 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCieran: Designing Sequential Colormaps via In-Situ Active Preference Learning
Feb 29, 2024Quality colormaps can help communicate important data patterns. However, finding an aesthetically pleasing colormap that looks "just right" for a given scenario requires significant design and technical expertise. We introduce Cieran, a tool that allows any data analyst to rapidly find quality colormaps while designing charts within Jupyter Notebooks. Our system employs an active preference learning paradigm to rank expert-designed colormaps and create new ones from pairwise comparisons, allowing analysts who are novices in color design to tailor colormaps to their data context. We accomplish this by treating colormap design as a path planning problem through the CIELAB colorspace with a context-specific reward model. In an evaluation with twelve scientists, we found that Cieran effectively modeled user preferences to rank colormaps and leveraged this model to create new quality designs. Our work shows the potential of active preference learning for supporting efficient visualization design optimization.
CLAMS: A Cluster Ambiguity Measure for Estimating Perceptual Variability in Visual Clustering
Aug 11, 2023Visual clustering is a common perceptual task in scatterplots that supports diverse analytics tasks (e.g., cluster identification). However, even with the same scatterplot, the ways of perceiving clusters (i.e., conducting visual clustering) can differ due to the differences among individuals and ambiguous cluster boundaries. Although such perceptual variability casts doubt on the reliability of data analysis based on visual clustering, we lack a systematic way to efficiently assess this variability. In this research, we study perceptual variability in conducting visual clustering, which we call Cluster Ambiguity. To this end, we introduce CLAMS, a data-driven visual quality measure for automatically predicting cluster ambiguity in monochrome scatterplots. We first conduct a qualitative study to identify key factors that affect the visual separation of clusters (e.g., proximity or size difference between clusters). Based on study findings, we deploy a regression module that estimates the human-judged separability of two clusters. Then, CLAMS predicts cluster ambiguity by analyzing the aggregated results of all pairwise separability between clusters that are generated by the module. CLAMS outperforms widely-used clustering techniques in predicting ground truth cluster ambiguity. Meanwhile, CLAMS exhibits performance on par with human annotators. We conclude our work by presenting two applications for optimizing and benchmarking data mining techniques using CLAMS. The interactive demo of CLAMS is available at clusterambiguity.dev.
Scholastic: Graphical Human-Al Collaboration for Inductive and Interpretive Text Analysis
Aug 12, 2022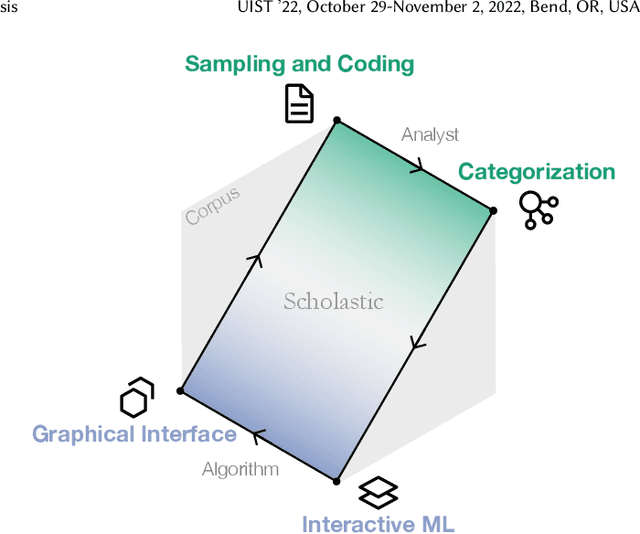
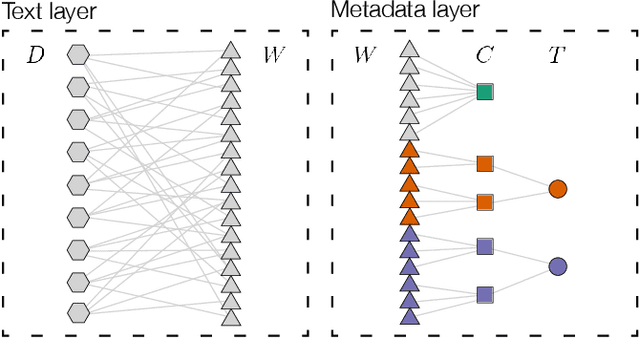
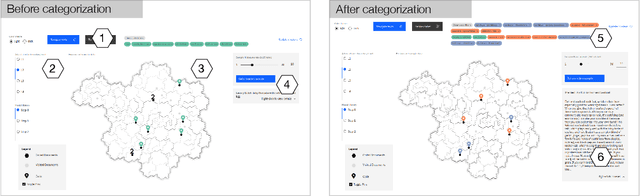
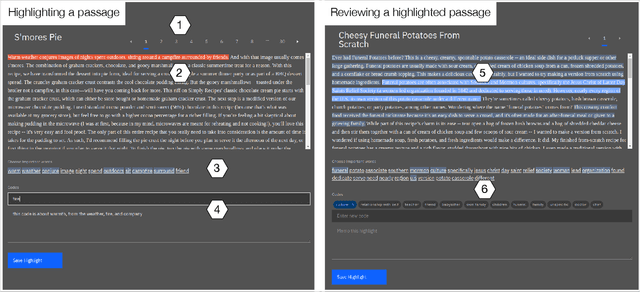
Interpretive scholars generate knowledge from text corpora by manually sampling documents, applying codes, and refining and collating codes into categories until meaningful themes emerge. Given a large corpus, machine learning could help scale this data sampling and analysis, but prior research shows that experts are generally concerned about algorithms potentially disrupting or driving interpretive scholarship. We take a human-centered design approach to addressing concerns around machine-assisted interpretive research to build Scholastic, which incorporates a machine-in-the-loop clustering algorithm to scaffold interpretive text analysis. As a scholar applies codes to documents and refines them, the resulting coding schema serves as structured metadata which constrains hierarchical document and word clusters inferred from the corpus. Interactive visualizations of these clusters can help scholars strategically sample documents further toward insights. Scholastic demonstrates how human-centered algorithm design and visualizations employing familiar metaphors can support inductive and interpretive research methodologies through interactive topic modeling and document clustering.