 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholastic: Graphical Human-Al Collaboration for Inductive and Interpretive Text Analysis
Aug 12, 2022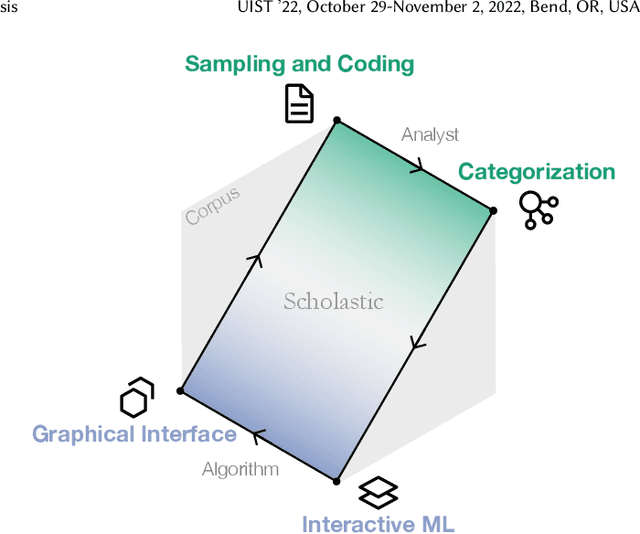
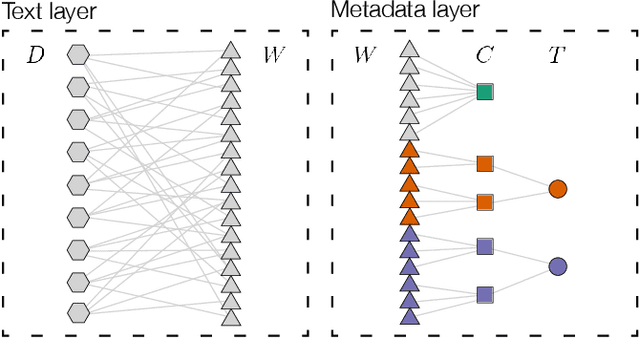
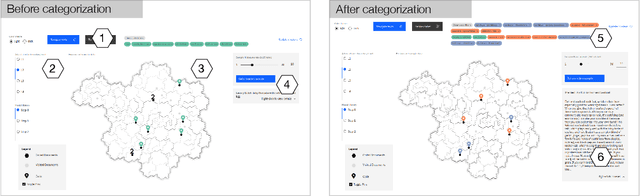
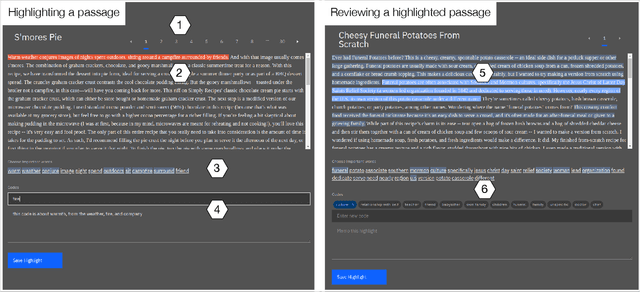
Interpretive scholars generate knowledge from text corpora by manually sampling documents, applying codes, and refining and collating codes into categories until meaningful themes emerge. Given a large corpus, machine learning could help scale this data sampling and analysis, but prior research shows that experts are generally concerned about algorithms potentially disrupting or driving interpretive scholarship. We take a human-centered design approach to addressing concerns around machine-assisted interpretive research to build Scholastic, which incorporates a machine-in-the-loop clustering algorithm to scaffold interpretive text analysis. As a scholar applies codes to documents and refines them, the resulting coding schema serves as structured metadata which constrains hierarchical document and word clusters inferred from the corpus. Interactive visualizations of these clusters can help scholars strategically sample documents further toward insights. Scholastic demonstrates how human-centered algorithm design and visualizations employing familiar metaphors can support inductive and interpretive research methodologies through interactive topic modeling and document clustering.