 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Character Identification and Speaker Prediction in Comics via Iterative Multimodal Fusion
Apr 24, 2024

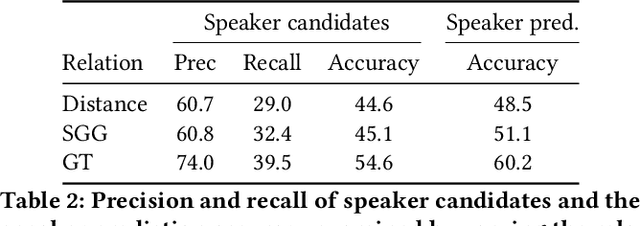

Recognizing characters and predicting speakers of dialogue are critical for comic processing tasks, such as voice generation or translation. However, because characters vary by comic title, supervised learning approaches like training character classifiers which require specific annotations for each comic title are infeasible. This motivates us to propose a novel zero-shot approach, allowing machines to identify characters and predict speaker names based solely on unannotated comic images. In spite of their importance in real-world applications, these task have largely remained unexplored due to challenges in story comprehension and multimodal integration. Recent large language models (LLMs) have shown great capability for text understanding and reasoning, while their application to multimodal content analysis is still an open problem. To address this problem, we propose an iterative multimodal framework, the first to employ multimodal information for both character identification and speaker prediction tasks. Our experiments demonstrate the effectiveness of the proposed framework, establishing a robust baseline for these tasks. Furthermore, since our method requires no training data or annotations, it can be used as-is on any comic series.
Painting Style-Aware Manga Colorization Based on Generative Adversarial Networks
Jul 16, 2021
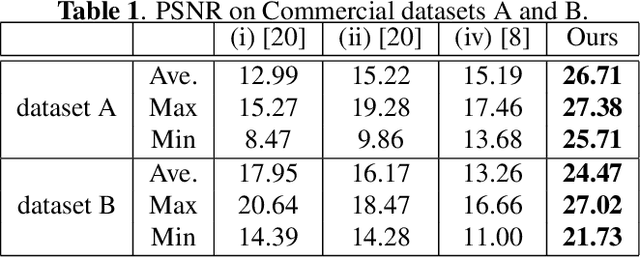
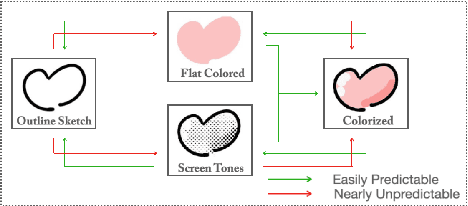
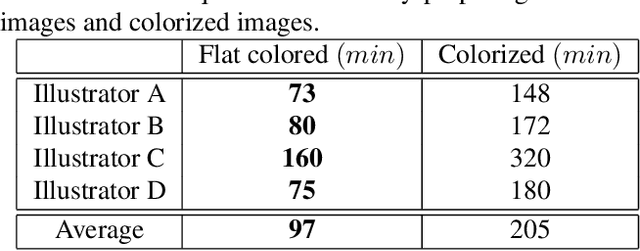
Japanese comics (called manga) are traditionally created in monochrome format. In recent years, in addition to monochrome comics, full color comics, a more attractive medium, have appeared. Unfortunately, color comics require manual colorization, which incurs high labor costs. Although automatic colorization methods have been recently proposed, most of them are designed for illustrations, not for comics. Unlike illustrations, since comics are composed of many consecutive images, the painting style must be consistent. To realize consistent colorization, we propose here a semi-automatic colorization method based on generative adversarial networks (GAN); the method learns the painting style of a specific comic from small amount of training data. The proposed method takes a pair of a screen tone image and a flat colored image as input, and outputs a colorized image. Experiments show that the proposed method achieves better performance than the existing alternatives.
Towards Fully Automated Manga Translation
Jan 09, 2021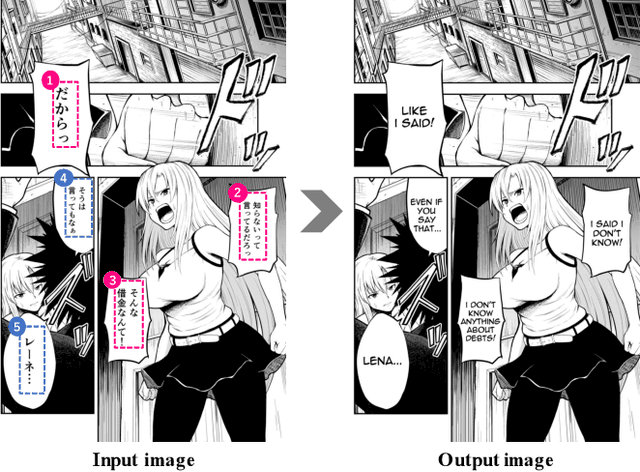
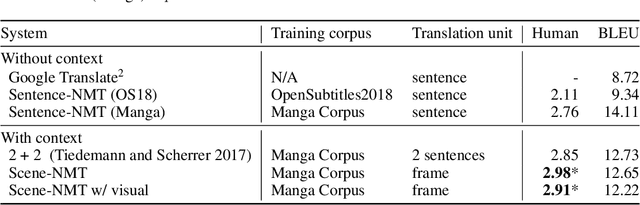
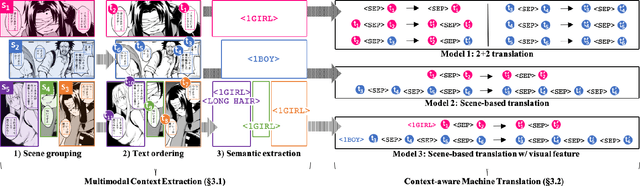
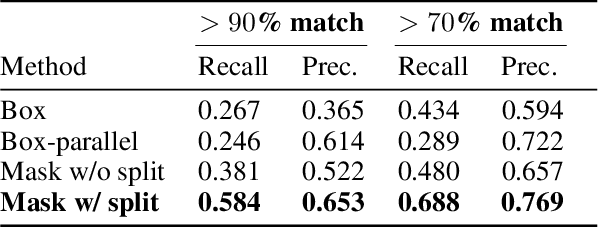
We tackle the problem of machine translation of manga, Japanese comics. Manga translation involves two important problems in machine translation: context-aware and multimodal translation. Since text and images are mixed up in an unstructured fashion in Manga, obtaining context from the image is essential for manga translation. However, it is still an open problem how to extract context from image and integrate into MT models. In addition, corpus and benchmarks to train and evaluate such model is currently unavailable. In this paper, we make the following four contributions that establishes the foundation of manga translation research. First, we propose multimodal context-aware translation framework. We are the first to incorporate context information obtained from manga image. It enables us to translate texts in speech bubbles that cannot be translated without using context information (e.g., texts in other speech bubbles, gender of speakers, etc.). Second, for training the model, we propose the approach to automatic corpus construction from pairs of original manga and their translations, by which large parallel corpus can be constructed without any manual labeling. Third, we created a new benchmark to evaluate manga translation. Finally, on top of our proposed methods, we devised a first comprehensive system for fully automated manga translation.
Efficient Image Retrieval via Decoupling Diffusion into Online and Offline Processing
Nov 27, 2018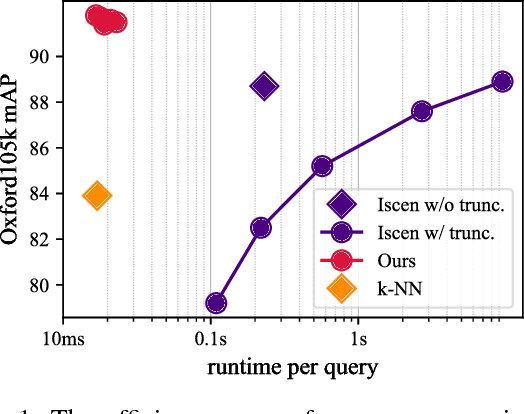
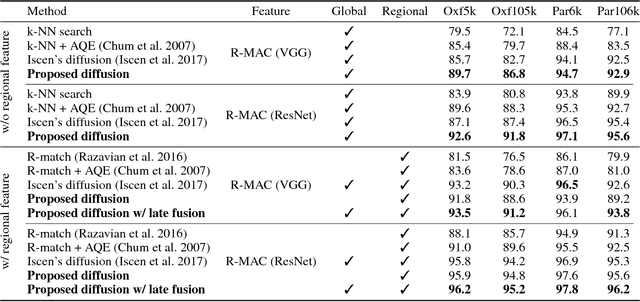
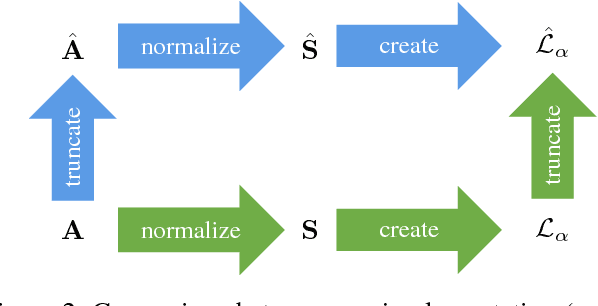
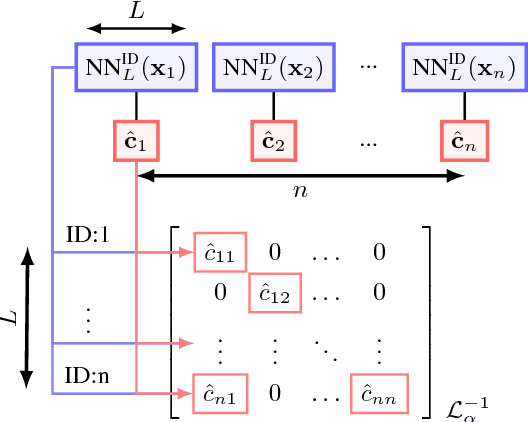
Diffusion is commonly used as a ranking or re-ranking method in retrieval tasks to achieve higher retrieval performance, and has attracted lots of attention in recent years. A downside to diffusion is that it performs slowly in comparison to the naive k-NN search, which causes a non-trivial online computational cost on large datasets. To overcome this weakness, we propose a novel diffusion technique in this paper. In our work, instead of applying diffusion to the query, we pre-compute the diffusion results of each element in the database, making the online search a simple linear combination on top of the k-NN search process. Our proposed method becomes 10~ times faster in terms of online search speed. Moreover, we propose to use late truncation instead of early truncation in previous works to achieve better retrieval performance.
Discriminative Learning of Open-Vocabulary Object Retrieval and Localization by Negative Phrase Augmentation
Sep 04, 2018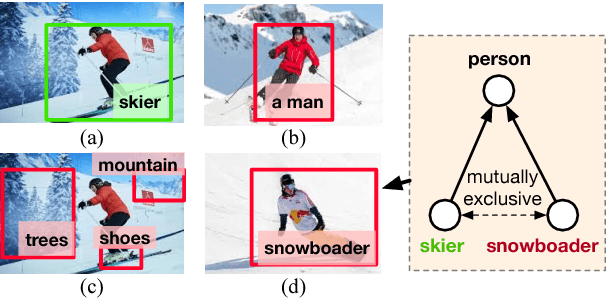
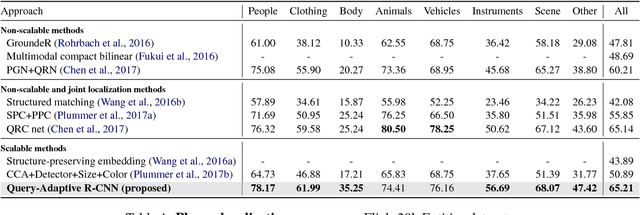

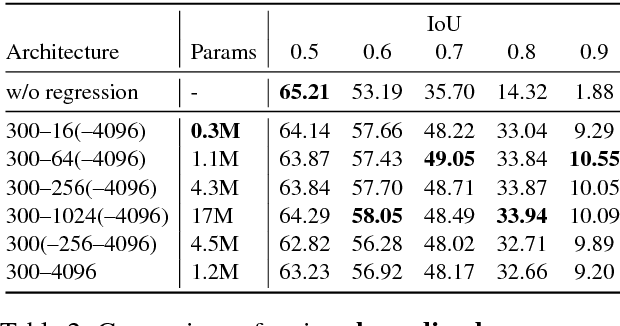
Thanks to the success of object detection technology, we can retrieve objects of the specified classes even from huge image collections. However, the current state-of-the-art object detectors (such as Faster R-CNN) can only handle pre-specified classes. In addition, large amounts of positive and negative visual samples are required for training. In this paper, we address the problem of open-vocabulary object retrieval and localization, where the target object is specified by a textual query (e.g., a word or phrase). We first propose Query-Adaptive R-CNN, a simple extension of Faster R-CNN adapted to open-vocabulary queries, by transforming the text embedding vector into an object classifier and localization regressor. Then, for discriminative training, we then propose negative phrase augmentation (NPA) to mine hard negative samples which are visually similar to the query and at the same time semantically mutually exclusive of the query. The proposed method can retrieve and localize objects specified by a textual query from one million images in only 0.5 seconds with high precision.
Reconfigurable Inverted Index
Aug 12, 2018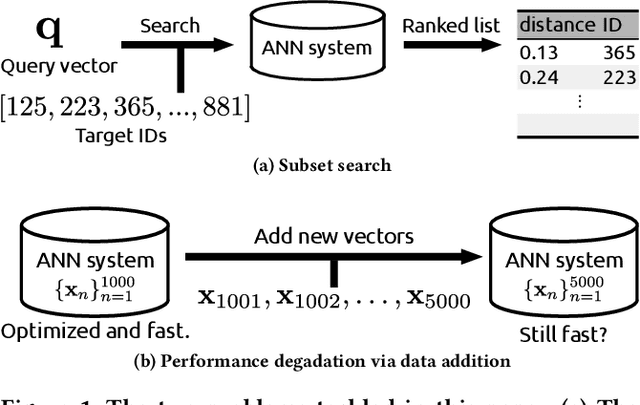

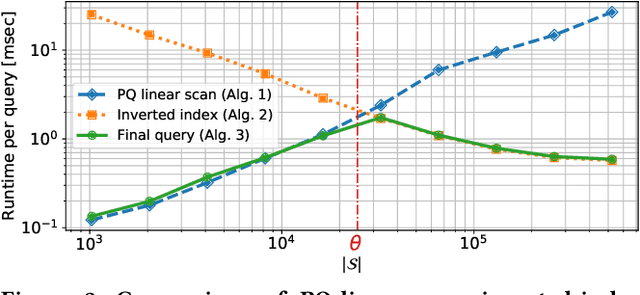
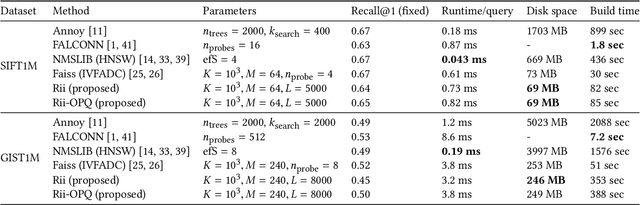
Existing approximate nearest neighbor search systems suffer from two fundamental problems that are of practical importance but have not received sufficient attention from the research community. First, although existing systems perform well for the whole database, it is difficult to run a search over a subset of the database. Second, there has been no discussion concerning the performance decrement after many items have been newly added to a system. We develop a reconfigurable inverted index (Rii) to resolve these two issues. Based on the standard IVFADC system, we design a data layout such that items are stored linearly. This enables us to efficiently run a subset search by switching the search method to a linear PQ scan if the size of a subset is small. Owing to the linear layout, the data structure can be dynamically adjusted after new items are added, maintaining the fast speed of the system. Extensive comparisons show that Rii achieves a comparable performance with state-of-the art systems such as Faiss.
Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge
Sep 26, 2017
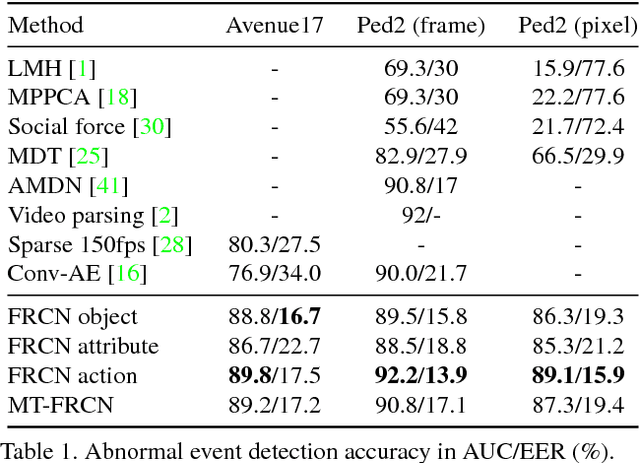

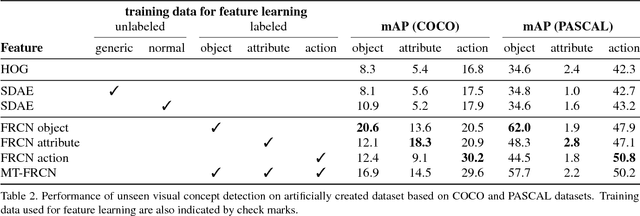
This paper addresses the problem of joint detection and recounting of abnormal events in videos. Recounting of abnormal events, i.e., explaining why they are judged to be abnormal, is an unexplored but critical task in video surveillance, because it helps human observers quickly judge if they are false alarms or not. To describe the events in the human-understandable form for event recounting, learning generic knowledge about visual concepts (e.g., object and action) is crucial. Although convolutional neural networks (CNNs) have achieved promising results in learning such concepts, it remains an open question as to how to effectively use CNNs for abnormal event detection, mainly due to the environment-dependent nature of the anomaly detection. In this paper, we tackle this problem by integrating a generic CNN model and environment-dependent anomaly detectors. Our approach first learns CNN with multiple visual tasks to exploit semantic information that is useful for detecting and recounting abnormal events. By appropriately plugging the model into anomaly detectors, we can detect and recount abnormal events while taking advantage of the discriminative power of CNNs. Our approach outperforms the state-of-the-art on Avenue and UCSD Ped2 benchmarks for abnormal event detection and also produces promising results of abnormal event recounting.
Region-Based Image Retrieval Revisited
Sep 26, 2017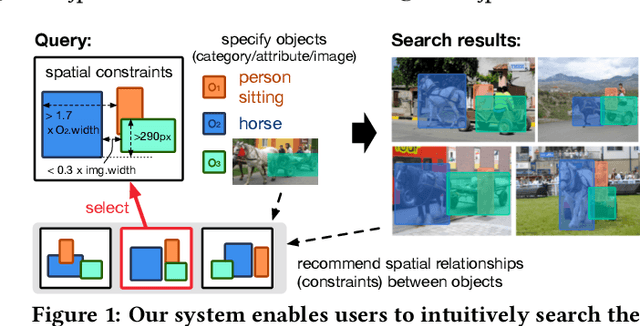

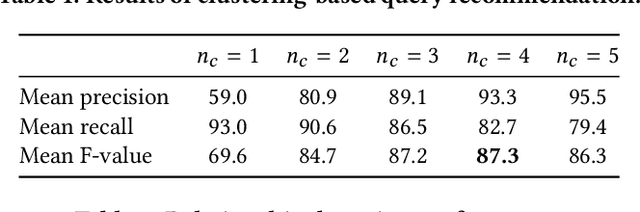
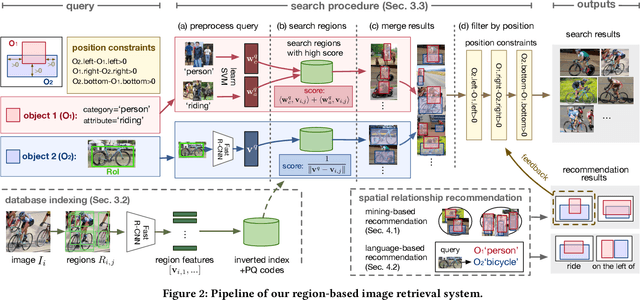
Region-based image retrieval (RBIR) technique is revisited. In early attempts at RBIR in the late 90s, researchers found many ways to specify region-based queries and spatial relationships; however, the way to characterize the regions, such as by using color histograms, were very poor at that time. Here, we revisit RBIR by incorporating semantic specification of objects and intuitive specification of spatial relationships. Our contributions are the following. First, to support multiple aspects of semantic object specification (category, instance, and attribute), we propose a multitask CNN feature that allows us to use deep learning technique and to jointly handle multi-aspect object specification. Second, to help users specify spatial relationships among objects in an intuitive way, we propose recommendation techniques of spatial relationships. In particular, by mining the search results, a system can recommend feasible spatial relationships among the objects. The system also can recommend likely spatial relationships by assigned object category names based on language prior. Moreover, object-level inverted indexing supports very fast shortlist generation, and re-ranking based on spatial constraints provides users with instant RBIR experiences.