU, and dynamically fetches the residuals for only a small portion of the weights. This portion corresponds to the salient channels, marked by activation outliers, with the fetched residuals helping to correct quantization errors in these channels. Salient channels are identified dynamically at each decoding step by analyzing the input activations -- this allows for the adaptation to the dynamic nature of activation distribution, and thus maximizes the effectiveness of error compensation. We demonstrate the effectiveness of QDEC by augmenting state-of-the-art quantization methods. For example, QDEC reduces the perplexity of a 3-bit Llama-3-8B-Instruct model from 10.15 to 9.12 -- outperforming its 3.5-bit counterpart -- while adding less than 0.0003\% to GPU memory usage and incurring only a 1.7\% inference slowdown on NVIDIA RTX 4050 Mobile GPU. The code will be publicly available soon.
Log-Time K-Means Clustering for 1D Data: Novel Approaches with Proof and Implementation
Dec 24, 2024Clustering is a key task in machine learning, with $k$-means being widely used for its simplicity and effectiveness. While 1D clustering is common, existing methods often fail to exploit the structure of 1D data, leading to inefficiencies. This thesis introduces optimized algorithms for $k$-means++ initialization and Lloyd's algorithm, leveraging sorted data, prefix sums, and binary search for improved computational performance. The main contributions are: (1) an optimized $k$-cluster algorithm achieving $O(l \cdot k^2 \cdot \log n)$ complexity for greedy $k$-means++ initialization and $O(i \cdot k \cdot \log n)$ for Lloyd's algorithm, where $l$ is the number of greedy $k$-means++ local trials, and $i$ is the number of Lloyd's algorithm iterations, and (2) a binary search-based two-cluster algorithm, achieving $O(\log n)$ runtime with deterministic convergence to a Lloyd's algorithm local minimum. Benchmarks demonstrate over a 4500x speedup compared to scikit-learn for large datasets while maintaining clustering quality measured by within-cluster sum of squares (WCSS). Additionally, the algorithms achieve a 300x speedup in an LLM quantization task, highlighting their utility in emerging applications. This thesis bridges theory and practice for 1D $k$-means clustering, delivering efficient and sound algorithms implemented in a JIT-optimized open-source Python library.
Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs
Feb 16, 2024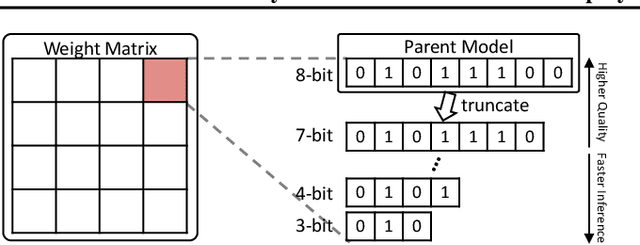
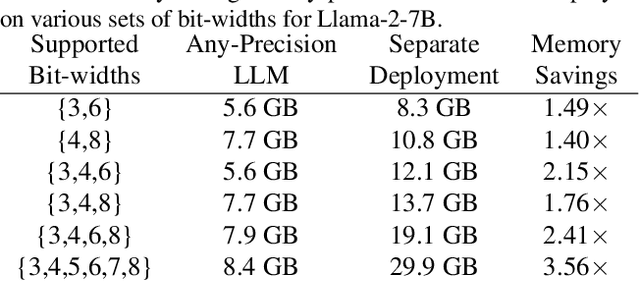
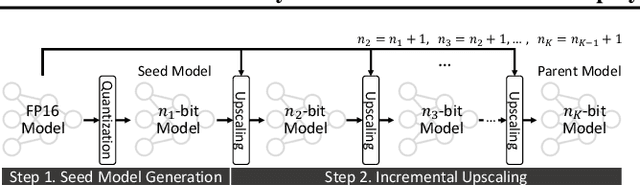
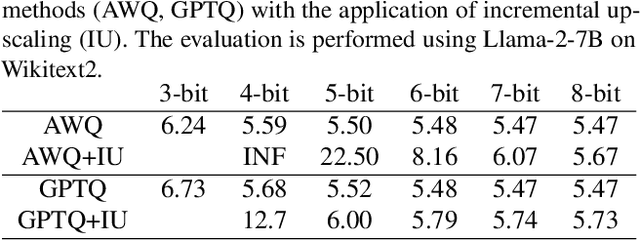
Recently, considerable efforts have been directed towards compressing Large Language Models (LLMs), which showcase groundbreaking capabilities across diverse applications but entail significant deployment costs due to their large sizes. Meanwhile, much less attention has been given to mitigating the costs associated with deploying multiple LLMs of varying sizes despite its practical significance. Thus, this paper introduces \emph{any-precision LLM}, extending the concept of any-precision DNN to LLMs. Addressing challenges in any-precision LLM, we propose a lightweight method for any-precision quantization of LLMs, leveraging a post-training quantization framework, and develop a specialized software engine for its efficient serving. As a result, our solution significantly reduces the high costs of deploying multiple, different-sized LLMs by overlaying LLMs quantized to varying bit-widths, such as 3, 4, ..., $n$ bits, into a memory footprint comparable to a single $n$-bit LLM. All the supported LLMs with varying bit-widths demonstrate state-of-the-art model quality and inference throughput, proving itself to be a compelling option for deployment of multiple, different-sized LLMs. The source code will be publicly available soon.
ZADU: A Python Library for Evaluating the Reliability of Dimensionality Reduction Embeddings
Aug 11, 2023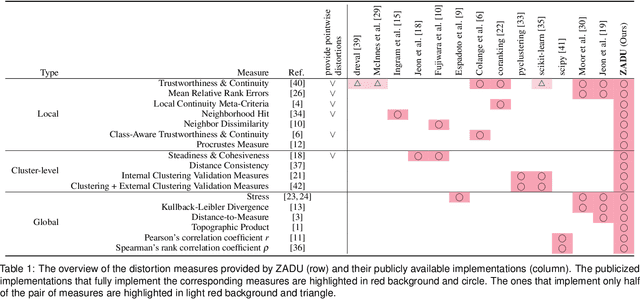

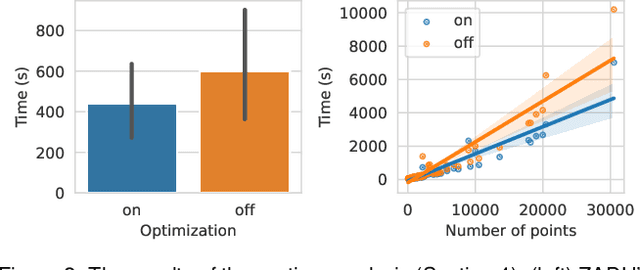
Dimensionality reduction (DR) techniques inherently distort the original structure of input high-dimensional data, producing imperfect low-dimensional embeddings. Diverse distortion measures have thus been proposed to evaluate the reliability of DR embeddings. However, implementing and executing distortion measures in practice has so far been time-consuming and tedious. To address this issue, we present ZADU, a Python library that provides distortion measures. ZADU is not only easy to install and execute but also enables comprehensive evaluation of DR embeddings through three key features. First, the library covers a wide range of distortion measures. Second, it automatically optimizes the execution of distortion measures, substantially reducing the running time required to execute multiple measures. Last, the library informs how individual points contribute to the overall distortions, facilitating the detailed analysis of DR embeddings. By simulating a real-world scenario of optimizing DR embeddings, we verify that our optimization scheme substantially reduces the time required to execute distortion measures. Finally, as an application of ZADU, we present another library called ZADUVis that allows users to easily create distortion visualizations that depict the extent to which each region of an embedding suffers from distortions.