 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Understand Your Translations? Evaluating Paragraph-level MT with Question Answering
Paper and Code
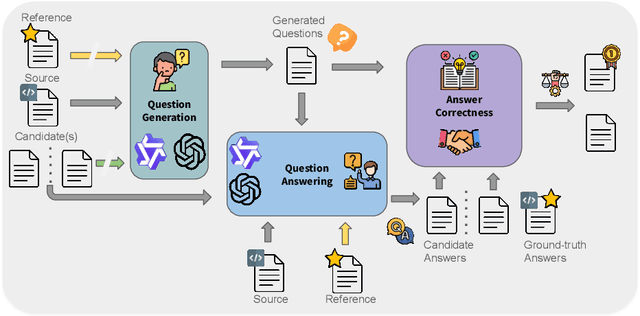
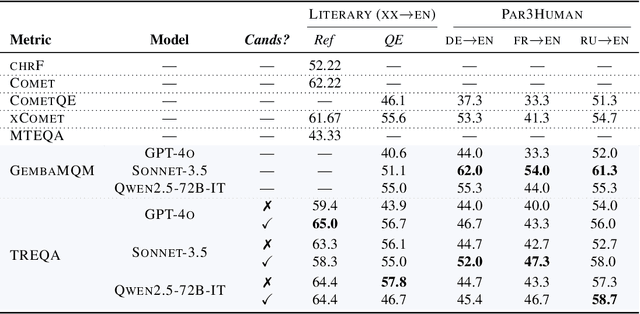

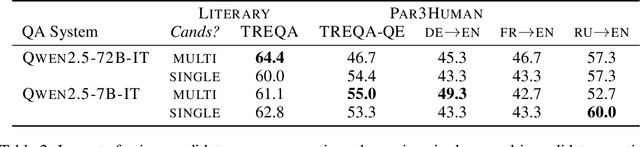
Despite the steady progress in machine translation evaluation, existing automatic metrics struggle to capture how well meaning is preserved beyond sentence boundaries. We posit that reliance on a single intrinsic quality score, trained to mimic human judgments, might be insufficient for evaluating translations of long, complex passages, and a more ``pragmatic'' approach that assesses how accurately key information is conveyed by a translation in context is needed. We introduce TREQA (Translation Evaluation via Question-Answering), a framework that extrinsically evaluates translation quality by assessing how accurately candidate translations answer reading comprehension questions that target key information in the original source or reference texts. In challenging domains that require long-range understanding, such as literary texts, we show that TREQA is competitive with and, in some cases, outperforms state-of-the-art neural and LLM-based metrics in ranking alternative paragraph-level translations, despite never being explicitly optimized to correlate with human judgments. Furthermore, the generated questions and answers offer interpretability: empirical analysis shows that they effectively target translation errors identified by experts in evaluated datasets. Our code is available at https://github.com/deep-spin/treqa