 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Linearizations Are Equally Data-Hungry in Sequence Labeling Parsing
Aug 17, 2021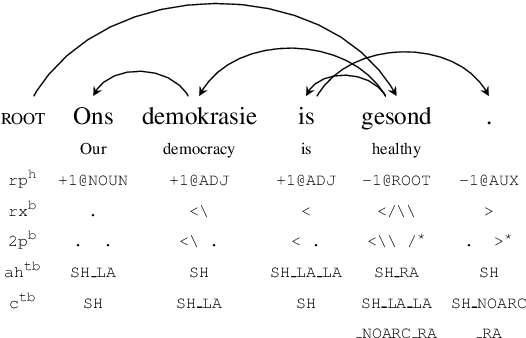



Different linearizations have been proposed to cast dependency parsing as sequence labeling and solve the task as: (i) a head selection problem, (ii) finding a representation of the token arcs as bracket strings, or (iii) associating partial transition sequences of a transition-based parser to words. Yet, there is little understanding about how these linearizations behave in low-resource setups. Here, we first study their data efficiency, simulating data-restricted setups from a diverse set of rich-resource treebanks. Second, we test whether such differences manifest in truly low-resource setups. The results show that head selection encodings are more data-efficient and perform better in an ideal (gold) framework, but that such advantage greatly vanishes in favour of bracketing formats when the running setup resembles a real-world low-resource configuration.
Bracketing Encodings for 2-Planar Dependency Parsing
Nov 01, 2020



We present a bracketing-based encoding that can be used to represent any 2-planar dependency tree over a sentence of length n as a sequence of n labels, hence providing almost total coverage of crossing arcs in sequence labeling parsing. First, we show that existing bracketing encodings for parsing as labeling can only handle a very mild extension of projective trees. Second, we overcome this limitation by taking into account the well-known property of 2-planarity, which is present in the vast majority of dependency syntactic structures in treebanks, i.e., the arcs of a dependency tree can be split into two planes such that arcs in a given plane do not cross. We take advantage of this property to design a method that balances the brackets and that encodes the arcs belonging to each of those planes, allowing for almost unrestricted non-projectivity (round 99.9% coverage) in sequence labeling parsing. The experiments show that our linearizations improve over the accuracy of the original bracketing encoding in highly non-projective treebanks (on average by 0.4 LAS), while achieving a similar speed. Also, they are especially suitable when PoS tags are not used as input parameters to the models.
A Unifying Theory of Transition-based and Sequence Labeling Parsing
Nov 01, 2020



We define a mapping from transition-based parsing algorithms that read sentences from left to right to sequence labeling encodings of syntactic trees. This not only establishes a theoretical relation between transition-based parsing and sequence-labeling parsing, but also provides a method to obtain new encodings for fast and simple sequence labeling parsing from the many existing transition-based parsers for different formalisms. Applying it to dependency parsing, we implement sequence labeling versions of four algorithms, showing that they are learnable and obtain comparable performance to existing encodings.
Parsing as Pretraining
Feb 05, 2020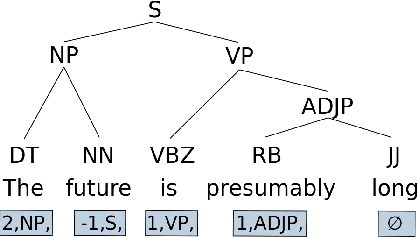
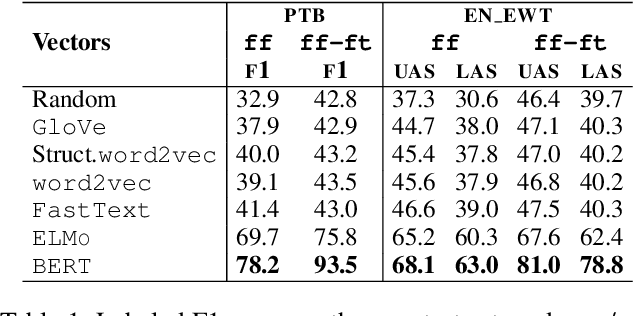
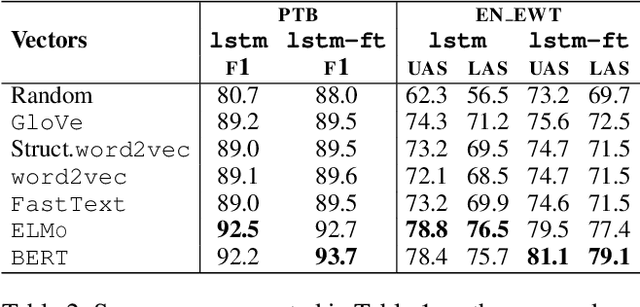
Recent analyses suggest that encoders pretrained for language modeling capture certain morpho-syntactic structure. However, probing frameworks for word vectors still do not report results on standard setups such as constituent and dependency parsing. This paper addresses this problem and does full parsing (on English) relying only on pretraining architectures -- and no decoding. We first cast constituent and dependency parsing as sequence tagging. We then use a single feed-forward layer to directly map word vectors to labels that encode a linearized tree. This is used to: (i) see how far we can reach on syntax modelling with just pretrained encoders, and (ii) shed some light about the syntax-sensitivity of different word vectors (by freezing the weights of the pretraining network during training). For evaluation, we use bracketing F1-score and LAS, and analyze in-depth differences across representations for span lengths and dependency displacements. The overall results surpass existing sequence tagging parsers on the PTB (93.5%) and end-to-end EN-EWT UD (78.8%).
Towards Making a Dependency Parser See
Sep 03, 2019



We explore whether it is possible to leverage eye-tracking data in an RNN dependency parser (for English) when such information is only available during training, i.e., no aggregated or token-level gaze features are used at inference time. To do so, we train a multitask learning model that parses sentences as sequence labeling and leverages gaze features as auxiliary tasks. Our method also learns to train from disjoint datasets, i.e. it can be used to test whether already collected gaze features are useful to improve the performance on new non-gazed annotated treebanks. Accuracy gains are modest but positive, showing the feasibility of the approach. It can serve as a first step towards architectures that can better leverage eye-tracking data or other complementary information available only for training sentences, possibly leading to improvements in syntactic parsing.
Sequence Labeling Parsing by Learning Across Representations
Jul 02, 2019



We use parsing as sequence labeling as a common framework to learn across constituency and dependency syntactic abstractions. To do so, we cast the problem as multitask learning (MTL). First, we show that adding a parsing paradigm as an auxiliary loss consistently improves the performance on the other paradigm. Secondly, we explore an MTL sequence labeling model that parses both representations, at almost no cost in terms of performance and speed. The results across the board show that on average MTL models with auxiliary losses for constituency parsing outperform single-task ones by 1.05 F1 points, and for dependency parsing by 0.62 UAS points.
Speeding Up Natural Language Parsing by Reusing Partial Results
Apr 06, 2019



This paper proposes a novel technique that applies case-based reasoning in order to generate templates for reusable parse tree fragments, based on PoS tags of bigrams and trigrams that demonstrate low variability in their syntactic analyses from prior data. The aim of this approach is to improve the speed of dependency parsers by avoiding redundant calculations. This can be resolved by applying the predefined templates that capture results of previous syntactic analyses and directly assigning the stored structure to a new n-gram that matches one of the templates, instead of parsing a similar text fragment again. The study shows that using a heuristic approach to select and reuse the partial results increases parsing speed by reducing the input length to be processed by a parser. The increase in parsing speed comes at some expense of accuracy. Experiments on English show promising results: the input dimension can be reduced by more than 20% at the cost of less than 3 points of Unlabeled Attachment Score.
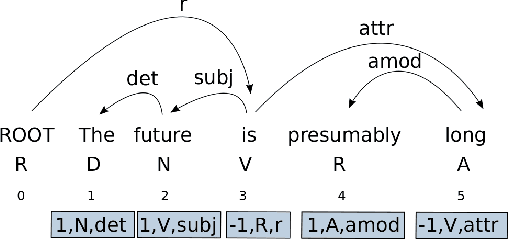
Viable Dependency Parsing as Sequence Labeling
Mar 29, 2019
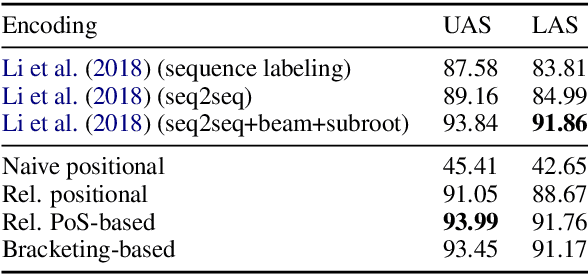

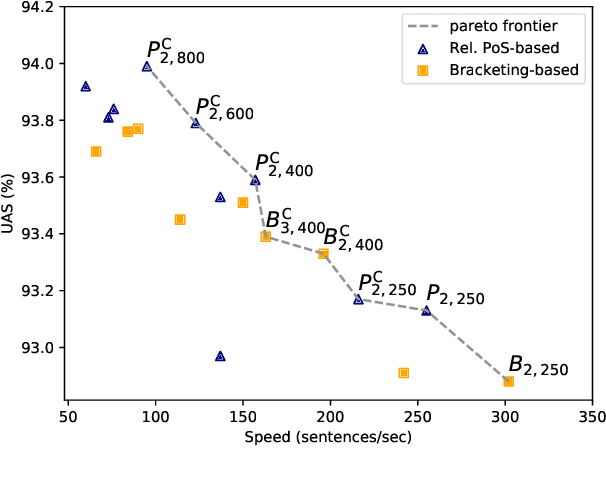
We recast dependency parsing as a sequence labeling problem, exploring several encodings of dependency trees as labels. While dependency parsing by means of sequence labeling had been attempted in existing work, results suggested that the technique was impractical. We show instead that with a conventional BiLSTM-based model it is possible to obtain fast and accurate parsers. These parsers are conceptually simple, not needing traditional parsing algorithms or auxiliary structures. However, experiments on the PTB and a sample of UD treebanks show that they provide a good speed-accuracy tradeoff, with results competitive with more complex approaches.