 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample, Don't Search: Rethinking Test-Time Alignment for Language Models
Apr 04, 2025Increasing test-time computation has emerged as a promising direction for improving language model performance, particularly in scenarios where model finetuning is impractical or impossible due to computational constraints or private model weights. However, existing test-time search methods using a reward model (RM) often degrade in quality as compute scales, due to the over-optimization of what are inherently imperfect reward proxies. We introduce QAlign, a new test-time alignment approach. As we scale test-time compute, QAlign converges to sampling from the optimal aligned distribution for each individual prompt. By adopting recent advances in Markov chain Monte Carlo for text generation, our method enables better-aligned outputs without modifying the underlying model or even requiring logit access. We demonstrate the effectiveness of QAlign on mathematical reasoning benchmarks (GSM8K and GSM-Symbolic) using a task-specific RM, showing consistent improvements over existing test-time compute methods like best-of-n and majority voting. Furthermore, when applied with more realistic RMs trained on the Tulu 3 preference dataset, QAlign outperforms direct preference optimization (DPO), best-of-n, majority voting, and weighted majority voting on a diverse range of datasets (GSM8K, MATH500, IFEval, MMLU-Redux, and TruthfulQA). A practical solution to aligning language models at test time using additional computation without degradation, our approach expands the limits of the capability that can be obtained from off-the-shelf language models without further training.
Modeling User Preferences with Automatic Metrics: Creating a High-Quality Preference Dataset for Machine Translation
Oct 10, 2024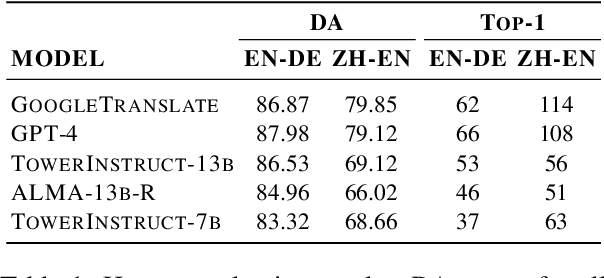

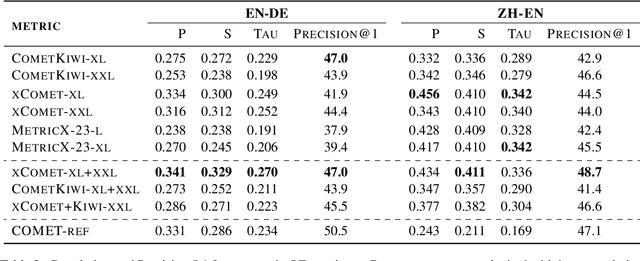
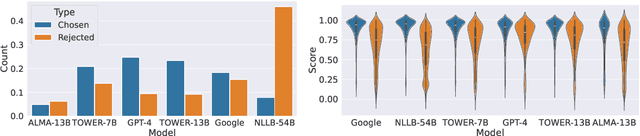
Alignment with human preferences is an important step in developing accurate and safe large language models. This is no exception in machine translation (MT), where better handling of language nuances and context-specific variations leads to improved quality. However, preference data based on human feedback can be very expensive to obtain and curate at a large scale. Automatic metrics, on the other hand, can induce preferences, but they might not match human expectations perfectly. In this paper, we propose an approach that leverages the best of both worlds. We first collect sentence-level quality assessments from professional linguists on translations generated by multiple high-quality MT systems and evaluate the ability of current automatic metrics to recover these preferences. We then use this analysis to curate a new dataset, MT-Pref (metric induced translation preference) dataset, which comprises 18k instances covering 18 language directions, using texts sourced from multiple domains post-2022. We show that aligning TOWER models on MT-Pref significantly improves translation quality on WMT23 and FLORES benchmarks.
Learning to compute inner consensus -- A noble approach to modeling agreement between Capsules
Sep 27, 2019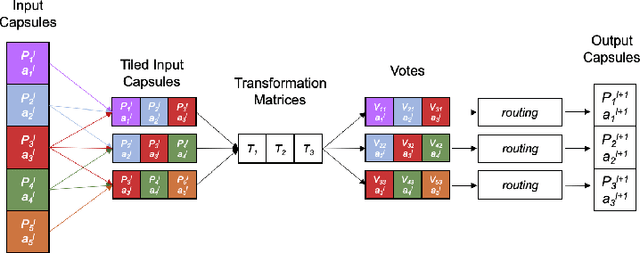



This project considers Capsule Networks, a recently introduced machine learning model that has shown promising results regarding generalization and preservation of spatial information with few parameters. The Capsule Network's inner routing procedures thus far proposed, a priori, establish how the routing relations are modeled, which limits the expressiveness of the underlying model. In this project, we propose two distinct ways in which the routing procedure can be learned like any other network parameter.