 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAI for Systems: Recurring Challenges and Design Principles from Software to Silicon
Feb 16, 2026Generative AI is reshaping how computing systems are designed, optimized, and built, yet research remains fragmented across software, architecture, and chip design communities. This paper takes a cross-stack perspective, examining how generative models are being applied from code generation and distributed runtimes through hardware design space exploration to RTL synthesis, physical layout, and verification. Rather than reviewing each layer in isolation, we analyze how the same structural difficulties and effective responses recur across the stack. Our central finding is one of convergence. Despite the diversity of domains and tools, the field keeps encountering five recurring challenges (the feedback loop crisis, the tacit knowledge problem, trust and validation, co-design across boundaries, and the shift from determinism to dynamism) and keeps arriving at five design principles that independently emerge as effective responses (embracing hybrid approaches, designing for continuous feedback, separating concerns by role, matching methods to problem structure, and building on decades of systems knowledge). We organize these into a challenge--principle map that serves as a diagnostic and design aid, showing which principles have proven effective for which challenges across layers. Through concrete cross-stack examples, we show how systems navigate this map as they mature, and argue that the field needs shared engineering methodology, including common vocabularies, cross-layer benchmarks, and systematic design practices, so that progress compounds across communities rather than being rediscovered in each one. Our analysis covers more than 275 papers spanning eleven application areas across three layers of the computing stack, and distills open research questions that become visible only from a cross-layer vantage point.
A Critical Look at Targeted Instruction Selection: Disentangling What Matters (and What Doesn't)
Feb 16, 2026Instruction fine-tuning of large language models (LLMs) often involves selecting a subset of instruction training data from a large candidate pool, using a small query set from the target task. Despite growing interest, the literature on targeted instruction selection remains fragmented and opaque: methods vary widely in selection budgets, often omit zero-shot baselines, and frequently entangle the contributions of key components. As a result, practitioners lack actionable guidance on selecting instructions for their target tasks. In this work, we aim to bring clarity to this landscape by disentangling and systematically analyzing the two core ingredients: data representation and selection algorithms. Our framework enables controlled comparisons across models, tasks, and budgets. We find that only gradient-based data representations choose subsets whose similarity to the query consistently predicts performance across datasets and models. While no single method dominates, gradient-based representations paired with a greedy round-robin selection algorithm tend to perform best on average at low budgets, but these benefits diminish at larger budgets. Finally, we unify several existing selection algorithms as forms of approximate distance minimization between the selected subset and the query set, and support this view with new generalization bounds. More broadly, our findings provide critical insights and a foundation for more principled data selection in LLM fine-tuning. The code is available at https://github.com/dcml-lab/targeted-instruction-selection.
A Dual Perspective on Decision-Focused Learning: Scalable Training via Dual-Guided Surrogates
Nov 07, 2025Many real-world decisions are made under uncertainty by solving optimization problems using predicted quantities. This predict-then-optimize paradigm has motivated decision-focused learning, which trains models with awareness of how the optimizer uses predictions, improving the performance of downstream decisions. Despite its promise, scaling is challenging: state-of-the-art methods either differentiate through a solver or rely on task-specific surrogates, both of which require frequent and expensive calls to an optimizer, often a combinatorial one. In this paper, we leverage dual variables from the downstream problem to shape learning and introduce Dual-Guided Loss (DGL), a simple, scalable objective that preserves decision alignment while reducing solver dependence. We construct DGL specifically for combinatorial selection problems with natural one-of-many constraints, such as matching, knapsack, and shortest path. Our approach (a) decouples optimization from gradient updates by solving the downstream problem only periodically; (b) between refreshes, trains on dual-adjusted targets using simple differentiable surrogate losses; and (c) as refreshes become less frequent, drives training cost toward standard supervised learning while retaining strong decision alignment. We prove that DGL has asymptotically diminishing decision regret, analyze runtime complexity, and show on two problem classes that DGL matches or exceeds state-of-the-art DFL methods while using far fewer solver calls and substantially less training time. Code is available at https://github.com/paularodr/Dual-Guided-Learning.
Optimizing Vital Sign Monitoring in Resource-Constrained Maternal Care: An RL-Based Restless Bandit Approach
Oct 10, 2024

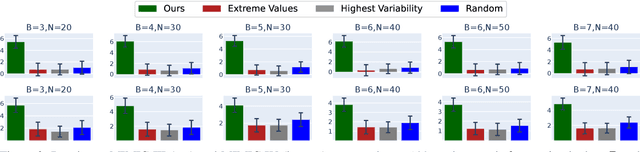
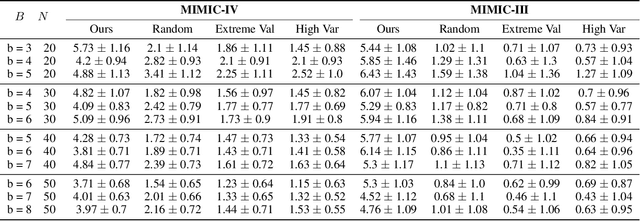
Maternal mortality remains a significant global public health challenge. One promising approach to reducing maternal deaths occurring during facility-based childbirth is through early warning systems, which require the consistent monitoring of mothers' vital signs after giving birth. Wireless vital sign monitoring devices offer a labor-efficient solution for continuous monitoring, but their scarcity raises the critical question of how to allocate them most effectively. We devise an allocation algorithm for this problem by modeling it as a variant of the popular Restless Multi-Armed Bandit (RMAB) paradigm. In doing so, we identify and address novel, previously unstudied constraints unique to this domain, which render previous approaches for RMABs unsuitable and significantly increase the complexity of the learning and planning problem. To overcome these challenges, we adopt the popular Proximal Policy Optimization (PPO) algorithm from reinforcement learning to learn an allocation policy by training a policy and value function network. We demonstrate in simulations that our approach outperforms the best heuristic baseline by up to a factor of $4$.
What is the Right Notion of Distance between Predict-then-Optimize Tasks?
Sep 11, 2024Comparing datasets is a fundamental task in machine learning, essential for various learning paradigms; from evaluating train and test datasets for model generalization to using dataset similarity for detecting data drift. While traditional notions of dataset distances offer principled measures of similarity, their utility has largely been assessed through prediction error minimization. However, in Predict-then-Optimize (PtO) frameworks, where predictions serve as inputs for downstream optimization tasks, model performance is measured through decision regret minimization rather than prediction error minimization. In this work, we (i) show that traditional dataset distances, which rely solely on feature and label dimensions, lack informativeness in the PtO context, and (ii) propose a new dataset distance that incorporates the impacts of downstream decisions. Our results show that this decision-aware dataset distance effectively captures adaptation success in PtO contexts, providing a PtO adaptation bound in terms of dataset distance. Empirically, we show that our proposed distance measure accurately predicts transferability across three different PtO tasks from the literature.