 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything, Everywhere, All at Once: Is Mechanistic Interpretability Identifiable?
Paper and Code
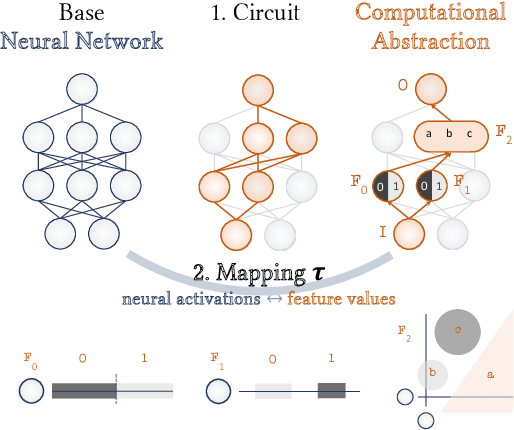
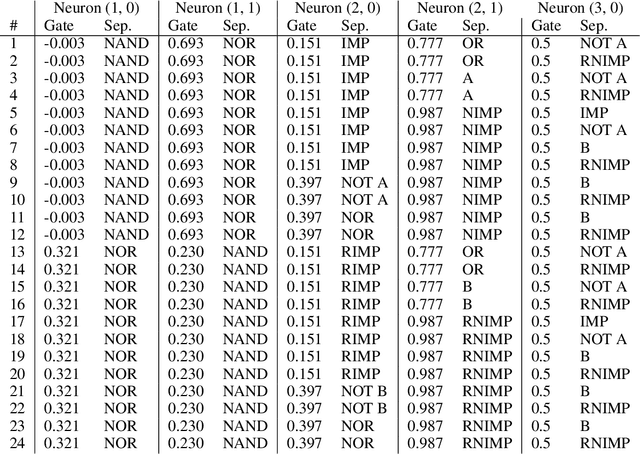
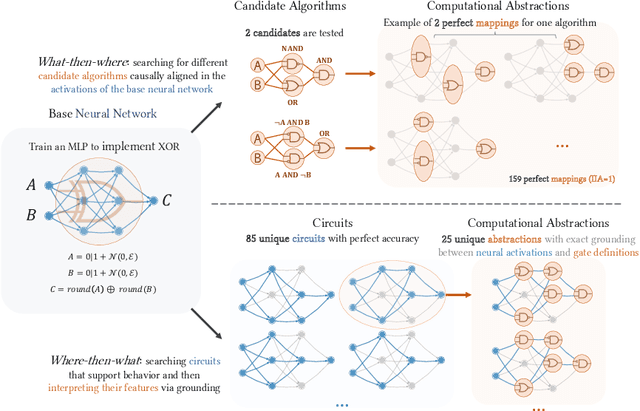

As AI systems are used in high-stakes applications, ensuring interpretability is crucial. Mechanistic Interpretability (MI) aims to reverse-engineer neural networks by extracting human-understandable algorithms to explain their behavior. This work examines a key question: for a given behavior, and under MI's criteria, does a unique explanation exist? Drawing on identifiability in statistics, where parameters are uniquely inferred under specific assumptions, we explore the identifiability of MI explanations. We identify two main MI strategies: (1) "where-then-what," which isolates a circuit replicating model behavior before interpreting it, and (2) "what-then-where," which starts with candidate algorithms and searches for neural activation subspaces implementing them, using causal alignment. We test both strategies on Boolean functions and small multi-layer perceptrons, fully enumerating candidate explanations. Our experiments reveal systematic non-identifiability: multiple circuits can replicate behavior, a circuit can have multiple interpretations, several algorithms can align with the network, and one algorithm can align with different subspaces. Is uniqueness necessary? A pragmatic approach may require only predictive and manipulability standards. If uniqueness is essential for understanding, stricter criteria may be needed. We also reference the inner interpretability framework, which validates explanations through multiple criteria. This work contributes to defining explanation standards in AI.