 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Supply Chain Transparency in Emerging Economies Using Online Contents and LLMs
Dec 22, 2024



In the current global economy, supply chain transparency plays a pivotal role in ensuring this security by enabling companies to monitor supplier performance and fostering accountability and responsibility. Despite the advancements in supply chain relationship datasets like Bloomberg and FactSet, supply chain transparency remains a significant challenge in emerging economies due to issues such as information asymmetry and institutional gaps in regulation. This study proposes a novel approach to enhance supply chain transparency in emerging economies by leveraging online content and large language models (LLMs). We develop a Supply Chain Knowledge Graph Mining System that integrates advanced LLMs with web crawler technology to automatically collect and analyze supply chain information. The system's effectiveness is validated through a case study focusing on the semiconductor supply chain, a domain that has recently gained significant attention due to supply chain risks. Our results demonstrate that the proposed system provides greater applicability for emerging economies, such as mainland China, complementing the data gaps in existing datasets. However, challenges including the accurate estimation of monetary and material flows, the handling of time series data, synonyms disambiguation, and mitigating biases from online contents still remains. Future research should focus on addressing these issues to further enhance the system's capabilities and broaden its application to other emerging economies and industries.
LCVO: An Efficient Pretraining-Free Framework for Visual Question Answering Grounding
Jan 29, 2024



In this paper, the LCVO modular method is proposed for the Visual Question Answering (VQA) Grounding task in the vision-language multimodal domain. This approach relies on a frozen large language model (LLM) as intermediate mediator between the off-the-shelf VQA model and the off-the-shelf Open-Vocabulary Object Detection (OVD) model, where the LLM transforms and conveys textual information between the two modules based on a designed prompt. LCVO establish an integrated plug-and-play framework without the need for any pre-training process. This framework can be deployed for VQA Grounding tasks under low computational resources. The modularized model within the framework allows application with various state-of-the-art pre-trained models, exhibiting significant potential to be advance with the times. Experimental implementations were conducted under constrained computational and memory resources, evaluating the proposed method's performance on benchmark datasets including GQA, CLEVR, and VizWiz-VQA-Grounding. Comparative analyses with baseline methods demonstrate the robust competitiveness of LCVO.
Time Lag Aware Sequential Recommendation
Aug 09, 2022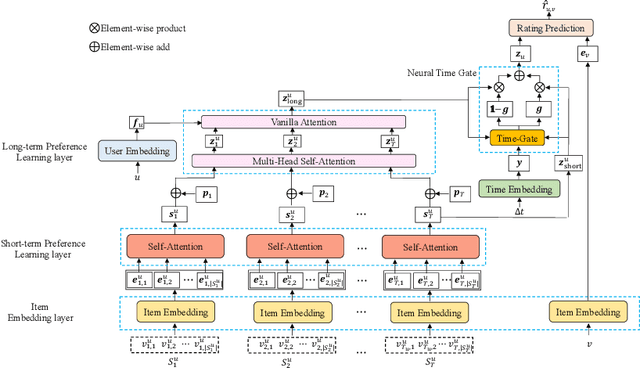

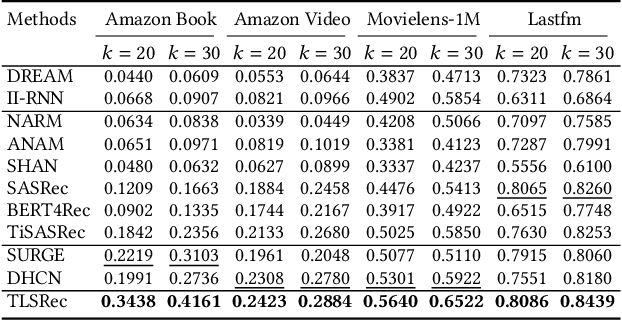
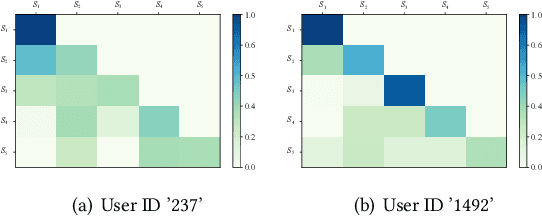
Although a variety of methods have been proposed for sequential recommendation, it is still far from being well solved partly due to two challenges. First, the existing methods often lack the simultaneous consideration of the global stability and local fluctuation of user preference, which might degrade the learning of a user's current preference. Second, the existing methods often use a scalar based weighting schema to fuse the long-term and short-term preferences, which is too coarse to learn an expressive embedding of current preference. To address the two challenges, we propose a novel model called Time Lag aware Sequential Recommendation (TLSRec), which integrates a hierarchical modeling of user preference and a time lag sensitive fine-grained fusion of the long-term and short-term preferences. TLSRec employs a hierarchical self-attention network to learn users' preference at both global and local time scales, and a neural time gate to adaptively regulate the contributions of the long-term and short-term preferences for the learning of a user's current preference at the aspect level and based on the lag between the current time and the time of the last behavior of a user. The extensive experiments conducted on real datasets verify the effectiveness of TLSRec.
Polymers for Extreme Conditions Designed Using Syntax-Directed Variational Autoencoders
Nov 04, 2020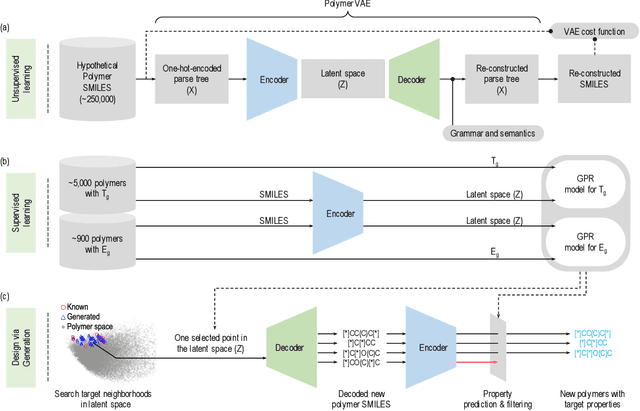

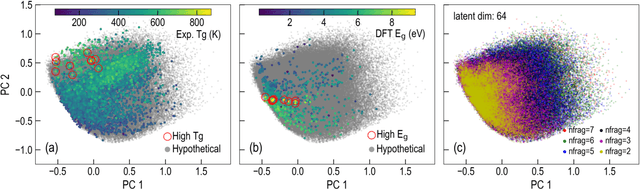
The design/discovery of new materials is highly non-trivial owing to the near-infinite possibilities of material candidates, and multiple required property/performance objectives. Thus, machine learning tools are now commonly employed to virtually screen material candidates with desired properties by learning a theoretical mapping from material-to-property space, referred to as the \emph{forward} problem. However, this approach is inefficient, and severely constrained by the candidates that human imagination can conceive. Thus, in this work on polymers, we tackle the materials discovery challenge by solving the \emph{inverse} problem: directly generating candidates that satisfy desired property/performance objectives. We utilize syntax-directed variational autoencoders (VAE) in tandem with Gaussian process regression (GPR) models to discover polymers expected to be robust under three extreme conditions: (1) high temperatures, (2) high electric field, and (3) high temperature \emph{and} high electric field, useful for critical structural, electrical and energy storage applications. This approach to learn from (and augment) human ingenuity is general, and can be extended to discover polymers with other targeted properties and performance measures.
Polymer Informatics: Current Status and Critical Next Steps
Nov 01, 2020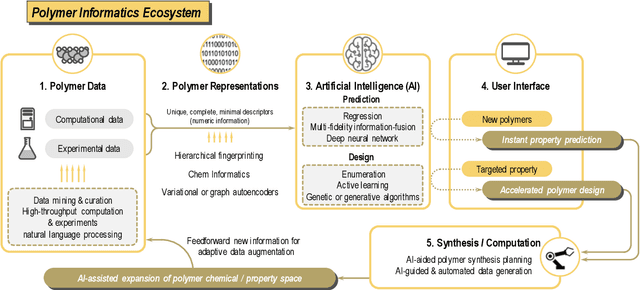

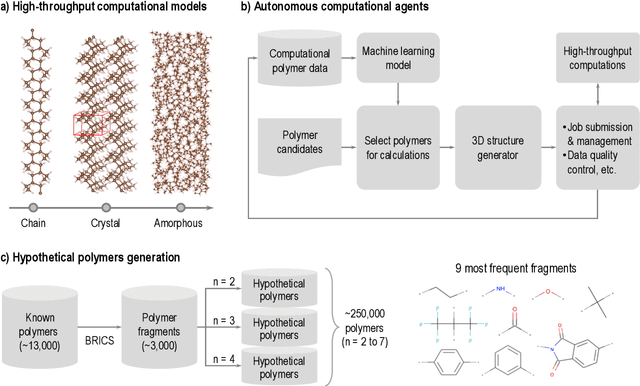

Artificial intelligence (AI) based approaches are beginning to impact several domains of human life, science and technology. Polymer informatics is one such domain where AI and machine learning (ML) tools are being used in the efficient development, design and discovery of polymers. Surrogate models are trained on available polymer data for instant property prediction, allowing screening of promising polymer candidates with specific target property requirements. Questions regarding synthesizability, and potential (retro)synthesis steps to create a target polymer, are being explored using statistical means. Data-driven strategies to tackle unique challenges resulting from the extraordinary chemical and physical diversity of polymers at small and large scales are being explored. Other major hurdles for polymer informatics are the lack of widespread availability of curated and organized data, and approaches to create machine-readable representations that capture not just the structure of complex polymeric situations but also synthesis and processing conditions. Methods to solve inverse problems, wherein polymer recommendations are made using advanced AI algorithms that meet application targets, are being investigated. As various parts of the burgeoning polymer informatics ecosystem mature and become integrated, efficiency improvements, accelerated discoveries and increased productivity can result. Here, we review emergent components of this polymer informatics ecosystem and discuss imminent challenges and opportunities.
Polymer Informatics with Multi-Task Learning
Oct 28, 2020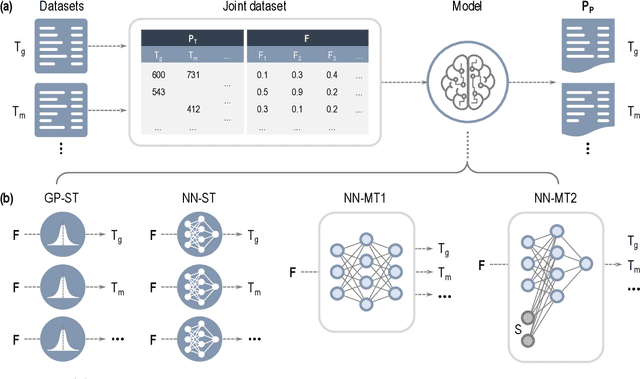
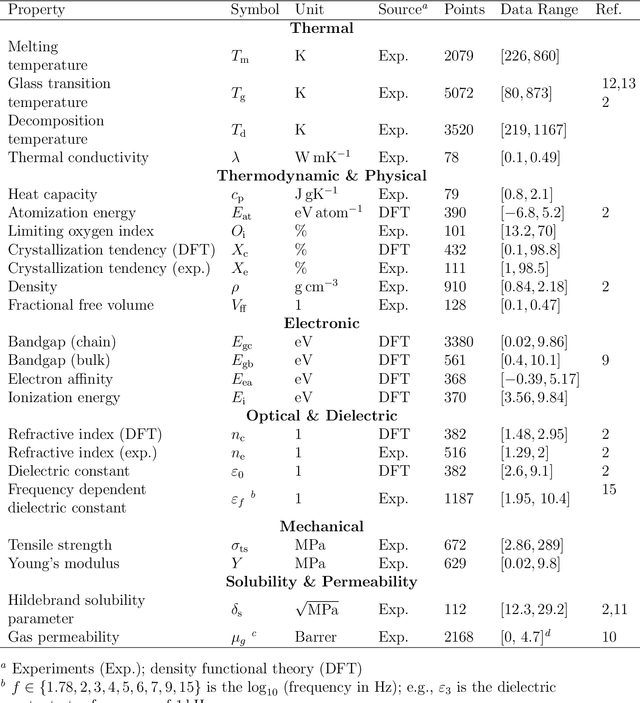
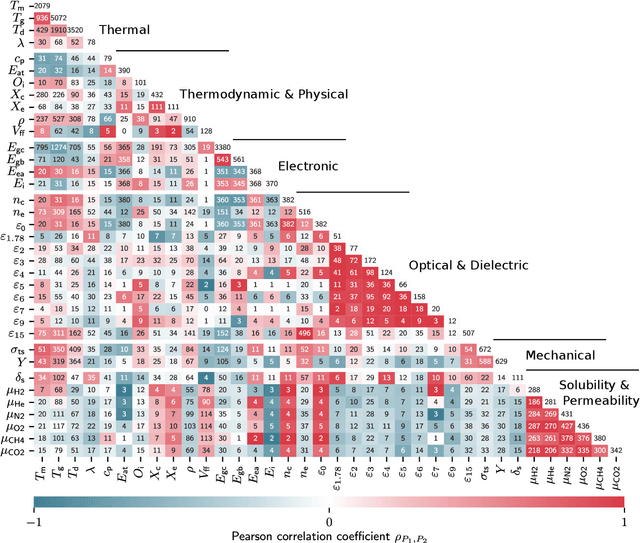
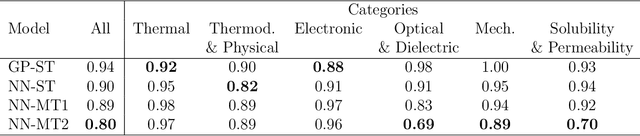
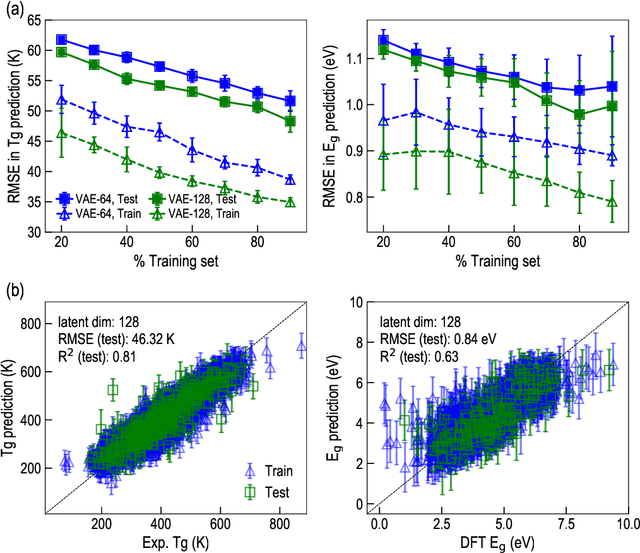
Modern data-driven tools are transforming application-specific polymer development cycles. Surrogate models that can be trained to predict the properties of new polymers are becoming commonplace. Nevertheless, these models do not utilize the full breadth of the knowledge available in datasets, which are oftentimes sparse; inherent correlations between different property datasets are disregarded. Here, we demonstrate the potency of multi-task learning approaches that exploit such inherent correlations effectively, particularly when some property dataset sizes are small. Data pertaining to 36 different properties of over $13, 000$ polymers (corresponding to over $23,000$ data points) are coalesced and supplied to deep-learning multi-task architectures. Compared to conventional single-task learning models (that are trained on individual property datasets independently), the multi-task approach is accurate, efficient, scalable, and amenable to transfer learning as more data on the same or different properties become available. Moreover, these models are interpretable. Chemical rules, that explain how certain features control trends in specific property values, emerge from the present work, paving the way for the rational design of application specific polymers meeting desired property or performance objectives.
SANTIS: Sampling-Augmented Neural neTwork with Incoherent Structure for MR image reconstruction
Dec 08, 2018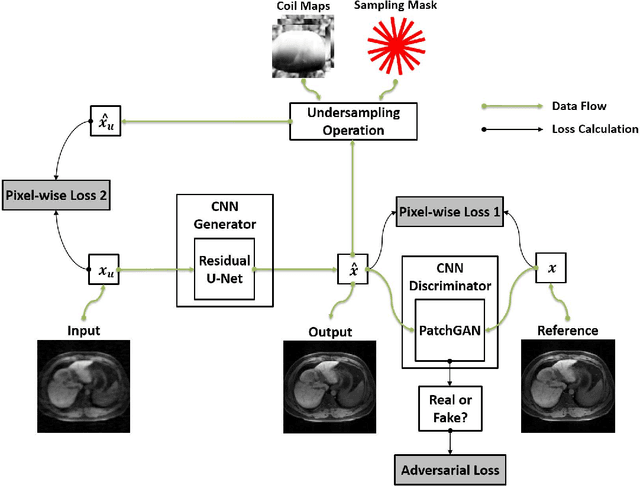
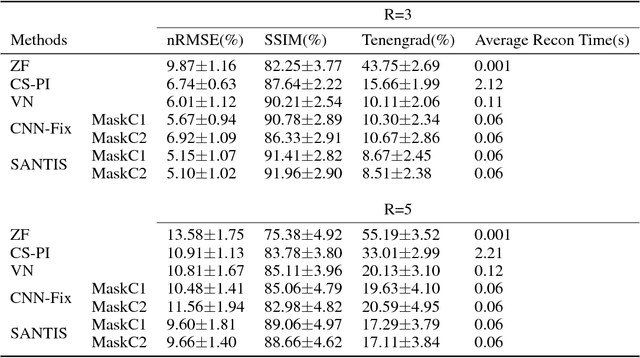
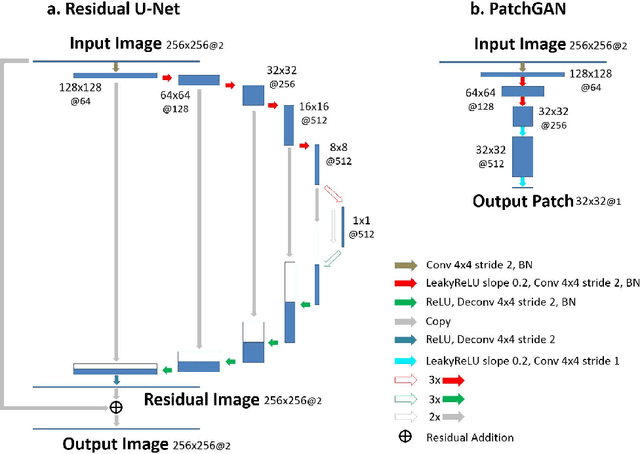
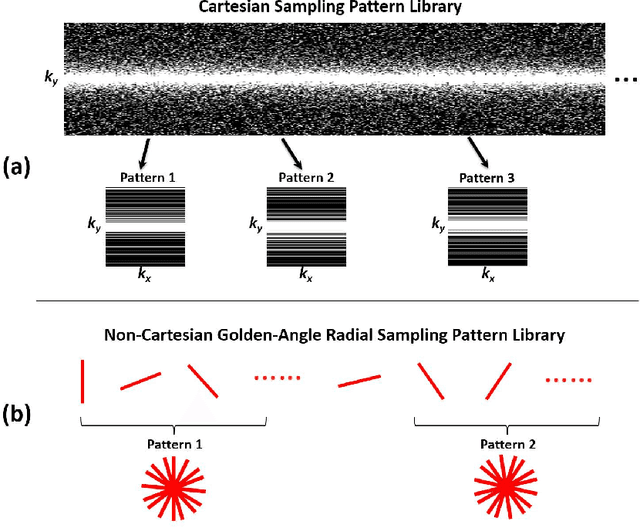
Deep learning holds great promise in the reconstruction of undersampled Magnetic Resonance Imaging (MRI) data, providing new opportunities to escalate the performance of rapid MRI. In existing deep learning-based reconstruction methods, supervised training is performed using artifact-free reference images and their corresponding undersampled pairs. The undersampled images are generated by a fixed undersampling pattern in the training, and the trained network is then applied to reconstruct new images acquired with the same pattern in the inference. While such a training strategy can maintain a favorable reconstruction for a pre-selected undersampling pattern, the robustness of the trained network against any discrepancy of undersampling schemes is typically poor. We developed a novel deep learning-based reconstruction framework called SANTIS for efficient MR image reconstruction with improved robustness against sampling pattern discrepancy. SANTIS uses a data cycle-consistent adversarial network combining efficient end-to-end convolutional neural network mapping, data fidelity enforcement and adversarial training for reconstructing accelerated MR images more faithfully. A training strategy employing sampling augmentation with extensive variation of undersampling patterns was further introduced to promote the robustness of the trained network. Compared to conventional reconstruction and standard deep learning methods, SANTIS achieved consistent better reconstruction performance, with lower errors, greater image sharpness and higher similarity with respect to the reference regardless of the undersampling patterns during inference. This novel concept behind SANTIS can particularly be useful towards improving the robustness of deep learning-based image reconstruction against discrepancy between training and evaluation, which is currently an important but less studied open question.