 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding Up Natural Language Parsing by Reusing Partial Results
Paper and Code
Apr 06, 2019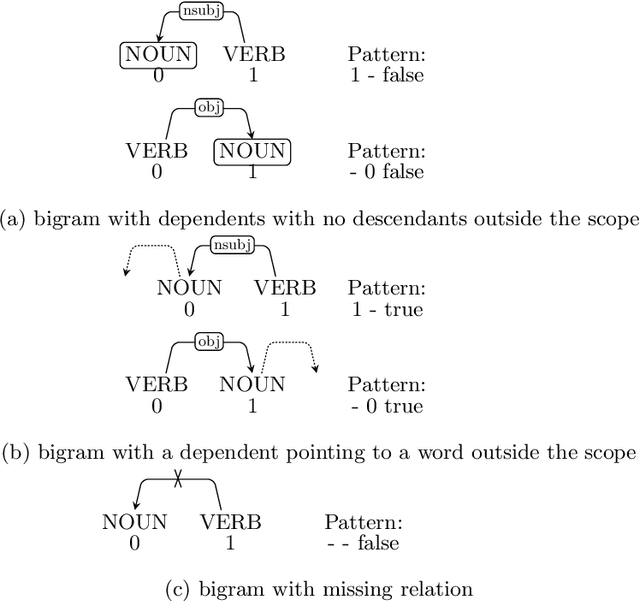



This paper proposes a novel technique that applies case-based reasoning in order to generate templates for reusable parse tree fragments, based on PoS tags of bigrams and trigrams that demonstrate low variability in their syntactic analyses from prior data. The aim of this approach is to improve the speed of dependency parsers by avoiding redundant calculations. This can be resolved by applying the predefined templates that capture results of previous syntactic analyses and directly assigning the stored structure to a new n-gram that matches one of the templates, instead of parsing a similar text fragment again. The study shows that using a heuristic approach to select and reuse the partial results increases parsing speed by reducing the input length to be processed by a parser. The increase in parsing speed comes at some expense of accuracy. Experiments on English show promising results: the input dimension can be reduced by more than 20% at the cost of less than 3 points of Unlabeled Attachment Score.