 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Reward Optimization for Machine Translation using Error Severity Mappings
Paper and Code
Nov 08, 2024
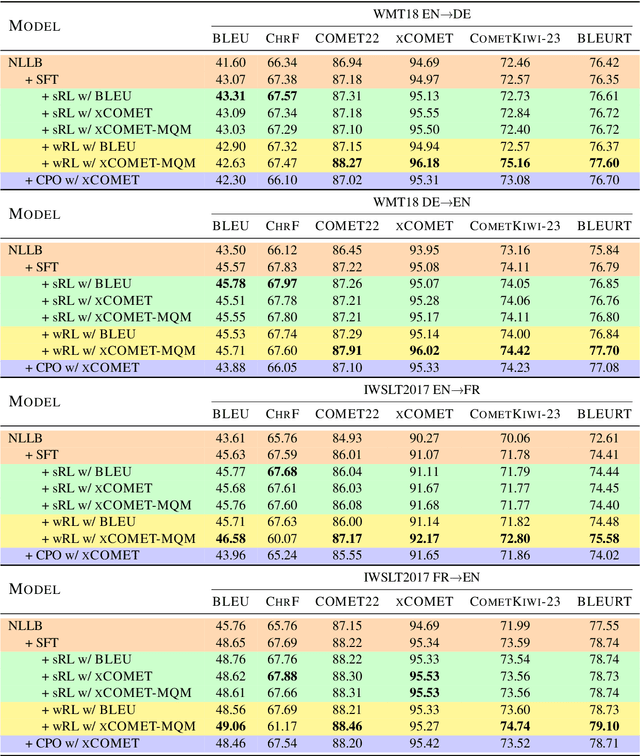
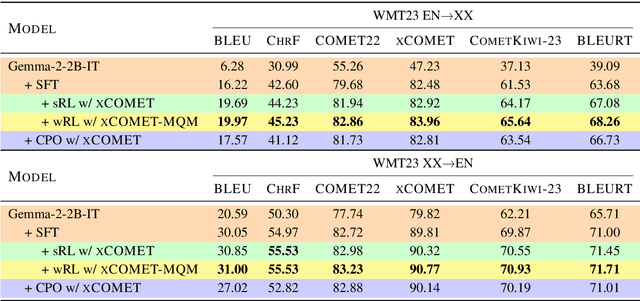
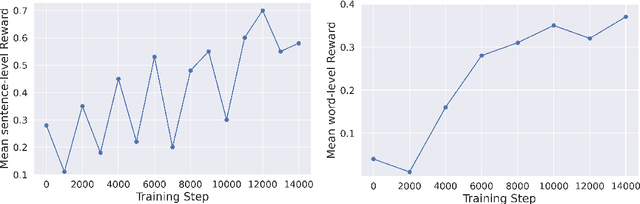
Reinforcement learning (RL) has been proven to be an effective and robust method for training neural machine translation systems, especially when paired with powerful reward models that accurately assess translation quality. However, most research has focused on RL methods that use sentence-level feedback, which leads to inefficient learning signals due to the reward sparsity problem -- the model receives a single score for the entire sentence. To address this, we introduce a novel approach that leverages fine-grained token-level reward mechanisms with RL methods. We use xCOMET, a state-of-the-art quality estimation system as our token-level reward model. xCOMET provides detailed feedback by predicting fine-grained error spans and their severity given source-translation pairs. We conduct experiments on small and large translation datasets to compare the impact of sentence-level versus fine-grained reward signals on translation quality. Our results show that training with token-level rewards improves translation quality across language pairs over baselines according to automatic and human evaluation. Furthermore, token-level reward optimization also improves training stability, evidenced by a steady increase in mean rewards over training epochs.