 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
EgoBlur: Responsible Innovation in Aria
Sep 06, 2023

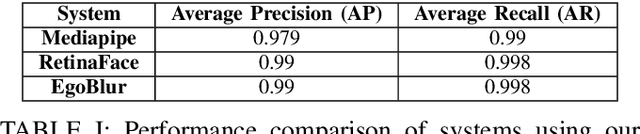
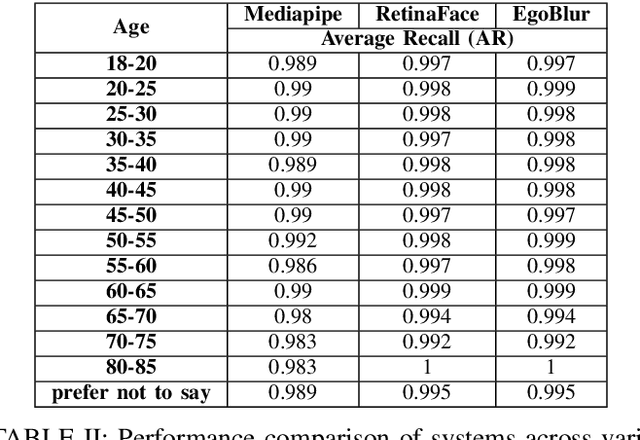
Project Aria pushes the frontiers of Egocentric AI with large-scale real-world data collection using purposely designed glasses with privacy first approach. To protect the privacy of bystanders being recorded by the glasses, our research protocols are designed to ensure recorded video is processed by an AI anonymization model that removes bystander faces and vehicle license plates. Detected face and license plate regions are processed with a Gaussian blur such that these personal identification information (PII) regions are obscured. This process helps to ensure that anonymized versions of the video is retained for research purposes. In Project Aria, we have developed a state-of-the-art anonymization system EgoBlur. In this paper, we present extensive analysis of EgoBlur on challenging datasets comparing its performance with other state-of-the-art systems from industry and academia including extensive Responsible AI analysis on recently released Casual Conversations V2 dataset.
IIITM Face: A Database for Facial Attribute Detection in Constrained and Simulated Unconstrained Environments
Oct 02, 2019



This paper addresses the challenges of face attribute detection specifically in the Indian context. While there are numerous face datasets in unconstrained environments, none of them captures emotions in different face orientations. Moreover, there is an under-representation of people of Indian ethnicity in these datasets since they have been scraped from popular search engines. As a result, the performance of state-of-the-art techniques can't be evaluated on Indian faces. In this work, we introduce a new dataset, IIITM Face, for the scientific community to address these challenges. Our dataset includes 107 participants who exhibit 6 emotions in 3 different face orientations. Each of these images is further labelled on attributes like gender, presence of moustache, beard or eyeglasses, clothes worn by the subjects and the density of their hair. Moreover, the images are captured in high resolution with specific background colors which can be easily replaced by cluttered backgrounds to simulate `in the Wild' behaviour. We demonstrate the same by constructing IIITM Face-SUE. Both IIITM Face and IIITM Face-SUE have been benchmarked across key multi-label metrics for the research community to compare their results.