 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs
Paper and Code
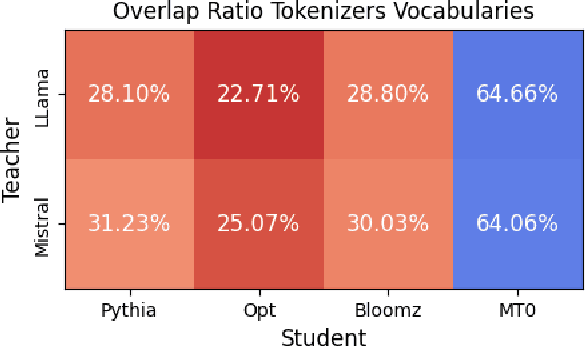

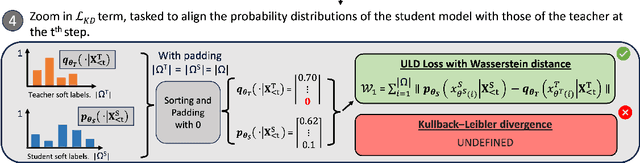
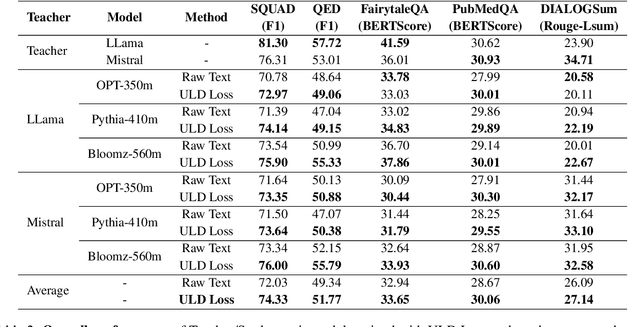
Deploying large language models (LLMs) of several billion parameters can be impractical in most industrial use cases due to constraints such as cost, latency limitations, and hardware accessibility. Knowledge distillation (KD) offers a solution by compressing knowledge from resource-intensive large models to smaller ones. Various strategies exist, some relying on the text generated by the teacher model and optionally utilizing his logits to enhance learning. However, these methods based on logits often require both teacher and student models to share the same tokenizer, limiting their applicability across different LLM families. In this paper, we introduce Universal Logit Distillation (ULD) loss, grounded in optimal transport, to address this limitation. Our experimental results demonstrate the effectiveness of ULD loss in enabling distillation across models with different architectures and tokenizers, paving the way to a more widespread use of distillation techniques.